This study provides causal evidence that Large Language Models (LLMs) use internal confidence signals to guide metacognitive control, specifically in deciding whether to answer a question or abstain. Using a four-phase paradigm across models like GPT-4o and Gemma 3, the researchers demonstrate that LLMs apply implicit and explicit thresholds to their internal certainty. Notably, activation steering was used to causally manipulate these signals, proving that internal confidence directly drives abstention behavior.
Executive Summary
TL;DR
A groundbreaking study from Google DeepMind and Princeton provides the first direct causal evidence that LLMs don't just have confidence—they use it to drive their actions. By introducing a four-phase experimental paradigm, the researchers show that when a model decides to abstain from answering (saying "I don't know"), it is performing a metacognitive act: comparing an internal sense of certainty against a decision threshold.
Background Positioning
While the industry has obsessed over Calibration (making sure a model's 80% confidence actually means 80% accuracy), this paper moves the needle toward Metacognitive Control. It establishes that LLMs possess a functional architecture for meta-decisions that mirrors human and animal psychophysics.
The "Thinking About Thinking" Gap
The primary pain point in LLM reliability is the "hallucination"—an overconfident but wrong answer. Previous attempts to fix this involved "patching" the model (e.g., RAG or fine-tuning). However, the authors asked a deeper question: Is there an internal signal the model already possesses that we can tap into?
They analyzed whether abstention is driven by:
- Objective Difficulty: Is the question just hard?
- Knowledge Accessibility (RAG): Is the info in the training set?
- Metacognitive Confidence: Does the model feel it's likely to be wrong?
Methodology: The Two-Stage Pathway
The researchers mapped the decision-making process into two distinct stages:
- Stage 1 (Representation): The model processes the prompt and generates an internal confidence signal ($C$).
- Stage 2 (Policy): The model compares $C$ to a threshold ($T$) to decide: "Do I speak or stay silent?"
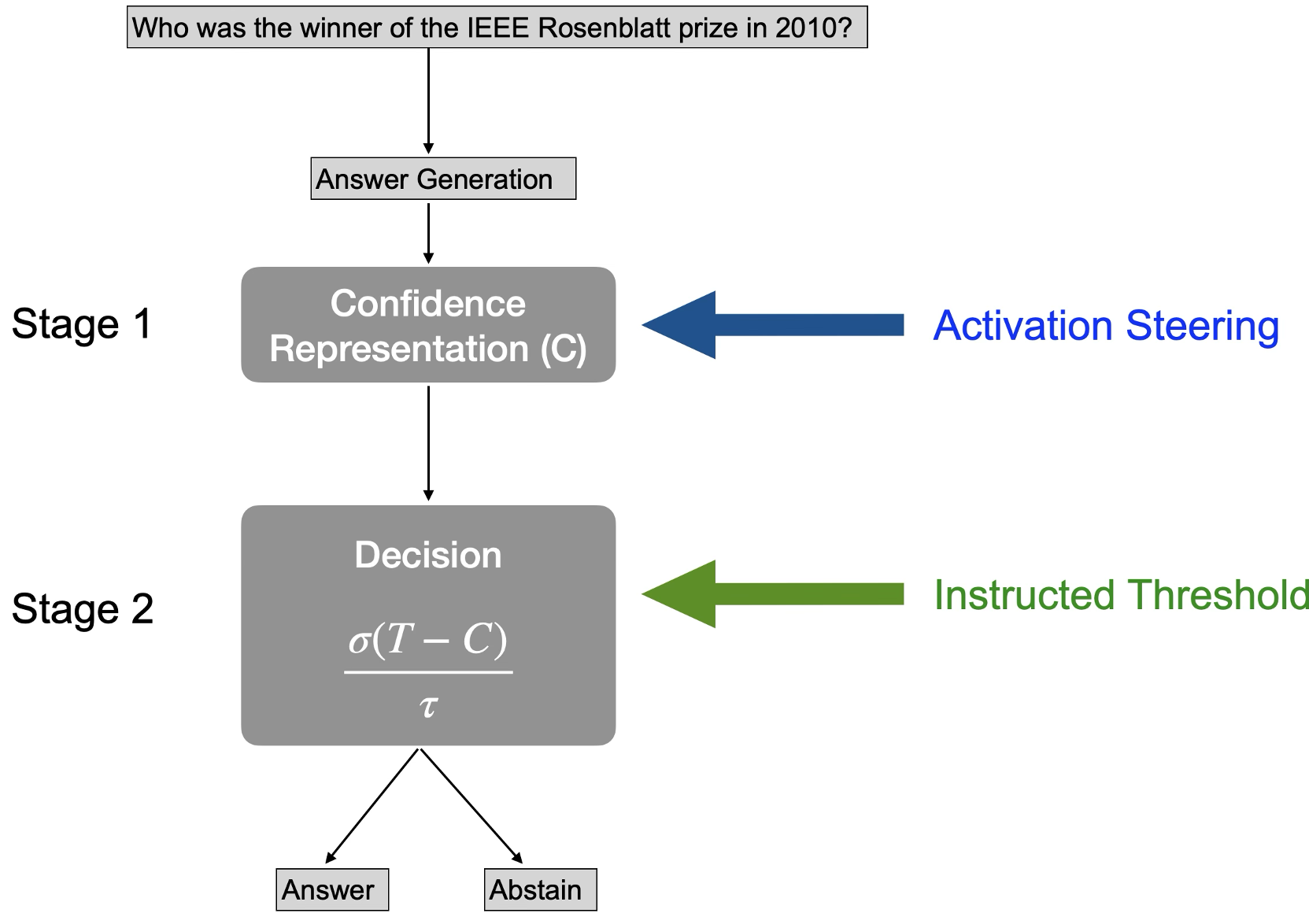
Proving Causality: Activation Steering
The most impressive part of the study is Phase 3. Using Gemma 3 27B, the team extracted "confidence vectors" from the model's inner layers. By injecting these vectors (Activation Steering), they could "brainwash" the model into being more or less confident.
- Result: Injecting high-confidence vectors slashed the abstention rate, while low-confidence vectors forced the model to stay silent more often. This proves that the representation of confidence is causally responsible for the behavior.
Experimental Results: Confidence is King
The data across GPT-4o, DeepSeek, and Qwen was unambiguous. Internal confidence was a significantly better predictor of behavior than any external metric.
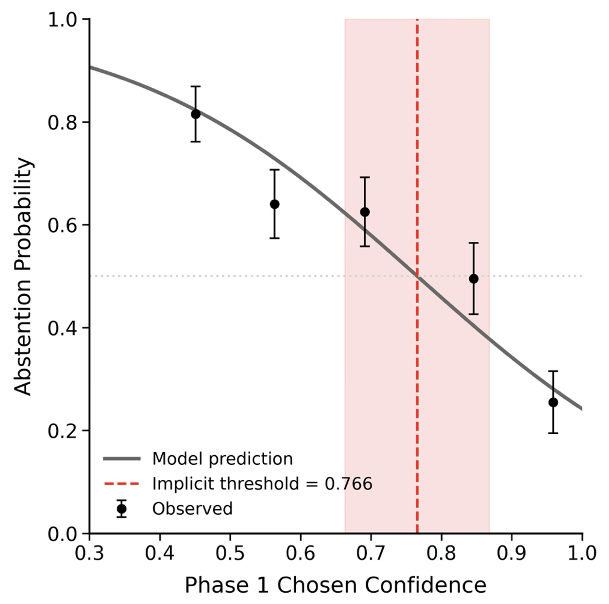
Key Findings:
- Effect Size: Confidence signals were an order of magnitude more influential than RAG scores or surface-level semantic features.
- Policy Temperature: LLMs don't use absolute "on/off" switches; they use a "soft" logistic threshold, much like humans.
- Asymmetric Costs: Models like GPT-4o are naturally conservative. They require ~77% confidence to answer a question when no threshold is specified, suggesting they "fear" being wrong more than they "value" being helpful.
Critical Analysis & Future Outlook
The "Post-Decisional" Trap
The study discovered a fascinating nuance: if you ask an LLM for its confidence after it has already decided to follow a threshold instruction, the report is "tainted." The model's confidence "bakes in" the instruction. This suggests that for true safety monitoring, we must probe pre-decisional internal states (Stage 1) rather than relying on the model’s verbal self-report (which is prone to post-hoc rationalization).
Limitations
A key limitation is the Instruction Adherence Gap. The researchers found that while frontier models like GPT-4o could follow "abstain if you are <X% confident" instructions, smaller or different models (like Gemma 3) required significant prompt engineering to trigger the same behavior. Metacognition is present, but the interface to it is still brittle.
Conclusion
This work shifts the view of LLMs from "stochastic parrots" toward "autonomous agents." If a model can judge its own internal state to decide when to seek help, we are one step closer to AI that knows its limits—a prerequisite for deployment in high-stakes fields like medicine or law.