CaP-X is an open-access framework for benchmarking and improving "Code-as-Policy" agents in robot manipulation. It introduces CaP-Gym (a hierarchical REPL environment) and CaP-Bench, achieving human-level reliability through a training-free agent called CaP-Agent0 and a reinforcement learning approach called CaP-RL.
TL;DR
Common robotic foundation models (VLAs) are great at "feeling" their way through tasks but terrible at reasoning. CaP-X flips the script by treating robot control as a software engineering problem. By using LLMs to write code that interacts with low-level robot APIs, and augmenting them with "test-time compute" (debugging and ensembles), the researchers achieve human-level reliability without the need for massive imitation datasets.
The Problem: The "Cheating" of High-Level Primitives
Previous "Code-as-Policy" (CaP) works were impressive but often "cheated" by providing the AI with powerful, hand-written functions like pick_and_place_container(). This over-engineering masked the AI's inability to handle the messy reality of low-level control.
CaP-X investigates what happens when you take away the training wheels. They found a Generality Ceiling: as you move from high-level macros (S1/S2 tiers) to low-level atomic APIs (S3/S4 tiers), performance usually plummets. The challenge is: Can an AI agent synthesize its own abstractions from scratch?
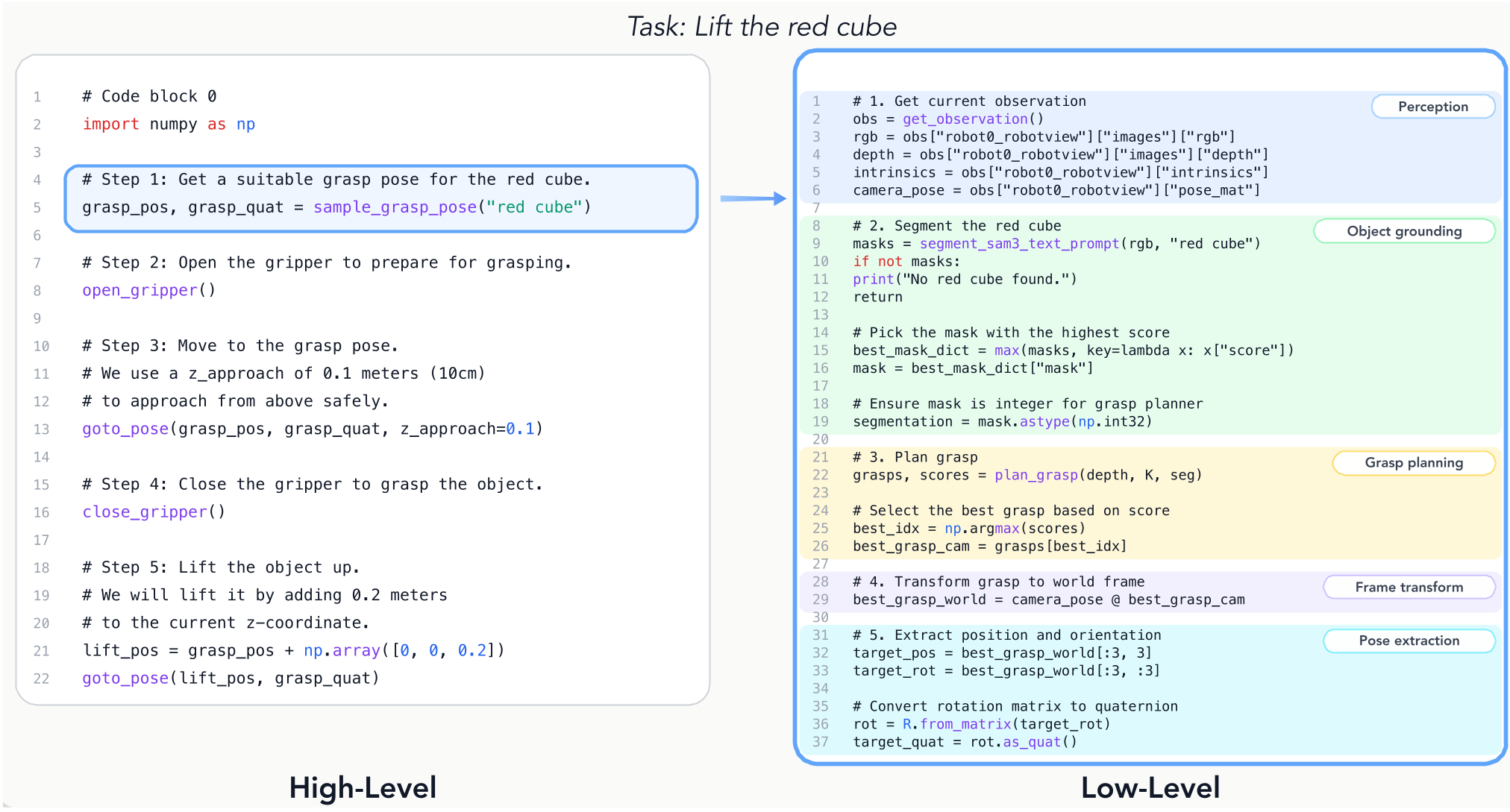
Methodology: CaP-Agent0 and the Power of Multi-Turn Reasoning
To solve the "abstraction gap," the authors introduced CaP-Agent0, a training-free framework built on three pillars:
- Visual Differencing Module (VDM): Instead of feeding the AI raw pixels (which often confuses coding models), VDM uses a VLM to describe the scene changes in text. "The red cube is now 5cm to the left of the goal."
- Auto-Synthesized Skill Library: The agent saves successful code snippets into a "library," effectively teaching itself the "macros" that humans used to have to write.
- Parallel Reasoning (Ensembles): By querying multiple models (GPT-5.2, Claude 4.5, Gemini 3 Pro) and ensembling their code, the system becomes significantly more robust than any single model.
The Architecture of CaP-Agent0
The system operates in a REPL loop. It writes code, executes it in a sandbox (CaP-Gym), looks at the (textual) visual difference, and debugs its own errors.
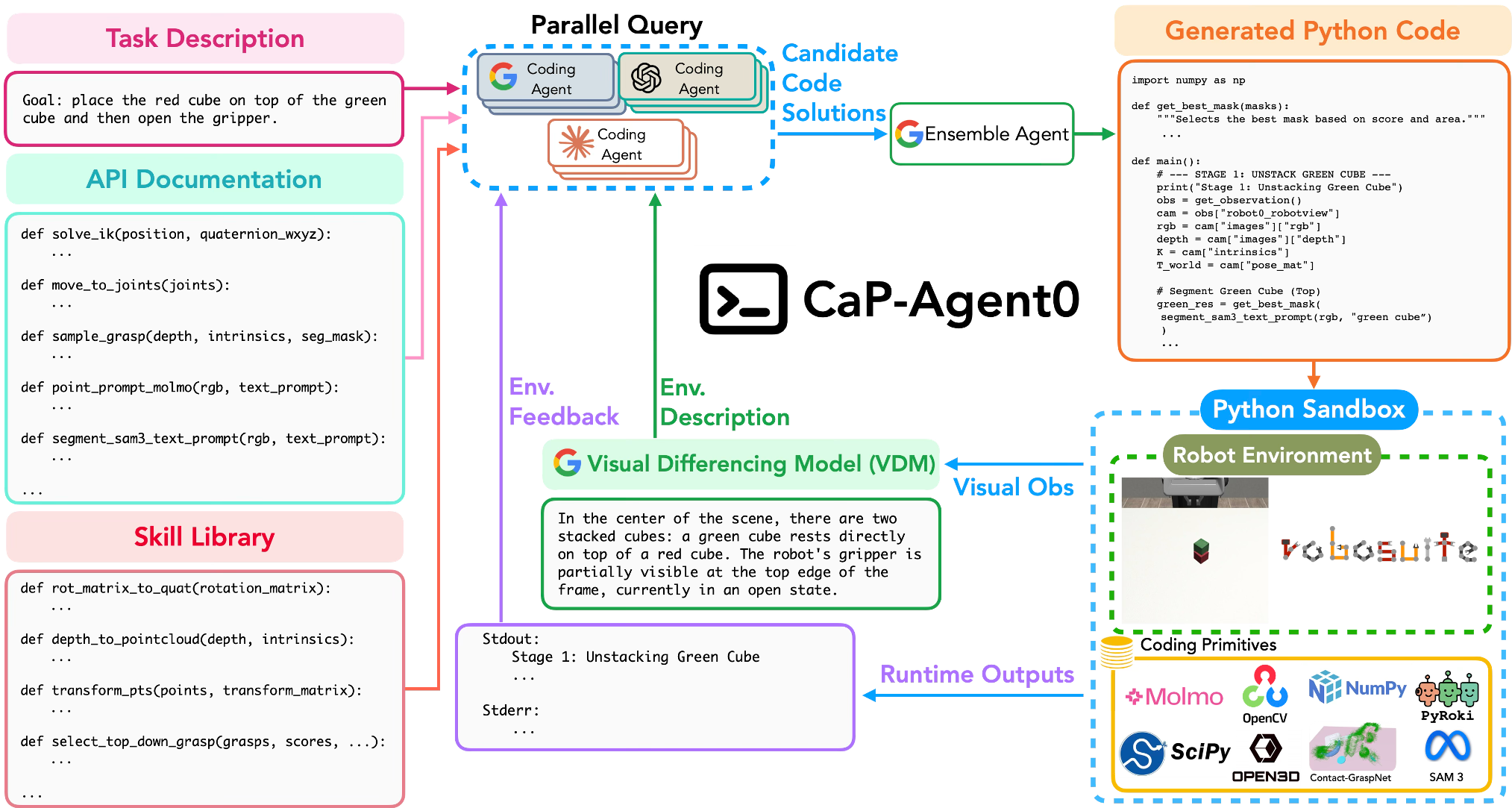
CaP-RL: Teaching LLMs to "Think" Through Robotics
Beyond just prompting, the authors used CaP-RL (Reinforcement Learning) to fine-tune a smaller 7B model. By rewarding the model only when it successfully completed a task in simulation (verifiable rewards), the model stopped "hallucinating" object states and learned Causal Sequencing—understanding that it must close the gripper before it can lift the object.
Experiments: Beating the SOTA
The results are striking:
- Robustness: In the LIBERO-PRO benchmark, when instructions are slightly changed ("Put the frypan on the stove" vs. "Put the moka pot on the stove"), traditional VLA models (π0.5) often fail because they overfit to training data. CaP-Agent0 remains robust because it "reads" the code and thinks logically.
- Real-World Transfer: Because CaP-RL trains on abstract APIs rather than raw pixels, there is almost zero "Sim-to-Real gap." A strategy learned in a simulator works 84% of the time on a real Franka arm immediately.
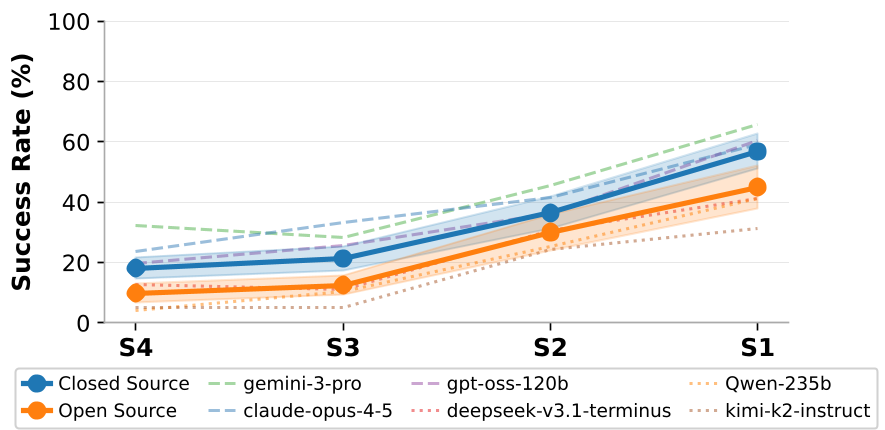
Critical Insight: The "Test-Time Compute" Hypothesis
The most profound takeaway is that robustness can be synthesized at runtime. Instead of making a model larger or training it on more data, we can make it more "reliable" by giving it the tools to verify, debug, and try again. For embodied AI, a multi-turn "thinking" agent is often superior to a single-turn "reflex" model.
Limitations & Future Work
While CaP-X excels at long-horizon reasoning (e.g., "Find the lime under the cups"), it remains brittle for "contact-rich" tasks like threading a needle or pouring thin liquids, which require millisecond-level visual servoing. The authors suggest a hybrid CaP-VLA model as the next frontier: let the coding agent handle the "brain" (logic) and the VLA handle the "hands" (dexterity).
For more details, visit the project page at capgym.github.io.