The paper introduces CanViT, the first task- and policy-agnostic Active-Vision Foundation Model (AVFM). It utilizes a dual-stream architecture with a retinotopic ViT backbone and a spatiotopic "canvas" memory, achieving SOTA results on active semantic segmentation (45.9% mIoU on ADE20K) while being significantly more efficient than prior models.
TL;DR
CanViT is the first Active-Vision Foundation Model (AVFM) that treats vision as a sequential process of "glimpses" rather than static frame processing. By introducing a persistent spatial canvas and an asymmetric Canvas Attention mechanism, it achieves 45.9% mIoU on ADE20K segmentation—shattering previous active-vision records while using nearly 20x fewer computational resources than its predecessors.
Problem & Motivation: The Passive Vision Bottleneck
Modern AI is dominated by "passive" vision: feed a high-resolution image into a transformer, and get a prediction. While effective, this is biologically implausible and computationally wasteful for high-resolution or long-horizon tasks.
Existing Active Computer Vision (ACV) models tried to fix this by using "glimpses" (crops), but they faced a fundamental scaling wall. Previous SOTA methods like AME and AdaGlimpse re-encoded all previous glimpses at every step, leading to $\mathcal{O}(T^2)$ or even $\mathcal{O}(T^3)$ complexity. More importantly, these models were often "task-specific," tied to individual labels or complex Reinforcement Learning (RL) policies that hindered their use as foundation models.
Methodology: The Canvas and the Backbone
CanViT’s core innovation is the decoupling of processing and memory.
1. Dual-Stream Architecture
- The Backbone (Processing): A standard ViT-B that processes small, ephemeral glimpses (e.g., 128x128 px).
- The Canvas (Memory): A persistent, scene-wide latent grid that acts as a "cognitive map."
- Scene-Relative RoPE (SR-RoPE): Both streams are bound by a shared coordinate system ($[-1, +1]^2$), allowing the model to know exactly where a zoomed-in glimpse sits within the global scene.
2. Canvas Attention (The Efficiency Secret)
To keep the canvas high-resolution without exploding FLOPs, the authors designed Canvas Attention. In typical cross-attention, both Query (Q) and Key/Value (KV) sides have expensive linear projections. CanViT restricts all projections to the backbone side.
The math is simple but powerful: by eliminating canvas-side projections, the overhead of interacting with 1,000+ memory tokens becomes negligible compared to the backbone's self-attention.
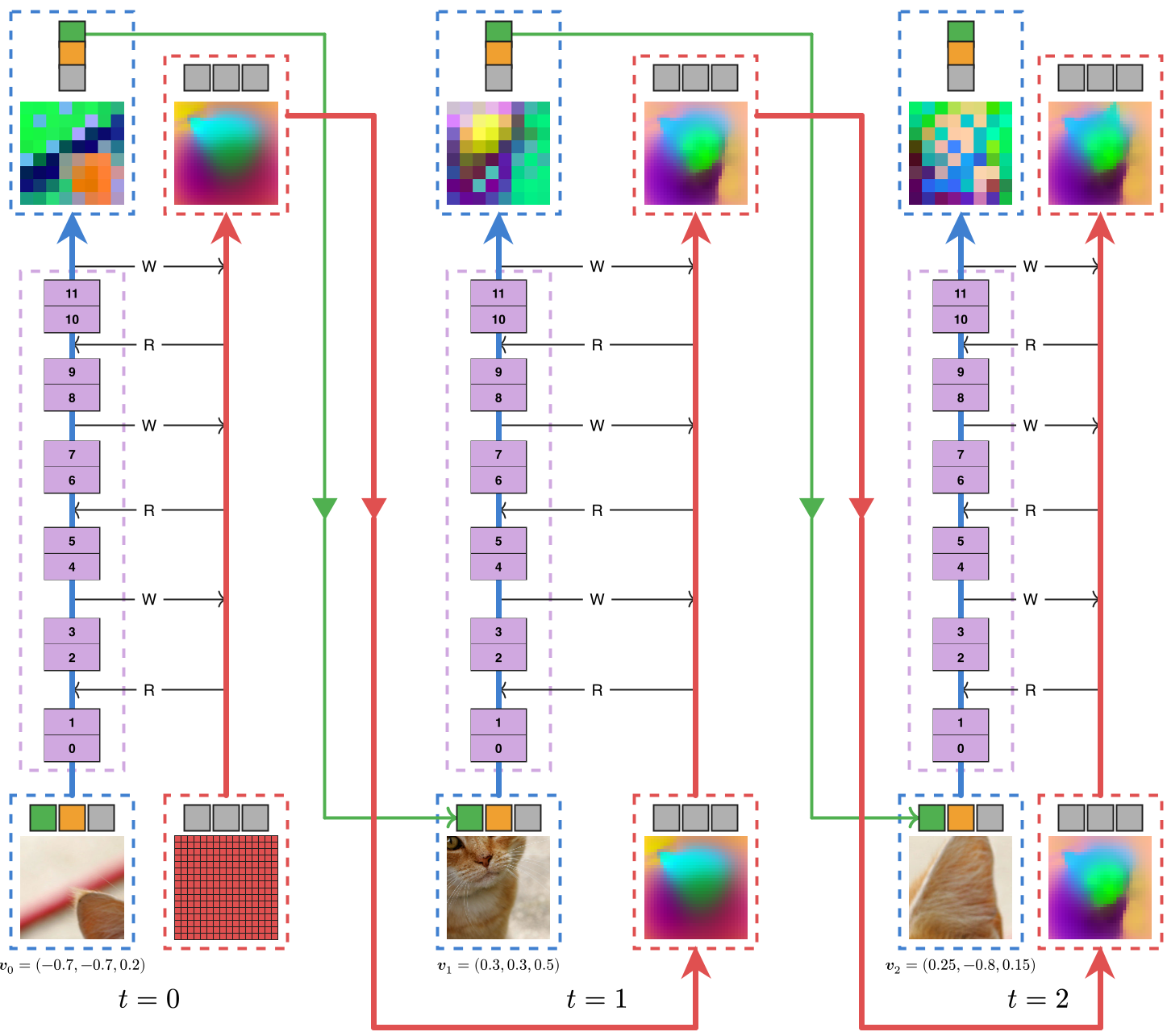
3. Passive-to-Active Distillation
Instead of training on labels (which are scarce for active vision), CanViT learns to mimic DINOv3. It is tasked with reconstructing the high-resolution, global feature maps of a frozen DINOv3 teacher using only a sequence of random, low-resolution glimpses. This forces the model to learn extrapolation—predicting what parts of the scene look like before it has even "looked" at them.
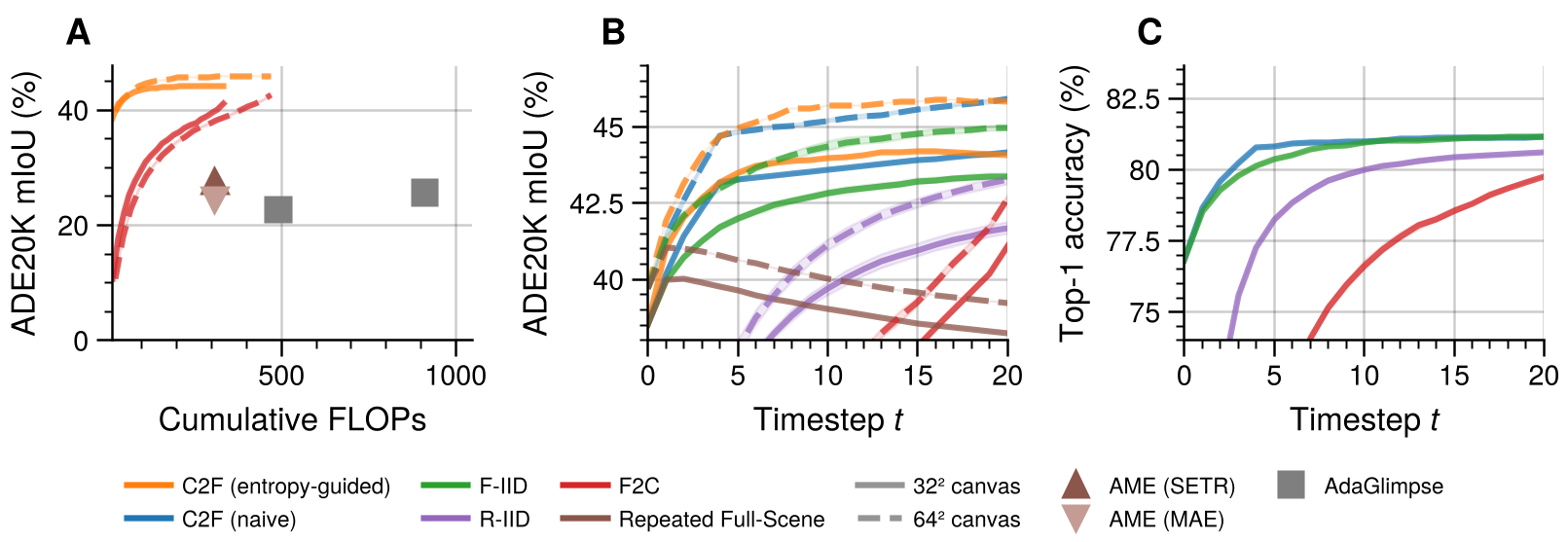
Experiments & Results: Shifting the Frontier
The results on ADE20K semantic segmentation are the most telling.
- Accuracy: CanViT-B achieves 38.5% mIoU in one glimpse, rising to 45.9% with more views.
- Efficiency: It outperforms the previous SOTA (AME) which only reached 27.6% mIoU despite using massive amounts of compute.
- Policy Agnosticism: Even with "Fine-to-Coarse" (a deliberately bad policy), CanViT still beats prior models, proving that the architecture, not the search strategy, was the missing link.
Inference Latency
On an RTX 4090, CanViT maintains ~2.4ms per forward pass even as the virtual scene resolution grows, whereas standard ViTs (like DINOv3) grow quadratically, reaching 93ms at high resolutions. This makes CanViT a prime candidate for real-time robotics.
Critical Analysis & Conclusion
CanViT effectively "solves" the architectural scaling problem for active vision. By showing that latent distillation from passive models works for active ones, it opens the door for Active-Vision Foundation Models.
Limitations:
- The model currently relies on a passive teacher (DINOv3).
- It has been tested primarily on static images; its performance in highly dynamic temporal environments (video) remains an open question for future "Embodied CanViT" versions.
Takeaway: If you want efficient, high-resolution scene understanding, stop looking at the whole image at once. Use a canvas.