The paper presents a comprehensive pipeline for humanoid running that combines Dynamic Retargeting via constrained optimization with Control-Guided Reinforcement Learning (CLF-RL). By leveraging a single human motion demonstration to create a library of periodic, dynamically feasible references, the authors achieved high-speed (3.3 m/s) controllable running on the Unitree G1 humanoid robot.
Executive Summary
TL;DR: Researchers from Caltech have developed a pipeline that enables humanoid robots to run at human speeds (up to 3.3 m/s) with the precision required for autonomous obstacle avoidance. The core innovation lies in Dynamic Retargeting—using optimization to "fix" captured human motion for robot dynamics—and CLF-RL, a reward structure that uses Control Lyapunov Functions to ensure the robot stays stable while following commands.
Background: This work sits at the intersection of classical control theory and modern Deep RL. While RL has recently dominated locomotion, it often lacks the "controllability" needed for a robot to be truly autonomous. This paper proves that we don't have to choose between the agility of RL and the mathematical rigor of control theory.
Problem & Motivation: The "Mimicry" Trap
Most recent humanoid breakthroughs (like DeepMimic or ZEST) involve training a policy to copy a human video. While visually impressive, this approach has two fatal flaws:
- Dynamic Inconsistency: A human's center of mass and joint limits differ from a robot's. Simple "kinematic" copying results in "jittery" or unstable motions.
- Control Gap: Pure mimicry policies are often "single-track"—they play back a clip but don't know how to change speed or turn smoothly in response to a high-level planner.
The authors' insight was that we must first optimize the human data into a periodic, dynamically feasible library before handing it to the RL agent.
Methodology: The Best of Both Worlds
The architecture is a three-stage pipeline: Optimize -> Train -> Deploy.
1. Dynamic Retargeting
Instead of raw human motion, the authors use Multiple Shooting Optimization. They take a single stride of human data and apply hard constraints:
- Periodicity: The end of the stride must perfectly match the beginning (mirrored).
- Hybrid Dynamics: The motion must respect "Single Support" (one foot) and "Flight" (both feet off) phases.
- State Constraints: Forcing the robot to maintain specific forward velocities.
2. CLF-Guided Reinforcement Learning
The secret sauce is the CLF-RL reward. Unlike standard "Mimic" rewards that just penalize distance from a reference, CLF-RL uses a Lyapunov Function ($V = \eta^T P \eta$).
- It rewards the policy not just for being close to the target, but for moving toward it in a way that guarantees stability (the "decrescent condition").
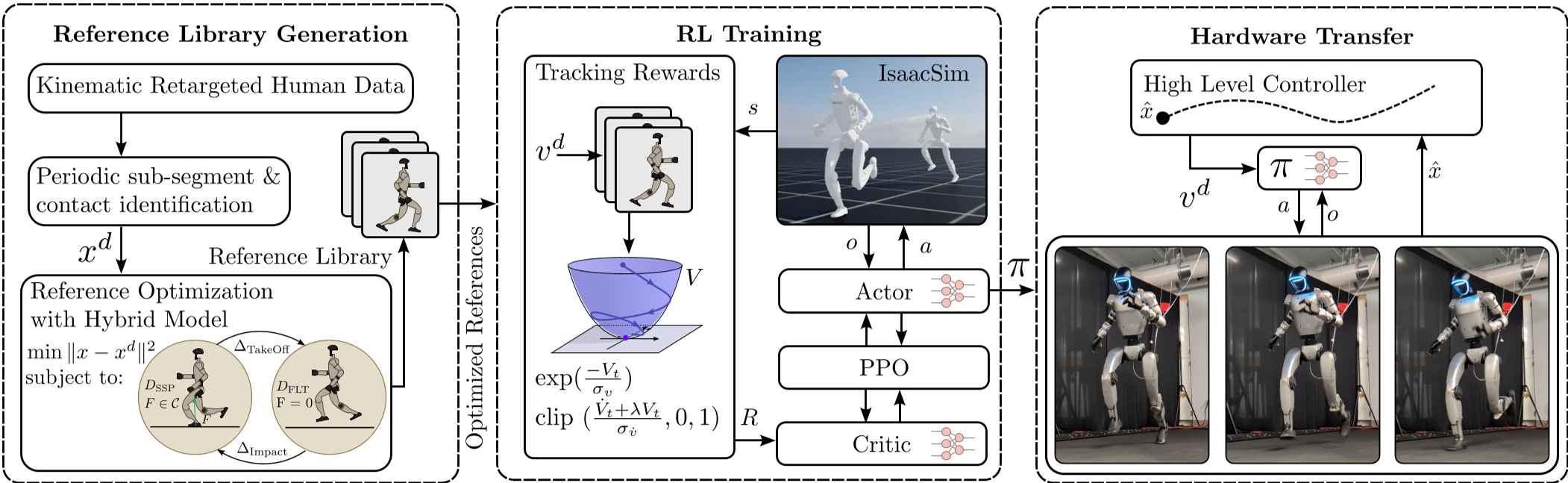 Fig 1: The full pipeline from human data optimization to autonomous deployment.
Fig 1: The full pipeline from human data optimization to autonomous deployment.
Experimental Evidence: SOTA Performance
Speed and Precision
The policy was deployed on the Unitree G1. In simulation ablations, the authors found that CLF rewards consistently outperformed Mimic rewards in tracking accuracy (Fig 2).
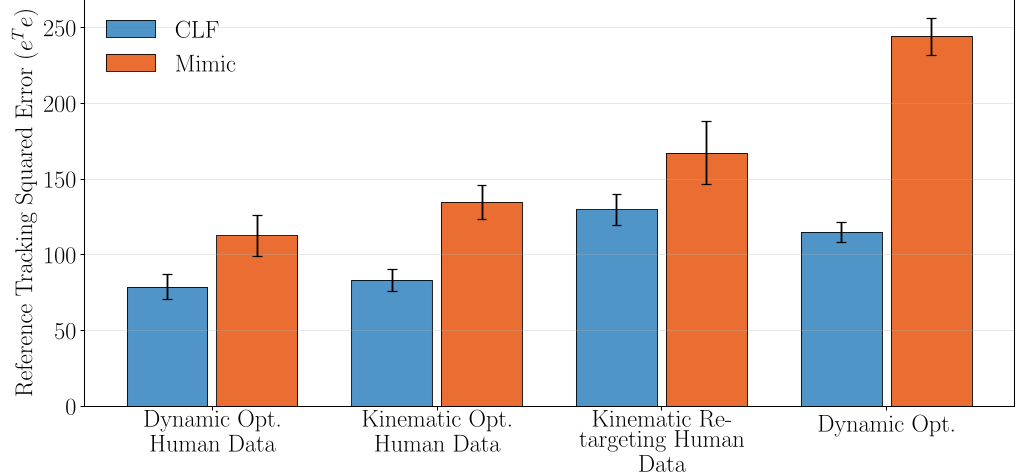 Fig 2: CLF-RL (green/purple) shows lower error than standard Mimic rewards (orange/red) across different motion generation methods.
Fig 2: CLF-RL (green/purple) shows lower error than standard Mimic rewards (orange/red) across different motion generation methods.
Real-World Autonomy
On hardware, the robot achieved:
- Top Speed: 3.3 m/s on a treadmill (significant for a robot of this scale).
- Endurance: Hundreds of meters in outdoor environments with varied friction.
- Intelligence: By integrating the RL controller with an MPC + CBF (Control Barrier Function) stack, the robot could "dodge" obstacles while maintaining a 2 m/s run.
 Fig 3: The robot uses Lidar to update an occupancy map and adjust its running commands in real-time to avoid collisions.
Fig 3: The robot uses Lidar to update an occupancy map and adjust its running commands in real-time to avoid collisions.
Critical Insight & Future Work
The most striking takeaway is that human data is a better "prior" than pure optimization. While we can optimize a gait from scratch, human-inspired motions have a "style" and natural efficiency that makes RL Convergence much faster and the resulting behavior more robust.
Limitations: The current system relies on a pre-generated library. If the robot encounters a slope or terrain not captured in the library, performance might degrade. The next frontier is online retargeting, where the robot optimizes its reference gait on-the-fly to adapt to 3D environments.
Conclusion
This work sets a new bar for humanoid locomotion. By treating RL as a "robustness engine" but keeping the "geometric structure" of control theory, the authors have created a humanoid that doesn't just run—it navigates.