This paper introduces "Markovian LLM Post-Training," a novel reinforcement learning (RL) framework for Large Language Models that replaces the standard "history-as-state" formulation with explicit Markov states. By leveraging a state transition function—either rule-based or learned—the method allows models to solve complex logic puzzles (Sudoku, Sokoban, Futoshiki) where traditional RL approaches typically hit a performance ceiling.
Executive Summary
TL;DR: Reinforcement Learning for LLMs has long been criticized as a "mere refiner" of pre-trained knowledge rather than a "discovery engine." This paper from UW-Madison identifies the culprit: the History-as-State bottleneck. By reintroducing Explicit Markov States, the researchers demonstrate that LLMs can break through their performance plateaus, achieving massive success in complex logic tasks (like Sokoban and Futoshiki) where standard RL models fail to even start.
Background Positioning: This work is a fundamental rethink of the LLM-RL interface. It moves the field from "Sequence Modeling" back toward "Classical Control Theory," arguing that the Markov property—long central to robotics and game AI like AlphaZero—is the missing ingredient for true LLM discovery.
Problem & Motivation: The "Invisible Leash" of History
In classical RL (e.g., Go or Robotics), the agent sees a compact state (the board or joint positions). In LLM RL, the "state" is every token generated so far.
The Problem:
- Exponential Search Space: As the conversation gets longer, the number of possible "histories" grows exponentially ($|A|^H$), making it statistically impossible for the model to "cover" the optimal solution.
- The Capability Ceiling: Recent theory (Foster et al., 2025) suggests that unless the base model is already quite good, RL will never find a novel solution because it's drowned in the noise of its own history.
The authors hypothesize that the reason AlphaZero could transcend human knowledge while LLMs struggle to do so is exactly this: AlphaZero reasons over states; LLMs reason over histories.
Methodology: Back to Markov
The core innovation is simple yet profound: Markov State Estimation. Instead of the model seeing a growing string of text, it sees a distilled "State" $s_h$.
The Structural Shift
- Old Way (Action-Sequence): Input = $[Prompt, Action_1, Action_2, ..., Action_{h-1}]$
- New Way (Markovian): Input = $s_{h-1} + Action_{h-1} \xrightarrow{P} s_h$
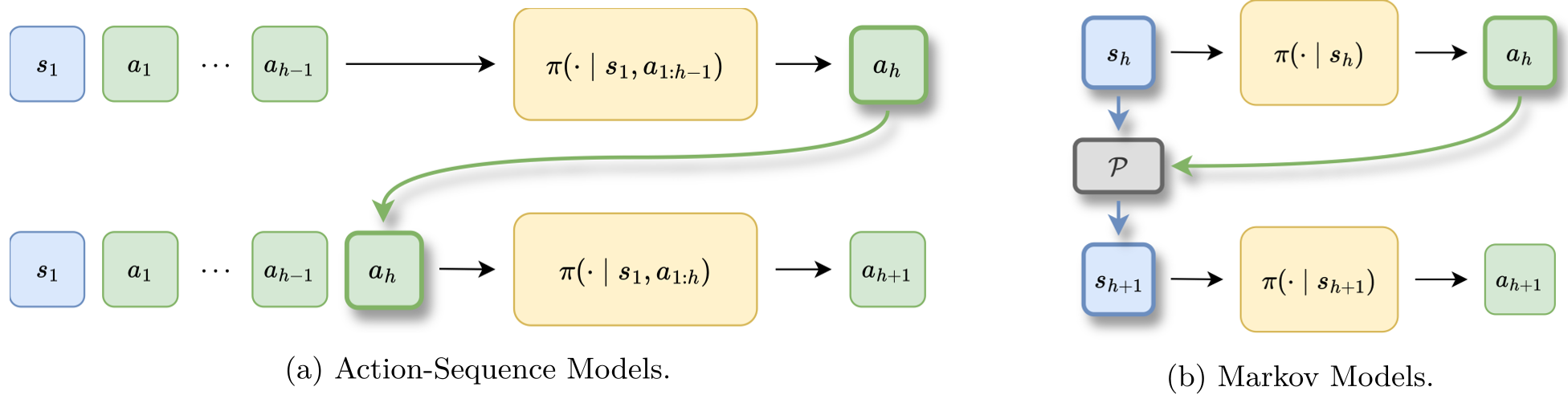
The authors implemented this using an external State Transition Model $\hat{P}$. This model (another, smaller LLM) takes the current board state and an action, then predicts the resulting board. The main policy then conditions only on that board. This effectively offloads "memory" and "state tracking" to the transition model, allowing the RL agent to focus entirely on the Policy (the "what to do next").
Experiments & Results: Breaking the Plateau
The researchers tested this on "Reasoning-Gym" tasks: Sudoku, Sokoban (box-pushing), and Futoshiki.
1. The Performance Jump
On Sokoban, a task requiring deep lookahead and spatial reasoning:
- Traditional Action-Sequence RL: 2.5% Success Rate.
- Markovian RL: 76.1% Success Rate.

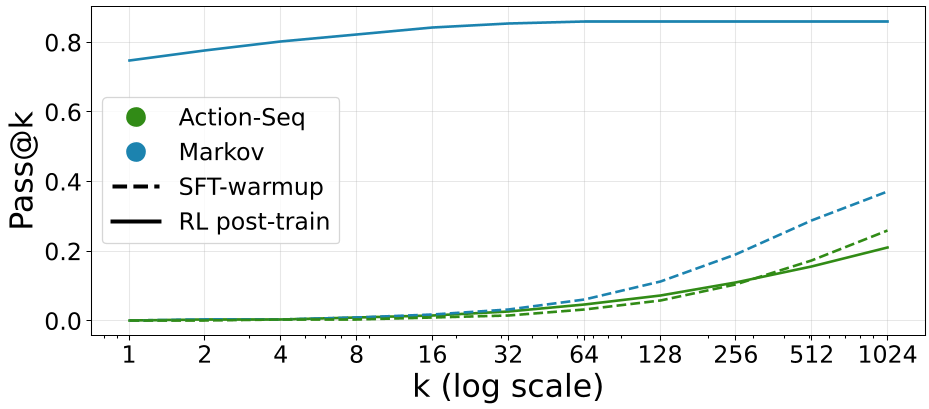
2. Generalization (OOD)
Perhaps the most striking result is the Pass@k scaling. For traditional models, sampling more (larger $k$) doesn't help much once the task gets hard. For Markovian models, the "Capability Ceiling" is shattered—the model finds solutions that were completely unreachable during pre-training or standard SFT.
Deep Insight: Why Does This Work?
The paper provides a rigorous mathematical proof (Propositions 1 & 2). The logic is:
- In Action-Sequence learning, the variance of the learning signal scales with the size of the history tree (exponential).
- In Markovian learning, the variance scales with the size of the state chain (linear).
By "collapsing" all histories that lead to the same state (e.g., in Sudoku, it doesn't matter in what order you filled the previous cells), the agent learns much faster and generalizes better to unseen sequences.
Critical Analysis & Conclusion
Takeaway
This paper is a wake-up call for the LLM community. We've been obsessed with "Context Length" and "Self-Correction history," but the authors argue that less is more. If we can distill the history into a Markov state, we reduce the computational complexity from exponential to polynomial.
Limitations
- State Definition: For games like Sudoku, the state is easy (the grid). For creative writing or open-ended chat, "what is a Markov state?" remains an open research question.
- Transition Model Dependence: The system's success relies on the accuracy of the State Transition model. If the environment is too complex to model, the bias ($\epsilon_{\mathcal{P}}$) might outweigh the gains.
Future Outlook
Expect to see this applied to Agentic Workflows. Instead of an agent looking at its long "Action Log," future agents might look at a "State Summary" (e.g., current file structure in coding, current simplified proof tree in math), leading to the "Open-Ended Discovery" we've seen in systems like AlphaZero.