本文提出了 CoInteract,一个端到端的人机交互 (HOI) 视频生成框架。该方法基于 Diffusion Transformer (DiT) 架构,通过空间结构化协同生成和人脸/手部专家模型,在语音驱动下实现了物理一致性高、结构稳定的产品展示视频,达到了该领域的 SOTA 水平。
TL;DR
在电商直播和虚拟营销中,合成人物演示产品的视频具有巨大的商业价值。然而,目前的视频扩散模型在处理人手抓握物体时经常“穿帮”——要么手指扭曲,要么手直接穿过了物体。来自清华和阿里的研究团队提出了 CoInteract,通过在 DiT 模型中嵌入辅助结构流和空间专家模型(MoE),不仅解决了穿模问题,还保证了推理时的零额外开销。
背景定位:从“能说话”到“能交互”
目前的数字人技术在“对口型”和“换脸”上已相当成熟,但当任务升级为“主动演示产品”时,挑战接踵而至。人机交互 (Human-Object Interaction, HOI) 要求极高的时间协同、精准的物理基础和稳定的解剖学结构。CoInteract 正是瞄准了这一 HOI 视频生成的深水区。
痛点深挖:为什么模型老是“穿模”?
作者认为,现有的扩散模型是 RGB 驱动的,模型只学会了预测像素,却不理解 3D 空间中的物体边界和身体拓扑结构。这导致了两个典型的失败模式:
- 结构崩坏:手指数量不对或面部表情模糊。
- 物理违规:手部与物体的穿透(Interpenetration),完全无视了物体的边界。
核心方法论:结构化协同生成与人感 MoE
1. 空间结构化协同生成 (Spatially-Structured Co-Generation)
CoInteract 并不只是生成 RGB 图像。在训练阶段,它开辟了一个辅助 HOI 结构流。这个流会把人体简化成剪影,同时保留物体的掩码。
- 直觉:强迫 DiT 的共享权重在处理像素的同时,必须学习背后的几何关系。
- 非对称协同注意力 (Asymmetric Co-Attention):这是点睛之笔。通过特殊的 Mask,RGB 流在推理时可以完全脱离辅助流运行,从而实现“零开销”推理。
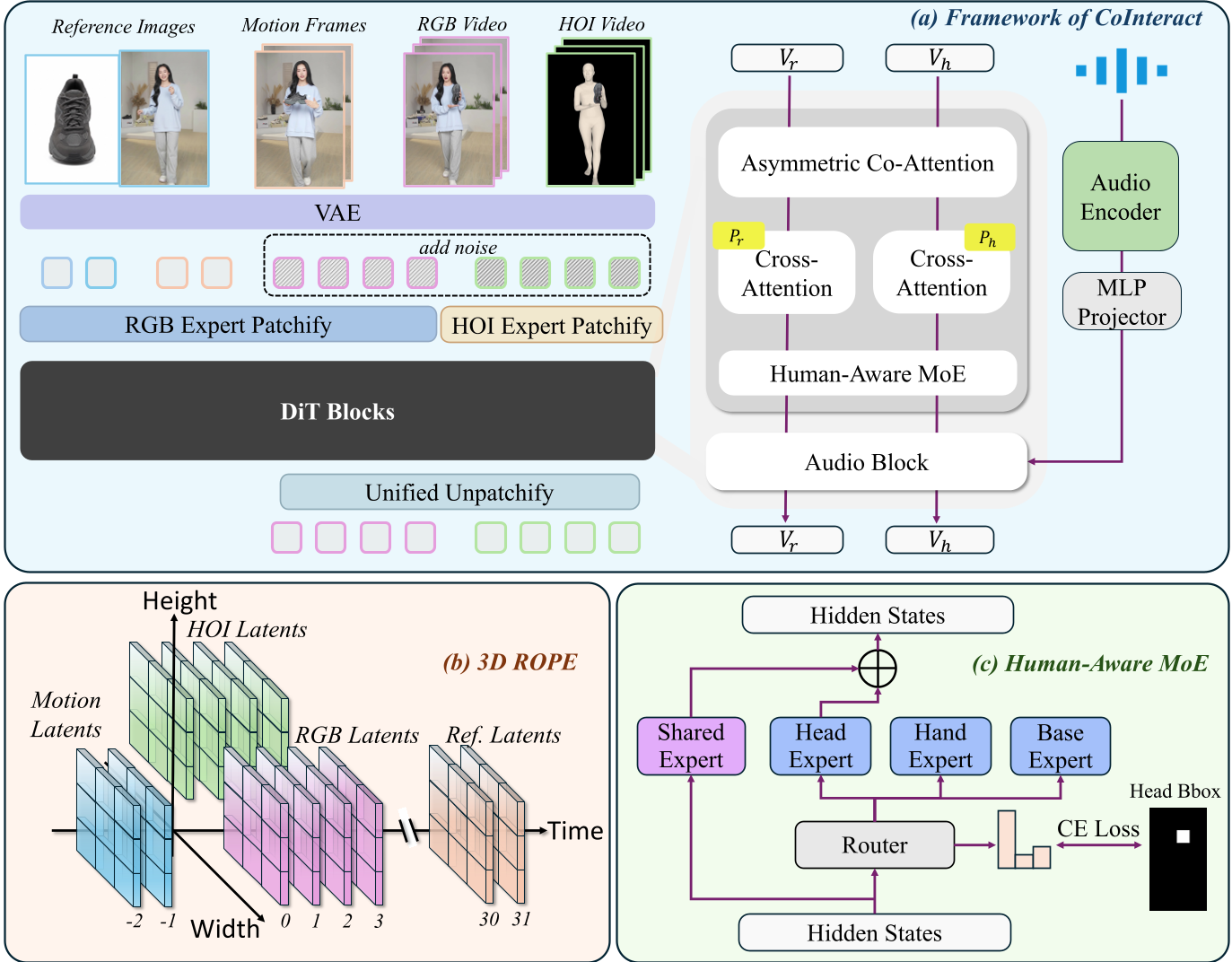 图 1:CoInteract 的双流架构,展示了 RGB 与辅助结构流如何共享 DiT 主干。
图 1:CoInteract 的双流架构,展示了 RGB 与辅助结构流如何共享 DiT 主干。
2. 人感混合专家模型 (Human-Aware MoE)
为了解决手部和脸部的精细细节,模型内部部署了 Head, Hand, Base 三类专家。
- 空间路由 (Spatial Routing):利用人脸和手部的 Bounding Box 作监督,精准地把对应区域的 Token 甩给特定专家,确保这些“敏感区域”有足够的参数量进行拟合。
 图 2:路由热力图显示,模型能精准识别手部与脸部并分配给不同的专家模块。
图 2:路由热力图显示,模型能精准识别手部与脸部并分配给不同的专家模块。
实验与结果:真实的交互表现
CoInteract 在大规模 HOI 数据集上进行了 40 小时的视频训练。在量化对比中,CoInteract 在反映交互真实感的 VLM-QA(基于 Gemini-Pro 的视频质量评估)和 Hand Quality 面板上大幅领先 AnchorCrafter 和 SkyReels 等强力基线。
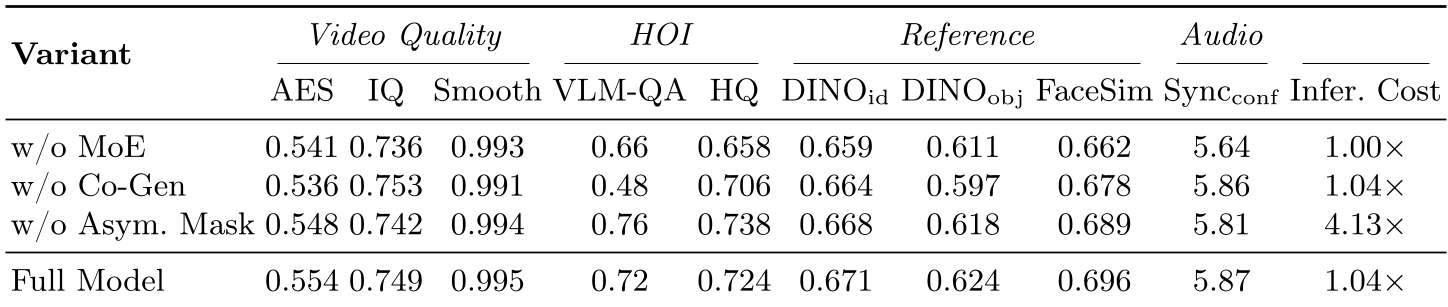 表 1:消融实验揭示,移除 MoE 会导致手部质量 (HQ) 暴跌,移除 Co-Gen 则会导致交互逻辑 (VLM-QA) 的严重下滑。
表 1:消融实验揭示,移除 MoE 会导致手部质量 (HQ) 暴跌,移除 Co-Gen 则会导致交互逻辑 (VLM-QA) 的严重下滑。
消融实验中的深度洞察
- MoE 的效率:引入 MoE 仅增加了 4% 的推理开销,但对手部稳定性的提升是决定性的。
- 双流合并:尝试过推理时保留双流,虽然效果微增,但推理成本会翻 4 倍。作者采用的异步 Mask 策略在性能与效率间取得了绝佳平衡。
总结与展望
CoInteract 的成功说明:生成式 AI 的下一步不仅是追求“画得像”,更要追求“动得对”。通过将几何先验(剪影、掩码)作为辅助任务注入 Transformer,模型能够内化物理规则。
局限性:尽管目前在抓握小物上表现优异,但对于极复杂的交互(如玩魔方或穿衣服),或者极端光影下的遮挡,模型仍有一定的提升空间。
未来启示:这一架构可以很容易地扩展到 3D 内容创作或更广泛的机器人视觉仿真领域,为物理仿真和生成艺术的合流提供了新的范式。