本文提出了 CoRAL,一种用于复杂接触式机器人操纵的神经符号框架。该方法将 LLM 作为“代价函数设计器”而非直接控制器,并结合采样运动规划器(MPPI)实现了在未知环境下的 zero-shot 自适应控制。
TL;DR
来自比尔肯特大学的研究团队提出了 CoRAL (Contact-Rich Adaptive LLM-based Control)。它不让 LLM 直接“开车”(输出动作),而是让它“写剧本”(设计代价函数)。通过将 LLM 的语义推理与 MPPI (模型预测路径积分) 规划器结合,CoRAL 在完全没有演示数据的情况下,学会了如何利用墙壁翻转物体、从桌边缘抓取薄板等极具挑战性的灵巧操纵任务。
1. 痛点:为什么 VLA 模型在“硬碰硬”时会熄火?
当前的深度学习驱动机器人(如 OpenVLA, )大多遵循端到端路径,通过模仿学习将视觉和语言映射到动作。但在**富接触(Contact-Rich)**场景下,这种方法存在三个致命伤:
- 数据瓶颈:精确的力反馈和接触动力学数据极难在大规模数据集中获取。
- 缺乏物理常识:模型不知道金属块和泡沫块的质量差异,导致抓取策略生硬。
- 黑盒局限:一旦遇到 sim-to-real 的误差(如实际摩擦力比模拟大),模型无法解释原因也无法实时修正。

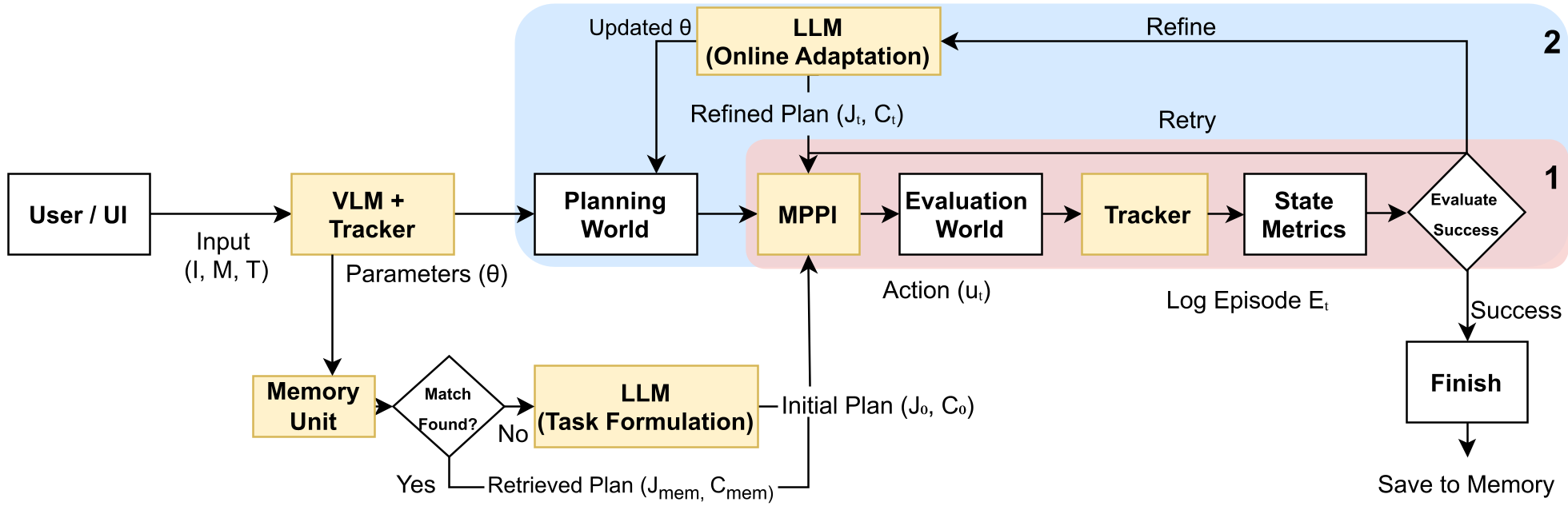
2. 核心机理:神经符号的“分权统治”
CoRAL 的精髓在于解耦。它将任务拆分为三个层级,通过不同的模型负责:
A. 感知层:VLM 提供“物理直觉”
系统使用 FoundationPose 追踪物体的 6-DoF 位姿。同时,利用 VLM(如 GPT-4o)的常识,根据图片判断物体的物理属性。
- 输入:图片 + “看起来像金属板”。
- 输出:初始质量估计(例如 0.5kg)和摩擦系数。
B. 推理层:LLM 作为代价函数设计师 (Cost Designer)
这是 CoRAL 最惊艳的地方。LLM 会直接生成 Python 代价函数代码。
- 指令:“把板推到桌边然后抓起它的把手”。
- 生成的逻辑:LLM 会写出带有
sigmoid软切换的代价函数。当板还没过桌边时,惩罚项集中在横向偏移上;一旦满足悬空条件,重心自动转向抓取把手的对齐项。
C. 执行层:MPPI 实时采样
底层由 MPPI 规划器以 10Hz 频率运行。它在“脑内”模拟数千条可能的路径,根据 LLM 给出的代价函数选出最优的一条。
3. 在线自适应:会“自省”的机器人
如果机器人推不动一个物体,CoRAL 不会一遍遍尝试错误动作。它有一个 Outer Loop(外环):
- 失败诊断:当内环重试多次失败,LLM 会分析执行日志。
- 参数修正:LLM 意识到“物体没动是因为我低估了重力”,随即在仿真世界中调高质量参数。
- 策略重写:如果发现当前的代价函数权重不对(如力太小),LLM 会重新生成一份 Python 代码。
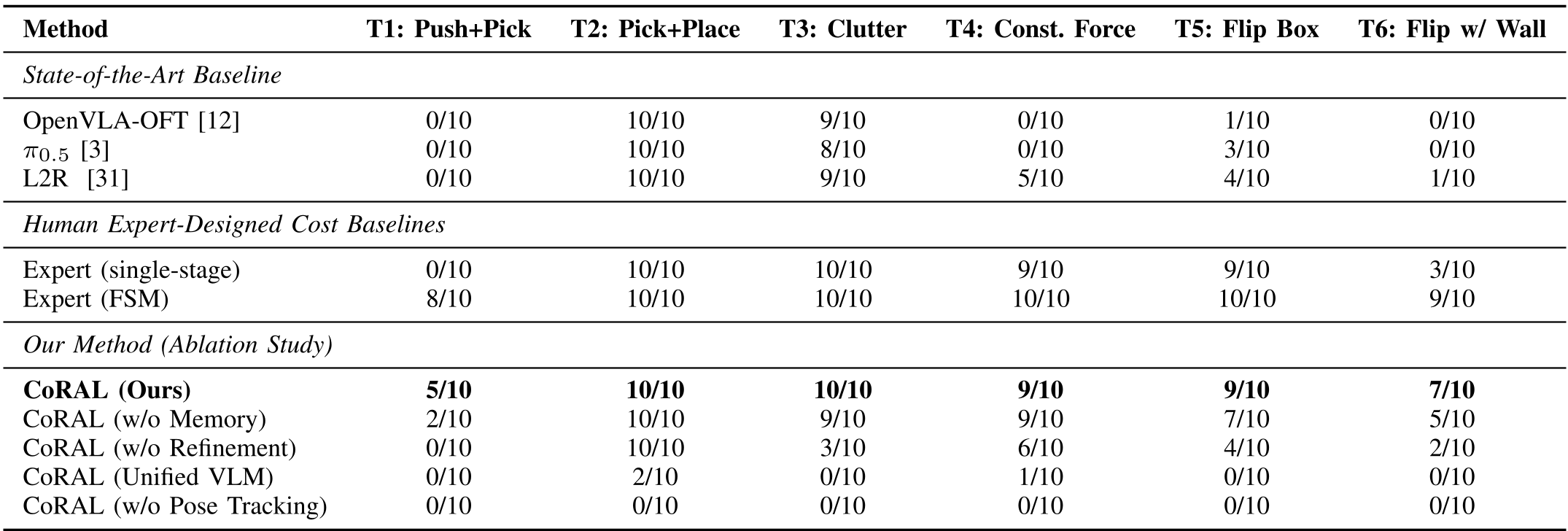
4. 实验进展:Zero-Shot 战胜 SOTA
研究人员对比了目前最强的基线模型,结果显示:
- 复杂任务突破:在“利用墙壁翻转盒子”这种需要多点接触推理的任务中,SOTA VLA 模型几乎全军覆没,而 CoRAL 达到了 70% 的成功率。
- 消融验证:如果没有
FoundationPose做精确位姿追踪,或者没有 LLM 进行在线修正,成功率会暴跌至 0%。这证明了“感知+符号推理+控制”这一组合的不可替代性。
5. 深度洞察:物理智能的未来
CoRAL 的意义在于它证明了:大模型不需要学会如何精确控动力学,它只需要学会如何描述“好的状态”是什么样的。
通过将 LLM 的语义理解转化为数学上的代价函数(Cost Function),我们建立了一座连接“模糊语言”与“精确物理”的桥梁。这种架构不仅解决了 Explainability(可解释性)问题——你可以直接阅读 LLM 生成的诊断报告——还极大提升了数据效率,让机器人能在从未学过的场景中,通过“思考”和“尝试”来完成任务。
局限性:CoRAL 目前仍依赖高质量的 3D 模型和位姿追踪。如果视觉系统出现幻觉(Hallucination),后续的物理建模也会受影响。
总结:CoRAL 展现了一种高度优雅的混合路线。它告诉我们,通往通用人工智能机器人的道路,未必是把模型堆得更大,而是让模型更懂得如何利用已有的物理规律和控制理论。