CAM3R is a camera-agnostic feed-forward framework for dense 3D reconstruction from unposed and uncalibrated images. It outperforms existing foundation models like DUSt3R by explicitly decoupling camera-specific ray estimation from scene geometry, achieving state-of-the-art results across pinhole, fisheye, and panoramic modalities.
TL;DR
Existing 3D vision foundation models like DUSt3R are "trapped" in a pinhole world. When fed with fisheye or 360° panoramic images, they collapse because they assume light travels in a rigid perspective grid. CAM3R solves this by decoupling the camera's optical manifold from the scene's geometry. By learning to "see" along rays rather than fixed pixels, it provides robust, calibration-free 3D reconstruction for virtually any lens type.
The "Pinhole Bias" Problem
Most 3D datasets (like MegaDepth) are perspective-heavy. Consequently, state-of-the-art models learn an implicit Inductive Bias toward pinhole geometry. When these models encounter wide-angle imagery:
- Rectification Artefacts: Traditional "undistorting" stretches pixels aggressively at the edges, losing information.
- Geometric Collapse: Direct regression models entangle lens distortion with depth, leading to warped point clouds where straight walls appear bent.
CAM3R identifies that the fundamental objective isn't just predicting (X, Y, Z), but determining the direction and distance of light for every pixel.
Methodology: The Core of CAM3R
The architecture is elegantly split into two specialized modules that handle the "How" of the camera and the "What" of the scene separately.
1. The Ray Module (RM)
Instead of assuming a camera matrix, the RM learns a continuous ray field. It uses Spherical Harmonic (SH) expansion to output coefficients that define a per-pixel unit vector $d_i(u)$. This allows the model to map pixels to 3D directions for any lens—be it a standard iPhone lens or a 360° RICOH Theta.
2. The Cross-view Module (CVM)
The CVM doesn't waste capacity learning lens distortions. Instead, it focuses on Radial Distance ($r_i$) and relative pose between images. The final 3D point is simply the product: $X(u) = d_i(u) \cdot r_i(u)$.
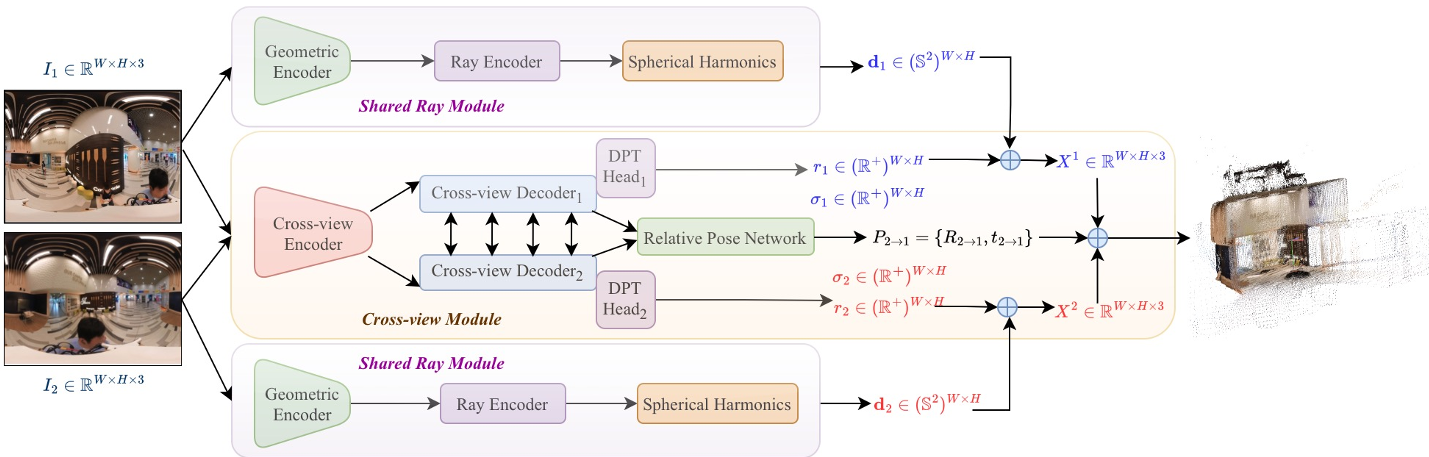 Fig 1: The CAM3R pipeline showing the decoupled Ray and Cross-view modules.
Fig 1: The CAM3R pipeline showing the decoupled Ray and Cross-view modules.
3. Ray-Aware Global Alignment
In multi-view scenarios, standard Bundle Adjustment assumes linear pixel-to-3D mapping. CAM3R introduces a Ray-Aware optimization. During pose refinement, it freezes the predicted ray directions and only optimizes the scale and distance along those rays. This "ray-consistency" prevents the optimizer from corrupting the local geometry when trying to minimize global errors.
Performance: SOTA Across Modalities
The results are most striking when looking at Cross-Modal performance. While models like π³ or DUSt3R perform well on standard pinhole data (MegaDepth), their accuracy falls to near zero on panoramic datasets like 360Loc.
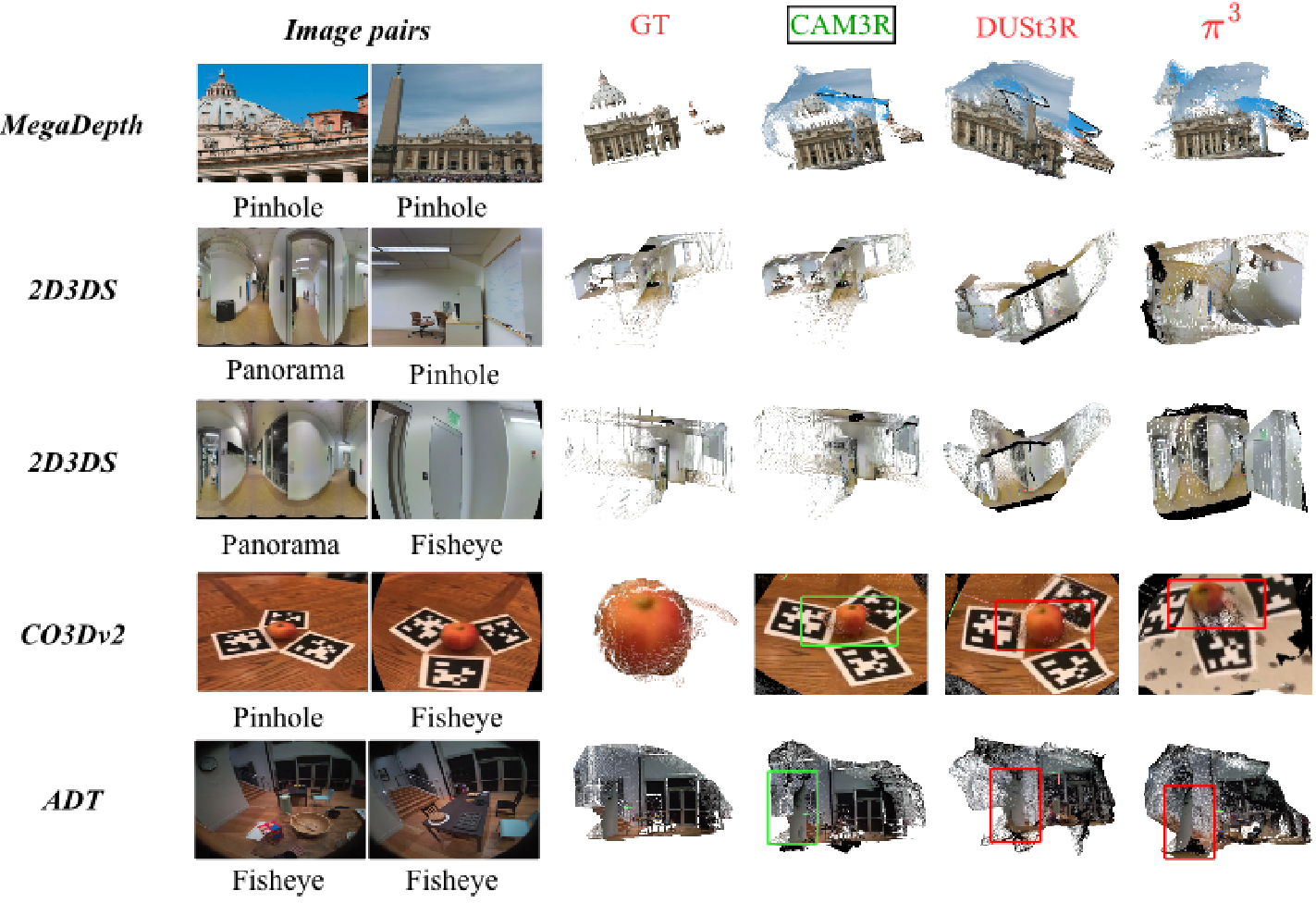 Fig 2: Qualitative comparison showing CAM3R's ability to preserve structural integrity (green) where baselines (red) produce curved, non-physical geometry.
Fig 2: Qualitative comparison showing CAM3R's ability to preserve structural integrity (green) where baselines (red) produce curved, non-physical geometry.
| Dataset | Model | RRA@15 (Rotation Accuracy) | RTA@15 (Translation Accuracy) | | :--- | :--- | :---: | :---: | | 2D3DS (Panorama) | DUSt3R | 10.6% | 6.0% | | | CAM3R | 97.7% | 94.3% | | CO3Dv2 (Zero-Shot)| DUSt3R | 94.7% | 43.1% | | | CAM3R | 97.5% | 88.2% |
Critical Insight & Future Outlook
The primary contribution of CAM3R is the proof that decoupling is better than entanglement. By forcing the network to learn a "Ray-Field" explicitly, the authors have created a model that is truly "Sensor-Agnostic."
Limitations:
- The dual-ViT backbone setup is computationally expensive (high VRAM usage).
- $O(N^2)$ pairwise checks for the scene graph limit scalability to thousands of images.
Future Directions: The authors suggest unifying the encoders to improve speed and exploring advanced positional encodings to capture higher-frequency details in wide-angle scenes. CAM3R effectively sets a new standard for 3D reconstruction in robotics and egocentric vision, where fisheye lenses are the norm, not the exception.
Conclusion
CAM3R marks the end of the "Pinhole Era" for 3D foundation models. By leveraging ray-based representations and decoupled supervision, it enables high-fidelity 3D reconstruction from any camera, anywhere, without the need for prior calibration or pose information.