本文提出了 Coupling Models,一种针对离散数据生成(如文本、DNA序列、图像)的单步(One-step)生成框架。该方法通过在离散序列与高斯隐空间之间建立一种可采样的连续耦合,实现了仅需一次模型前向传播即可生成高质量离散序列的任务,并在多项基准测试中打破了单步生成的 SOTA 记录。
TL;DR
在离散生成领域(如大模型文本生成),“快”与“好”往往不可兼得。自回归模型虽然质量高但推理极慢,而扩散模型则需要痛苦的多步迭代。本文提出的 Coupling Models 抛弃了传统的“轨迹压缩”思路,通过在离散序列和高斯噪声之间建立一种直接耦合,实现了单次前向传播(One-step)即可产出高质量离散样本,在文本、生物序列和图像任务上全面超越了现有的单步基线。
背景定位:单步生成的“表示陷阱”
为什么单步生成离散数据这么难?作者指出,这不仅是一个优化问题,更是一个表示(Representation)问题。
传统的单步解码器(Token-wise decoder)试图在一次预测中同时决定所有位置的 Token。由于缺乏自回归的顺序依赖或扩散模型的反复修正,这种模型本质上倾向于假设各位置相互独立(因子化假设)。数学证明显示,这种因子化模型所能表达的概率分布空间极小,根本无法捕捉现实数据中复杂的全局相关性。
核心机制:从轨迹压缩到耦合反转 (Coupling Inversion)
Coupling Models 不再纠结于如何缩短现有的扩散轨迹,而是另辟蹊径,采用了两阶段架构:
1. 阶段 A:建立高斯耦合 (Discrete → Gaussian)
利用 Normalizing Flow (归一化流) 将复杂的离散序列映射到一个简单的高斯隐空间 。
- 作用:将序列中的全局相关性(Cross-token dependence)“压缩”并“对齐”到连续的隐变量中。
- Loss 设计:结合了重构损失(确保不丢信息)和流似然损失(确保隐空间服从高斯分布,方便采样)。
2. 阶段 B:并行解码反转 (Gaussian → Discrete)
冻结第一阶段的编码器,训练一个并行解码器 ,使其能够从采样自高斯分布的 直接预测出完整的 Token 分布。
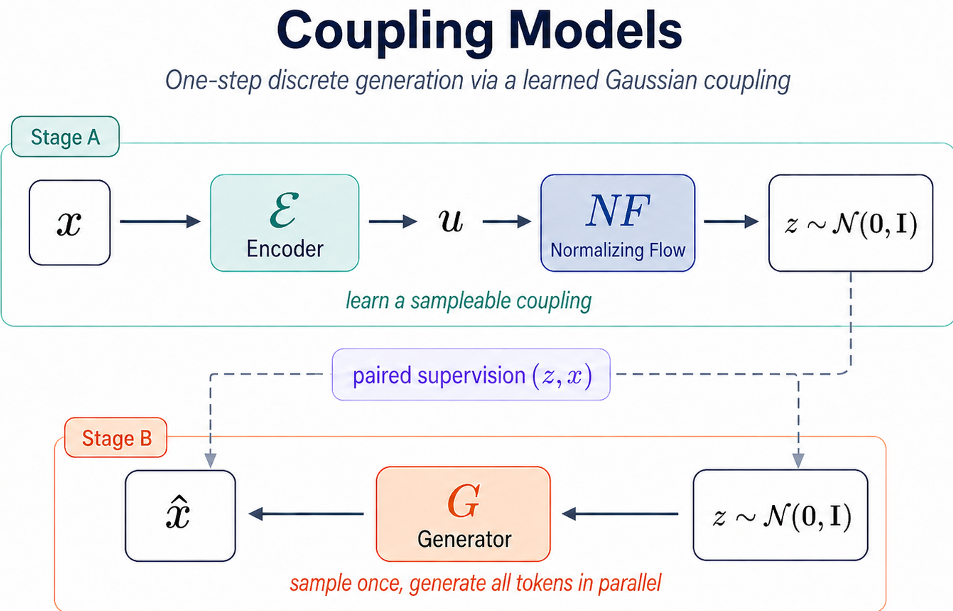 图 1:Coupling Model 概览。阶段 A 学习耦合,阶段 B 学习单步并行解码。
图 1:Coupling Model 概览。阶段 A 学习耦合,阶段 B 学习单步并行解码。
实验战绩:全领域的降维打击
Coupling Model 在三大跨度极大的领域验证了其普适性:
- 文本生成 (LM1B):在相同的多样性(Entropy)水平下,其生成的困惑度远低于 FMLM 和 DFM 等前沿单步方法(见图 2)。
- DNA 序列设计:在 Fly Brain 增强子设计任务中,将 FBD 指标从 15.8 优化至 12.9。
- 图像生成 (MNIST):FID 达到 5.50,相较于之前最好的单步模型提升了近一倍。
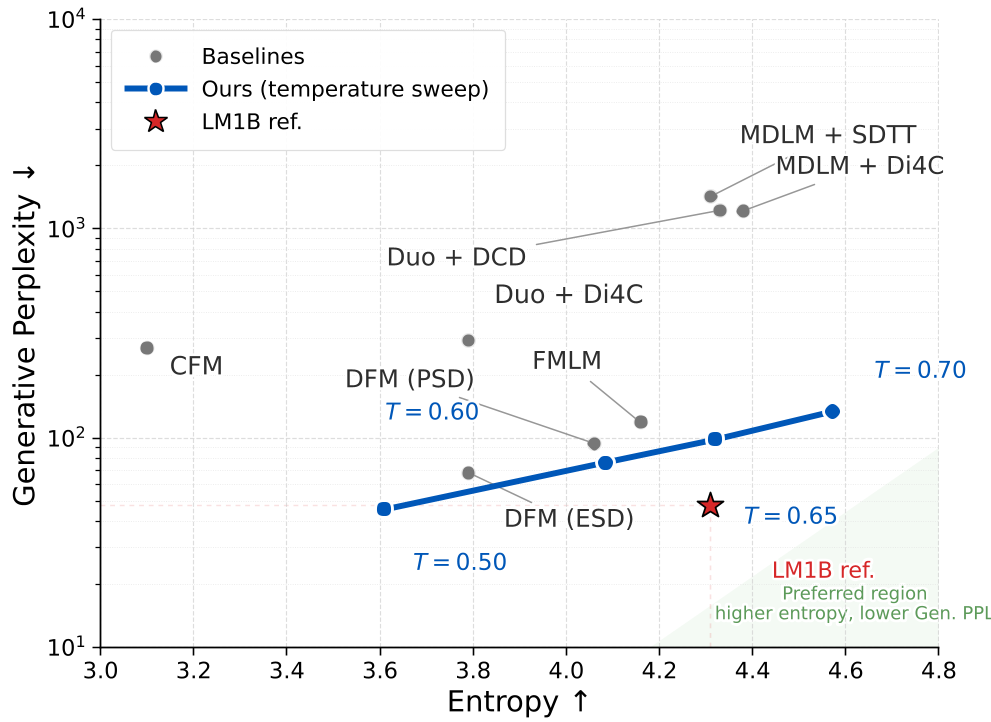 图 2:LM1B 上的质量-多样性前沿。可以看到 Coupling Model 显著向左下方(低困惑度、高熵)移动。
图 2:LM1B 上的质量-多样性前沿。可以看到 Coupling Model 显著向左下方(低困惑度、高熵)移动。
深度洞察:为什么这种方法更有效?
作者在理论上分析了 Latent Matching (隐匹配) 的重要性。如果阶段 A 诱导出来的隐空间 marginal distribution 与采样时的 Gaussian prior 不对齐,解码器在推理时就会遇到 Out-of-Distribution (OOD) 问题。通过引入 Normalizing Flow 强制对齐,模型确保了“训练时见的”和“推理时生成的”隐变量在统计分布上高度一致。
此外,这种连续隐变量接口让 Guidance (引导生成) 变得极其高效。在传统的 Masked Diffusion 中,引导信号需要穿透数十步随机转换;而在 Coupling Model 中,引导直接作用于最终 logits 或起始隐变量 ,路径极短。
总结与展望
Takeaway:Coupling Models 告诉我们,离散生成的“快”不需要通过牺牲“好”来换取。通过将全局信息交给连续隐空间,将局部排放交给并行解码器,我们可以在单步推理中找回丢失的生成质量。
局限性:尽管实验覆盖面广,但模型规模尚处于中等水平(如 Qwen2.5-0.5B 级别)。未来如何将这一范式扩展到超长文本或千亿参数级别的 LLM,将是工业界极具吸引力的探索方向。