本文通过四个阶段的实验范式,证明了语言模型(LLMs)能够利用内部置信度(Confidence)信号来驱动弃权(Abstention)行为。研究涵盖了 GPT-4o、Gemma 3、DeepSeek 等主流模型,揭示了模型内部存在类似生物系统的两阶段元认知控制机制。
TL;DR
大语言模型(LLM)在面对不确定的问题时,究竟是随意猜测还是“知道自己不知道”?Google DeepMind 的最新研究给出了肯定的因果证据:LLM 内部确实在利用一种类似生物元认知的信号——置信度 (Confidence),来决定是回答问题还是选择弃权 (Abstention)。研究发现,置信度对弃权行为的影响力远超 RAG 检索分数或问题本身的客观难度。
核心洞察:为何这不仅仅是概率预测?
在人类认知中,元认知(对认知的认知)是高级智能的体现。当我们不确定答案时,会选择保持沉默。长久以来,AI 领域一直希望能让模型在低置信度时自动“认怂”。
之前的研究大多关注模型输出的置信度是否校准准确(Calibrated),而本研究更进一步:它探究了模型是否在使用这些信号。作者提出了一个两阶段计算模型:
- Stage 1:模型生成答案并伴随产生内部置信度表征。
- Stage 2:模型根据设定的(或隐含的)阈值政策,决定最终行为。
实验架构:四阶段深度拆解
为了锁定“置信度”这一因果变量,研究者设计了极其严密的四个阶段:
- Phase 1 (无弃权任务):获取模型纯净的、不受干扰的内部置信度。
- Phase 2 (自由弃权):加入弃权选项,观察模型是否自发建立“高置信度回答,低置信度弃权”的模式。
- Phase 3 (因果干预):通过激活引导 (Activation Steering) 直接扰动模型的神经元活动。
- Phase 4 (指定阈值):显式指令模型在不同置信度百分比下弃权。

关键发现:谁在控制弃权?
通过对 GPT-4o 的逻辑回归分析,研究者对比了几个关键候选因素:
- 置信度 (Confidence):主导地位,标准化系数 |βstd| ≈ 1.0。
- RAG Score:仅 0.1。
- 问题难度 (Difficulty):仅 0.11。
- 语义特征 (Embeddings):仅 0.1。
这意味着,即使问题客观上很难,如果模型“感觉”自己知道,它就会回答;反之亦然。这种基于内部状态而非外部难度的特征,是元认知控制的典型标志。
激活引导:因果性的终极证明
为了排除相关性干扰,研究者在 Gemma 3 27B 上进行了激活引导(如下图)。他们提取了代表“高置信度”和“低置信度”的神经向量,并在推理阶段将其注入模型:
- 注入高置信度向量:模型即使在不懂的情况下也会强行回答,弃权率骤降。
- 注入低置信度向量:模型变得极度保守,弃权率大幅上升。
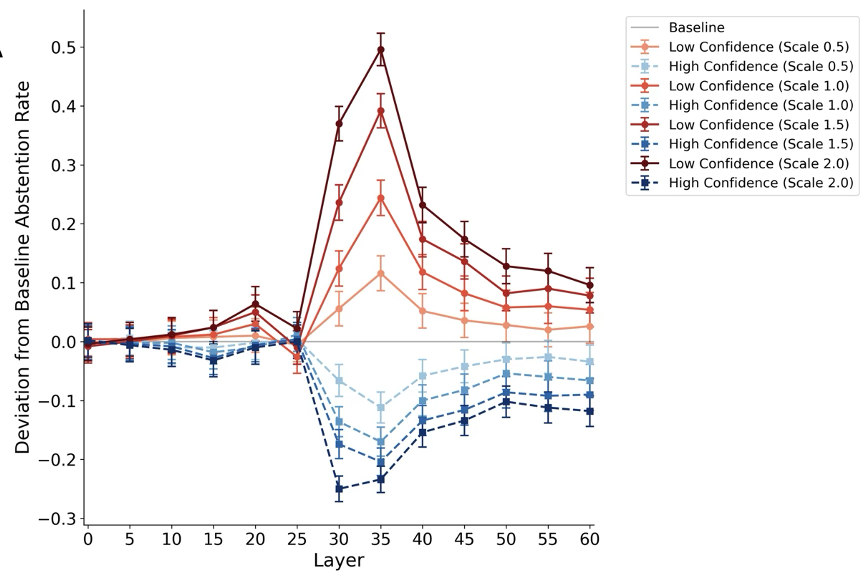
中介分析显示,这种干扰主要是通过“置信度重分配”(Confidence Redistribution)起作用的,即干扰了 Stage 1 的表征,进而级联影响了 Stage 2 的决策。
局限性与展望
尽管研究有力地证明了置信度的因果作用,但也发现不同模型之间存在显著差异。例如,GPT-4o 表现出极强的保守偏向 (Conservatism),即使置信度高于指定阈值,它仍有较大倾向弃权。这可能源于 RLHF(基于人类反馈的强化学习)过程中对“幻觉”的严厉惩罚。
此外,论文指出模型的“口头置信度报告”往往是过度自信的,而其内部引导行为的置信度信号却相对靠谱。这种执行控制与言语汇报的脱节,为未来的模型对齐研究提供了新的思考:我们应该相信模型“说的”,还是相信它“做的”?
总结
这项工作不仅填补了 LLM 元认知理论的空白,更在技术路径上证明了:通过干预模型内部的隐藏层激活,我们可以更精准地控制模型的可靠性。未来,随着模型从被动助手转向主动代理,这种“知道何时闭嘴”的能力将成为决定其商用价值的核心。