本文提出了 Calibri,一种针对 Diffusion Transformer (DiT) 的参数高效校准方法。通过在 DiT 模块中引入极少量的可学习缩放因子(约 10² 个参数)并利用进化策略(CMA-ES)进行黑盒奖励优化,Calibri 在显著提升图像生成质量的同时,将推理步数减少了 50% 以上。
TL;DR
传统的 Diffusion Transformer (DiT) 架构在推理时如同“大锅饭”,无论哪一层都贡献同样的权重。本文提出的 Calibri 揭示了 DiT 内部的结构性浪费:通过给特定层加上一把“精准的标尺”(缩放因子),仅微调约 100 个参数,就能让 FLUX、SD 3.5 等顶尖模型在推理步数减半的情况下,生成质量显著超越原始基线。
1. 痛点:被忽视的“坏层”与昂贵的对齐
在视觉生成领域,DiT 配合 Flow Matching 已成为 SOTA 标准(如 SD3, FLUX)。然而,尽管它们由数百个相同的 Transformer 块堆叠而成,由于 Inductive Bias 的差异,这些块的实际贡献极不均衡。
作者通过消融实验(Ablation Study)发现了一个惊人的事实:
- 冗余性:禁用某些特定的层,图像质量反而会提高。
- 不匹配性:原始模型的输出权重并不是最优的,存在层与层之间的协作冲突。
以往的解决办法是 RLHF 或 DPO,但这需要动辄数千万参数的微调,计算资源消耗极大,且往往导致推理速度变慢。
2. 核心直觉:给 DiT 做一次“全身体检”
Calibri 的核心思路极其纯粹:后验校准(Post-hoc Calibration)。
作者在 DiT 块的残差连接处引入了一个缩放系数 。不需要重新训练模型,而是将这些系数视为待优化的黑盒参数。
架构解析:三种粒度的校准
- Block Scaling:对整个 Transformer 块的所有层统一缩放。
- Layer Scaling:分别对 Attention 和 MLP 层进行独立缩放(最推荐,性能与效率平衡点)。
- Gate Scaling:在多模态 DiT(如 MM-DiT)中,对文本和图像的分支门控进行校准。
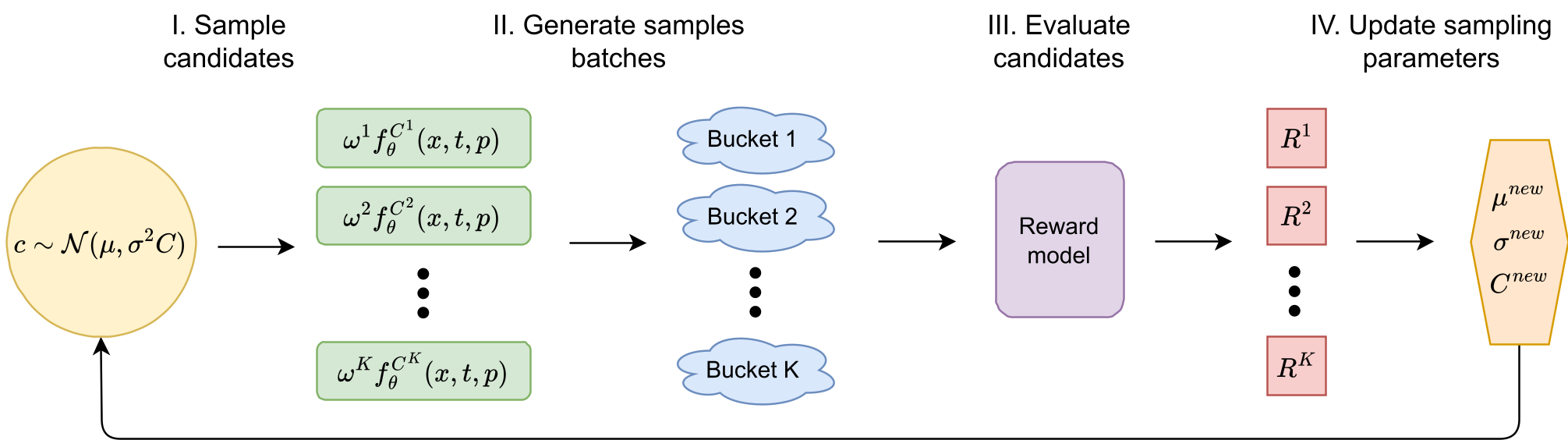 图 1: Calibri 搜索最优校准参数的流程,利用 CMA-ES 进化策略最大化人类偏好得分(Reward)。
图 1: Calibri 搜索最优校准参数的流程,利用 CMA-ES 进化策略最大化人类偏好得分(Reward)。
3. 算法突破:进化策略(CMA-ES)的高效性
传统的梯度优化在 Diffusion 的噪声潜空间中表现挣扎且极耗内存。Calibri 另辟蹊径,采用了 CMA-ES (Covariance Matrix Adaptation Evolution Strategy)。
- 优势:无需梯度,直接根据生成的最终图像质量(Reward Model 评分)进行迭代。
- 效率:在 FLUX 模型上,仅需 200 个迭代即可收敛,相比于强化学习(Flow-GRPO),收敛速度显著领先。
4. 实验战绩:提速与提质的完美结合
作者在 FLUX.1-dev、SD-3.5-Medium 和 Qwen-Image 上进行了全面测试。
| 模型 | 是否使用 Calibri | HPSv3 (画质) | NFE (步数) | | :--- | :--- | :--- | :--- | | FLUX | 否 | 11.41 | 30 | | FLUX | 是 (Calibri) | 13.48 | 15 | | SD-3.5M | 否 | 11.15 | 80 | | SD-3.5M | 是 (Calibri) | 14.10 | 30 |
深度洞察:
- 推理加速:Calibri 改变了模型的收敛轨迹,使得模型在极少的步数(10-15步)下就能达到原始模型 30-50 步都无法企及的画质。
- 参数效率:在 SD-3.5M 上,更新 216 个参数 的效果竟然优于更新 1878 万参数 的对齐算法。
 图 2: 使用 Calibri 后,即便在更少的推理步数下,画面细节和色彩丰富度也得到了肉眼可见的增强。
图 2: 使用 Calibri 后,即便在更少的推理步数下,画面细节和色彩丰富度也得到了肉眼可见的增强。
5. 总结与反思:极简即极致
Calibri 的成功给领域带来了深刻启示:
- 结构不是终点:即便架构训练完成了,其内部权重的相互关系仍有巨大的优化空间。
- 黑盒优化仍有奇效:在参数极少的情况下,进化算法的效率和稳定性超过了复杂的梯度下降对齐。
- 局限性:该方法高度依赖 Reward Model(如 HPSv3)的准确性,如果奖励模型对人体结构(多手指等)不敏感,Calibri 可能会继承这些偏差。
对于未来的开发者而言,Calibri 提供了一套低成本的“补丁方案”,可以在不改动任何核心权重的前提下,让已有模型瞬间获得 SOTA 级的表现。