本文提出了 REA-Coder,一种通过“需求对齐”(Requirement Alignment)增强大语言模型(LLM)代码生成能力的新方法。该方法在 DeepSeek-v3.2 和 GPT-5-mini 等模型及五个基准测试上均达到 SOTA,显著提升了复杂编程任务的成功率。
TL;DR
在自动代码生成领域,即便使用最强的模型如 GPT-5-mini 或 DeepSeek-v3.2,面对复杂的编程竞赛题也常力不从心。本文提出的 REA-Coder 揭示了一个残酷的真相:模型写错代码往往不是因为“脑力(算力)”不足,而是因为从一开始就“看错了题”。通过引入前置 QA 对齐和反向掩码验证,REA-Coder 在多个 benchmark 上大幅超越了传统的推理和修复方法,平均提升幅度最高达 30% 以上。
痛点深挖:被忽视的“理解偏差”
目前的 SOTA 方法(如推理增强 SCoT、反馈修复 Self-Repair)都有一个共同的潜台词:“只要我教模型怎么思考(Reasoning)或者怎么改错(Repair),它就能写出对的代码。”
但作者指出,**需求对齐(Requirement Alignment)**才是房间里的象:
- 理解基础脆弱:如果 LLM 把“重复减去 2b”误解成了“直接减去一次”,后续无论堆砌多少层思维链(CoT),生成的逻辑也是南辕北辙。
- 修复的局限性:基于执行反馈(Compiler Feedback)的修复只能解决语法或简单测试用例错误,无法扭转底层的业务逻辑误解。
 图 1:典型案例显示,由于对循环逻辑的初始误解,常规修复方法均宣告失败,而需求对齐能直接命中痛点。
图 1:典型案例显示,由于对循环逻辑的初始误解,常规修复方法均宣告失败,而需求对齐能直接命中痛点。
核心机制:REA-Coder 的对齐双舞
1. 前置“考卷”:QA 驱动的需求对齐
REA-Coder 不急于让模型写代码。它首先根据需求的 13 个核心维度(如:输入要求、边界情况、算法约束等)生成一张 Question Checklist。
- 自问自答:让模型根据自己对需求的理解回答这些问题。
- 偏差识别:将回答与预设的参考答案(由 LLM 初始分析生成)对比,一旦发现偏差(如模型漏掉了某个约束),立即更新需求描述,形成“校准后的需求”。
2. 后置“盲测”:掩码需求恢复(Masked Recovery)
为了确保生成的代码不仅能运行,还“逻辑忠实”,REA-Coder 创新地引入了类似 NLP 中掩码语言建模的机制:
- 遮盖:随机遮盖需求文档中的关键语义片段(例如具体的计算公式或输出格式)。
- 恢复:要求 LLM 仅根据生成的代码,推断被遮盖的内容。
- 物理意义:如果模型能根据代码反推出需求,说明代码完美体现了需求逻辑;反之则存在 Missing Alignment(对齐缺失)。
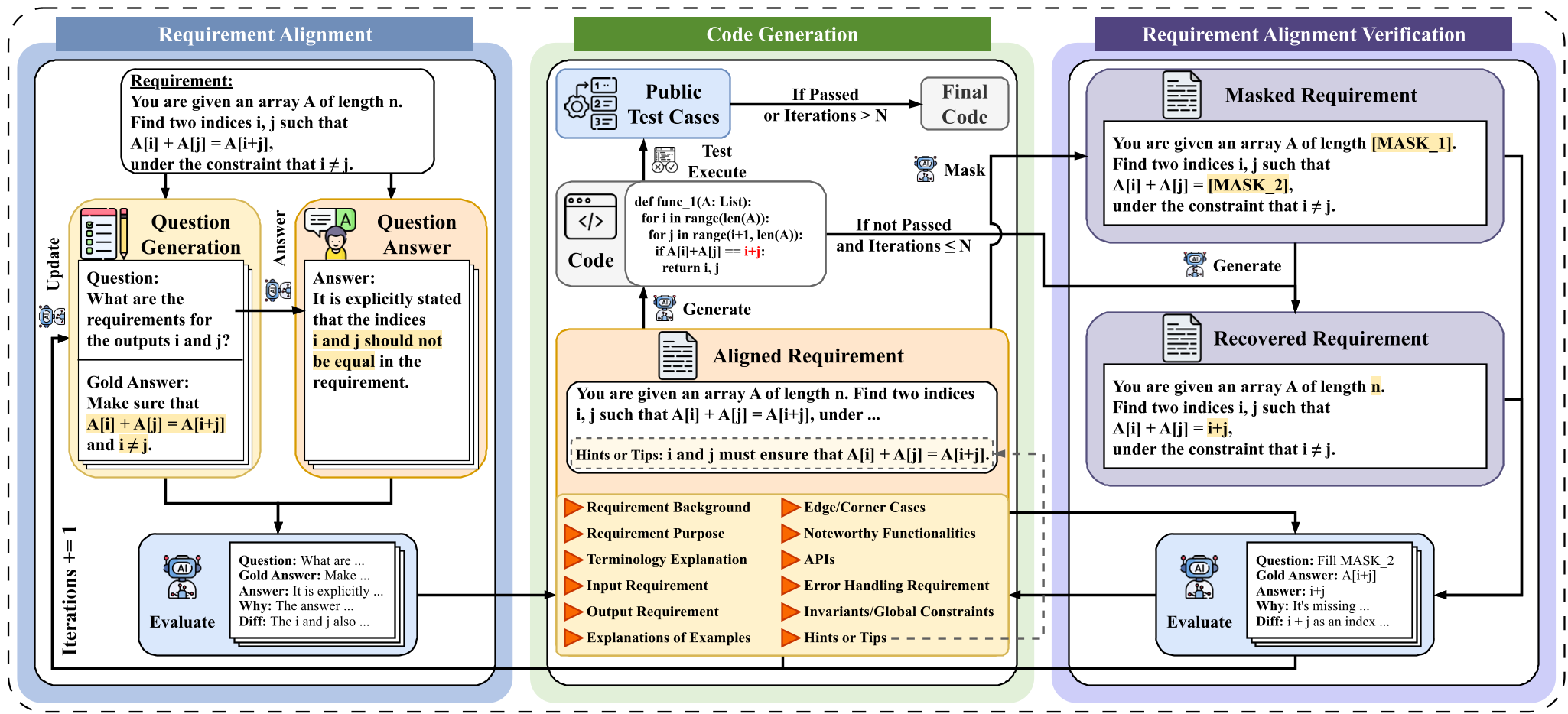 图 2:REA-Coder 的迭代流程:从需求分析、QA 对齐到代码生成与掩码验证。
图 2:REA-Coder 的迭代流程:从需求分析、QA 对齐到代码生成与掩码验证。
实验与结果:全线胜出
1. 战绩摘要
REA-Coder 在 DeepSeek-v3.2, Qwen3-Coder, GPT-5-mini 和 Gemini-3-Flash 四大模型上进行了横向测试。
- 在竞赛级数据集 CodeContests 上,Pass@1 提升最为夸张(达 30.25%)。
- 弱模型效益最大化:Qwen3-Coder 这种模型在对齐后,其编程能力被“深度激活”,在 xCodeEval 上的提升率高达 344%。
2. 消融实验
作者通过移除各个模块验证了设计的合理性:
- QA 模块 vs 掩码模块:实验发现,掩码恢复验证对性能的贡献(下降 9.99%)略高于 QA 对齐(下降 5.82%),这说明“代码 -> 需求”的反向验证能更深层地挖掘逻辑缺陷。
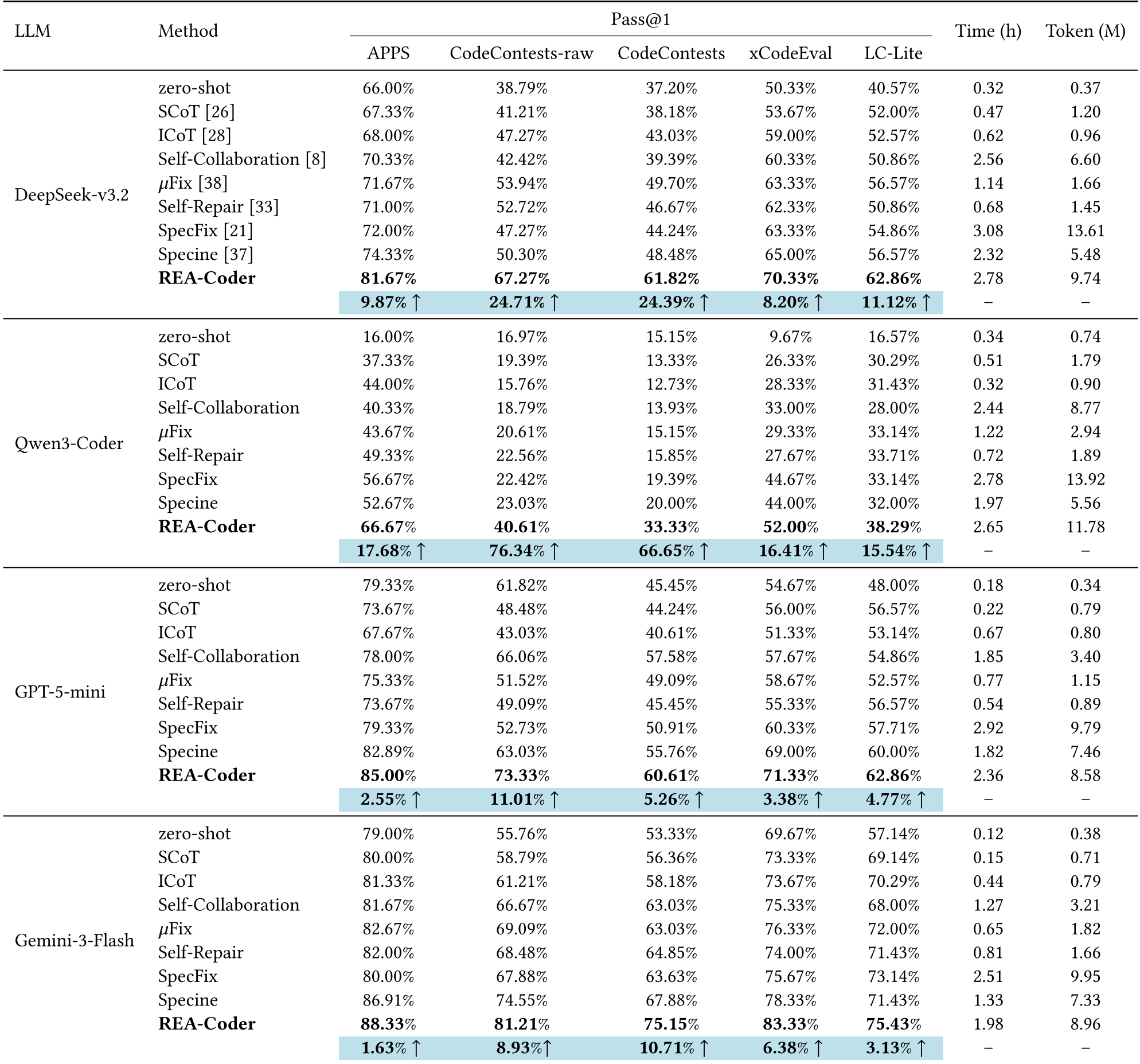 表 1:REA-Coder 与 8 种 SOTA 基线的性能对比,展示了其在全场景下的压制力。
表 1:REA-Coder 与 8 种 SOTA 基线的性能对比,展示了其在全场景下的压制力。
深度洞察:程序员可以从中学到什么?
这项研究给自动化软件工程带来了几点深刻启发:
- “先对齐后编码”是金律:即便在 AI 时代,需求分析(Requirements Engineering)依然是软件质量的核心。
- 解释比范例重要:分析发现,“需求目的(Purpose)”和“范例解析(Explanations of Examples)”这两个维度对模型性能影响最大。给 AI 喂数据时,多解释为什么这么输入比单纯给一组 Input/Output 更有帮助。
- 计算成本的权衡:虽然 REA-Coder 的 Token 消耗高于推理类方法,但在处理复杂业务逻辑时,这种“多花口舌对需求”的时间成本相比于产生逻辑 Bug 带来的返工代价是微不足道的。
结论
REA-Coder 成功地将传统的**需求工程(Requirements Engineering)**理论引入了 LLM 时代。它通过一种非常“人类化”的方式——即通过反复确认和互相质询——弥补了模型在处理复杂长文本需求时的认知短板。
局限性:尽管目前在短/中篇幅的需求上表现惊艳,但在面对超大规模、跨文档的仓库级(Repo-level)开发时,如何低成本地构建 Question Checklist 仍是未来的研究方向。