The paper introduces CCF (Complementary Collaborative Fusion), a framework specifically designed for Domain Generalized Multi-Modal 3D Object Detection. Aimed at dual-branch proposal-level detectors, it achieves new SOTA performance on a nuScenes-based domain shift benchmark, significantly improving robustness in adverse conditions like rain and night.
TL;DR
Multi-modal 3D detection often "lazy-learns" to rely on LiDAR, causing failure when point clouds are degraded by rain or distance. CCF (Complementary Collaborative Fusion) breaks this dependence by decoupling query supervision, guiding image depth with LiDAR priors, and using a clever "complementary masking" augmentation to force the model to respect both sensors equally.
Background: The Hidden Imbalance in Multi-Modal Fusion
While combining LiDAR and Cameras has pushed SOTA in 3D detection, these models are often "fair-weather friends." When moved from sunny Singapore to rainy Boston or dark nights, performance collapses.
The authors reveal a startling statistic: in standard dual-branch detectors (like MV2DFusion), the training process assigns ground-truth boxes to 3D queries 37.5 times more often than to 2D queries. Because LiDAR provides immediate geometric precision, the model's optimization ignores the rich semantic potential of images, leaving the camera branch under-trained and ineffective when the LiDAR signal becomes noisy.
Methodology: Restoring Symmetry to Perception
CCF introduces three architectural interventions to treat cameras as first-class citizens in the 3D world.
1. Query-Decoupled Loss: Independent Supervision
To fix the 37.5:1 supervision gap, CCF doesn't just throw all queries into one decoder. Instead, it uses three parallel, weight-shared decoder passes:
- 2D-only: Forces the image branch to predict 3D boxes without LiDAR help.
- 3D-only: Maintains the LiDAR-specific capability.
- Fused: The standard path where both collaborate.
This ensures that 2D queries receive a dedicated gradient signal, preventing them from being overshadowed during the Hungarian matching process.
2. LiDAR-Guided Depth Prior
2D queries often fail because depth estimation from a single image is mathematically ill-posed. CCF fixes this by creating a Dual-Source Depth Distribution. It takes the sparse LiDAR points falling within a 2D proposal's frustum and builds a geometric histogram. A lightweight confidence network then adaptively blends the image-predicted depth with this LiDAR prior, giving the 2D query a much more accurate 3D "starting point."
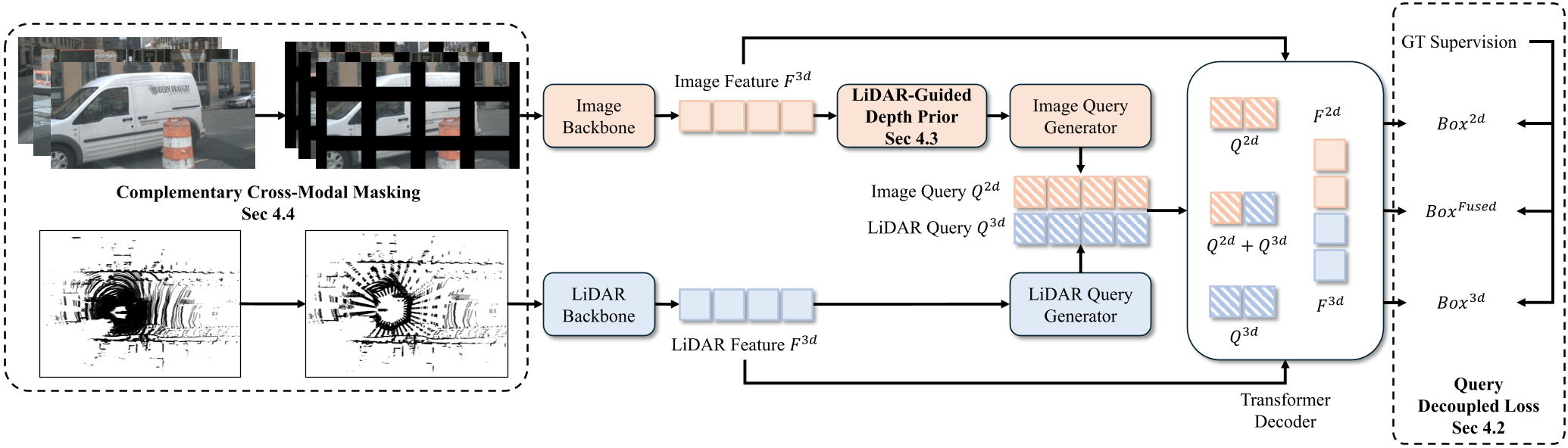
3. Complementary Cross-Modal Masking
To prevent the fused decoder from always picking the "LiDAR shortcut," the authors propose a unique augmentation. Instead of dropping whole sensors, they apply complementary spatial masks. If a region of the image is masked, the corresponding LiDAR points are kept, and vice versa. This forces the queries to "compete" and learn how to extract information from whichever sensor is available in a specific patch of the scene.
Experiments & Results
The framework was tested on a rigorous domain-shift benchmark derived from nuScenes.
- Rainy Weather: mAP increased by 2.8%.
- Night Scenes: mAP increased by 1.3%.
- Unseen Geography (Boston): mAP increased by 3.2%.
Importantly, as shown in the qualitative results below, CCF significantly reduces false negatives (missed cars) in distant or obscured regions where the LiDAR point cloud is naturally sparse.

Critical Insights & Conclusion
The core value of CCF lies in its recognition that architecture alone isn't enough for robustness. If the training dynamics (specifically the loss assignment) are biased toward one modality, the model will inherently be fragile.
Takeaway: By decoupling the supervision and providing "geometric scaffolding" to the camera branch, CCF achieves a more balanced and collaborative fusion. This is a critical step toward autonomous systems that can reliably navigate through the "long tail" of adverse weather and lighting conditions.
Limitations: While CCF improves depth for 2D queries, it still relies on at least some LiDAR presence for the geometric prior. In scenarios with total LiDAR failure, the performance may still have room for improvement through more advanced monocular depth experts.