ProgramBench is a novel benchmark designed to evaluate Software Engineering (SWE) agents on their ability to rebuild complex software projects from scratch. It utilizes a reference executable and its documentation as the sole input, measuring success through agent-driven behavioral fuzzing.
TL;DR
Meta and Stanford researchers have just released ProgramBench, a benchmark that asks a deceptively simple question: Can an AI build a complex software project (like SQLite or FFmpeg) from scratch, given only the compiled binary and documentation? The answer is a resounding no. Despite being able to fix bugs in existing code, today's best models (including Claude 3.5/4 and GPT-5 class models) fail to fully rebuild even a single project in this benchmark, revealing a massive gap in AI's architectural reasoning.
The Architectural Blind Spot
The current state of AI coding evaluation is dominated by "fill-in-the-blank" tasks. Benchmarks like SWE-bench provide the model with a massive existing codebase and ask it to hunt down a bug. While difficult, this doesn't test Software Design.
The authors of ProgramBench argue that the most critical decisions a human developer makes happen before the first line of code is written:
- Which language and build system?
- How should we modularize the logic?
- What communication protocols should exist between modules?
By stripping away the source code and leaving only an "opaque oracle" (the executable), ProgramBench forces models to act like reverse engineers and architects simultaneously.
Methodology: Probing the Opaque Oracle
The core innovation of ProgramBench is its implementation-agnostic evaluation. Instead of checking if the model's code looks like the original, it checks if it acts like it.
- Reference Executables: 200 tasks spanning CLI tools to the PHP interpreter.
- Behavioral Fuzzing: A SWE-agent executes the reference binary with thousands of inputs to "discover" the specification.
- Assertion Quality: A specialized linter prevents "weak" tests (like only checking if a program didn't crash).

Results: A Reality Check for Autonomy
The results prove that we are far from fully autonomous software engineers. While models make "meaningful partial progress," the technical debt they incur is massive.
| Metric | Claude Opus 4.7 | GPT-5.4 | | :--- | :--- | :--- | | % Resolved | 0.0% | 0.0% | | % Passing 95%+ Tests | 3.0% | 0.0% | | Function Count (vs Ref) | 0.29x | 0.10x |
The "Monolith" Bias
One of the most fascinating findings is the structural divergence. LLMs hate modularity. Even when they manage to pass tests, they tend to write "monolithic" codebases—shoving high-complexity logic into a single giant file with a handul of long functions. Humans write modular, shallow functions for maintainability; AI writes concentrated logic blocks.
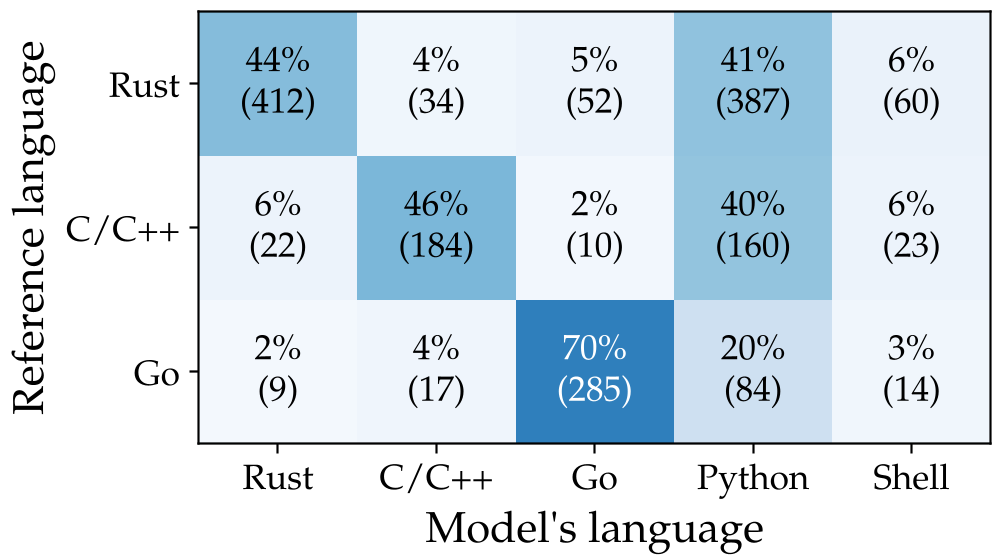
Note: Models default to Python 36% of the time, even when the original task (like a database or media codec) drastically benefits from lower-level languages like C or Rust.
Deep Insight: Discovering Specifications
ProgramBench isn't just a coding test; it's a reasoning test. The model must decide which "questions" to ask the binary.
- "If I pass flag
-y, what happens to the output?" - "How does the system handle corrupted input?"
The authors found that GPT-family models tend to be "concise" (10-14 steps), while Claude-family models are "exploratory" (400+ steps). However, even the most talkative agents frequently hit a wall when the logic requires deep state-machine understanding.
Conclusion & Future Outlook
ProgramBench shifts the goalposts for AI coding. It proves that while LLMs are excellent editors, they are mediocre architects. For AI to reach the level of a Senior SWE, it must move beyond single-file generation and learn the art of system decomposition.
As a takeaway for the industry: If you are building AI agents for software development, the bottleneck isn't the "code writing"—it's the iterative write-compile-debug cycle and the ability to discover requirements from a living system.
For more details, visit the ProgramBench GitHub repository.