本文提出了一个通过学习参数化视角 Token(Viewpoint Tokens)实现精确相机控制的文本到图像(T2I)生成框架。该方法通过在包含 3D 渲染几何监督和光影增强图像的混合数据集上微调,实现了对方位角、仰角、半径、俯仰角和偏航角等 5 个参数的精细控制,在保持图像质量的同时达到了 SOTA 级别的相机指向精度。
TL;DR
虽然 DALL-E 3 或 Midjourney 能生成惊艳的图像,但在面对“从后方三刻度视角、仰角 10 度看这辆车”这类精确几何指令时,它们往往会“翻车”。加州大学欧文分校的研究团队提出了一种全新的视角 Token(Viewpoint Tokens)机制,通过将相机参数直接编码进文本嵌入空间,让模型能够像专业摄影师一样通过 5 参数(方位角、仰角、距离、俯仰、偏航)精确控制成像角度。
痛点深挖:为什么模型总是“正对着你”?
现有的文本生成图像模型在解析几何指令时主要面临三大挑战:
- 语言歧义性:简单的“左侧视角”对模型来说是一个模糊的分布,而非确切的弧度值。
- 数据偏差:互联网上的图片大多是“证件照”式的正视角或眼平视高(Eye-level),导致模型对极端角度(如俯角、背部视角)缺乏认知。
- 解耦难题:以前的方法(如 Compass Control)虽然引入了方位角控制,但往往将物体外观与视角深度耦合。如果你让它生成一个没见过的“圣诞老人”侧脸,它可能会因为没见过侧面的圣诞老人而直接生成一只侧面的“狮子”。
核心方法论:5 参数相机编码与双元数据策略
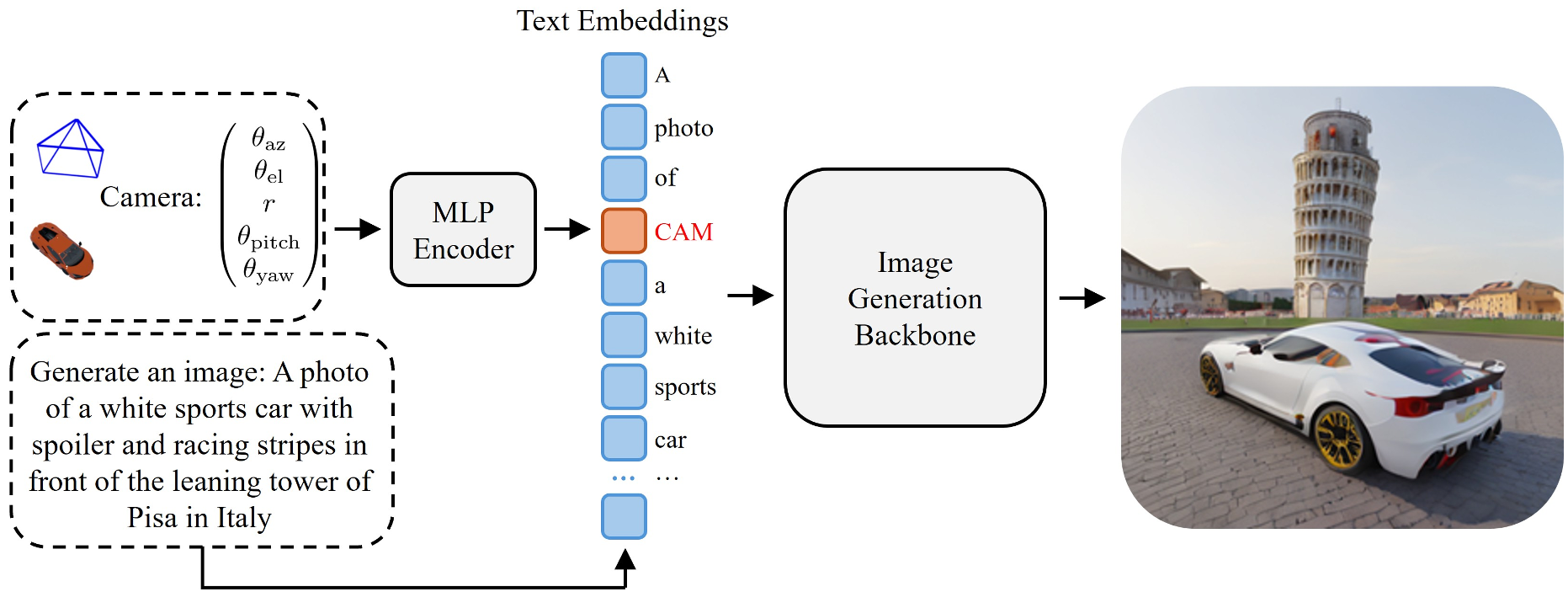
1. 架构解析:将相机变成一个“Token”
研究者没有使用复杂的物理引擎或深度图(Depth map)作为输入,而是采用了一种更轻量化的方案:
- 参数化表示:定义 $ heta = ( heta_{az}, heta_{el}, r, heta_{pitch}, heta_{yaw})$。
- MLP 编码器:使用一个微型 3 层 MLP 将这些连续数值映射为与文本 Embedding 维度一致的特征向量。
- 融合机制:这个“视角 Token”被直接插在物体描述文本之后(例如:
"A red car [VIEW_TOKEN] in the snow"),让 Transformer 的注意力机制能自动处理几何信息。
2. 数据驱动:几何监督与真实感的平衡
如果只用 3D 渲染图训练,生成出来的图会像过时的 CG;如果只用真实图片,几何精度又不够。作者设计了双元数据集(Two-part Dataset):
- 渲染子集:来自 TexVerse 的 3100 多个 3D 模型,提供分度极其精细的几何基准。
- 增强子集:利用 Gemini (Nano Banana) 对渲染图进行背景和纹理的“洗白”处理,在保留原始几何姿态的同时,加入真实光影和背景,防止模型退化。
实验与结果:全方位的跨越
几何精度与泛化性
在方位角测试中,该方法相比之前的 SOTA 方案错误率降低了近 40%。最令人惊叹的是它的跨类别泛化能力。如图 4 所示,面对训练集中从未出现的“高达(Gundam)”、“凤凰”或“圣诞老人”,模型依然能准确执行背部视角或高俯瞰角,而对比方法则出现了严重的过拟合现象(例如把圣诞老人强行扭成了鞋子或泰迪熊)。

高角度挑战
在极具挑战性的 45° 仰角场景下,由于该方法在训练中引入了背景感知,生成的物体能与背景保持连贯的透视关系,而非简单的平移缩放。

深度洞察:为什么这种做法有效?
之所以这种“简单的 MLP 编码”比复杂的“Plücker 射线”或“旋转矩阵”更有效,是因为论文抓住了 T2I 模型的核心——语义嵌入空间。对于 Transformer 来说,学习解析一个具有语义含义的“方位-旋转”信号,比通过物理一致性强行回归相机参数要容易得多。
总结与局限
Takeaway: 本文成功展示了如何将显式的 3D 相机结构“缝合”进现有的 T2I 模型。这不仅仅是控制了视角,更是为未来的“生成式虚拟相机摄影”奠定了基础。
局限性:
- 偏置依然存在:在面对如“泰姬陵”等著名地标时,模型自带的“正面强偏置”有时会覆盖视角 Token。
- 参数限制:目前的实验范围主要局限在 0°-45° 仰角,且未涉及相机焦距和 Roll 角的控制。
这篇论文标志着 T2I 模型正在从“语义可控”向“物理几何可控”迈进,未来的创作者可能不再需要寻找合适的底图,只需输入一组相机坐标,AI 就能给出理想的构图。