This paper introduces CoVerRL, a label-free reinforcement learning framework that solves mathematical reasoning tasks by co-evolving a single model's generator and verifier roles. It leverages a bidirectional bootstrapping mechanism where majority voting provides initial supervision for the verifier, and the improved verifier subsequently filters "consensus trap" errors to refine the generator.
TL;DR
Reinforcement Learning with Verifiable Rewards (RLVR) typically requires ground truth, but what if you have no labels? While "Majority Voting" is the standard label-free proxy, it leads models into a Consensus Trap—where they become confidently wrong. CoVerRL breaks this cycle by making a single model act as both Generator and Verifier, allowing them to bootstrap each other’s intelligence. The result? A 5.9% performance boost on math tasks and a verifier that generalizes better than GPT-4 Turbo.
The Problem: The Consensus Trap
Standard label-free RL uses consistency as a reward: if 10 out of 16 reasoning paths agree on "42", the model assumes "42" is correct.
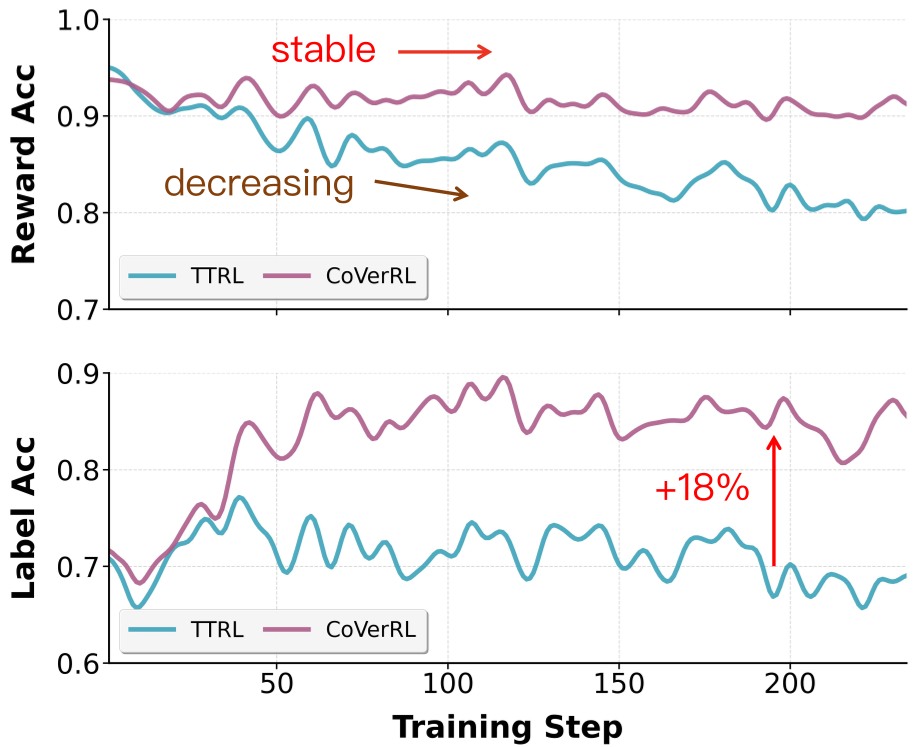
However, as the model trains, it loses diversity. It starts "collapsing" onto the most frequent answer. If that answer is a systematic error, the model creates a destructive feedback loop: it reinforces its own mistakes with increasing confidence. As shown in the authors' analysis, vanilla methods (TTRL) see their reward accuracy plummet as training progresses because they can no longer distinguish between "consistent" and "correct."
The Insight: Co-Evolution as an Escape Hatch
The authors propose CoVerRL, which treats the model as a dual-role agent. The core breakthrough is Bidirectional Supervision:
- Consensus Supervises the Verifier: Even if pseudo-labels are noisy, the contrast between "Majority" and "Minority" answers provides a training signal for the verifier role.
- The Verifier Purifies the Generator: Once the verifier learns even a bit of reasoning logic, it can "veto" a majority answer if the steps leading to it are logically flawed, effectively cleaning the training data for the generator.
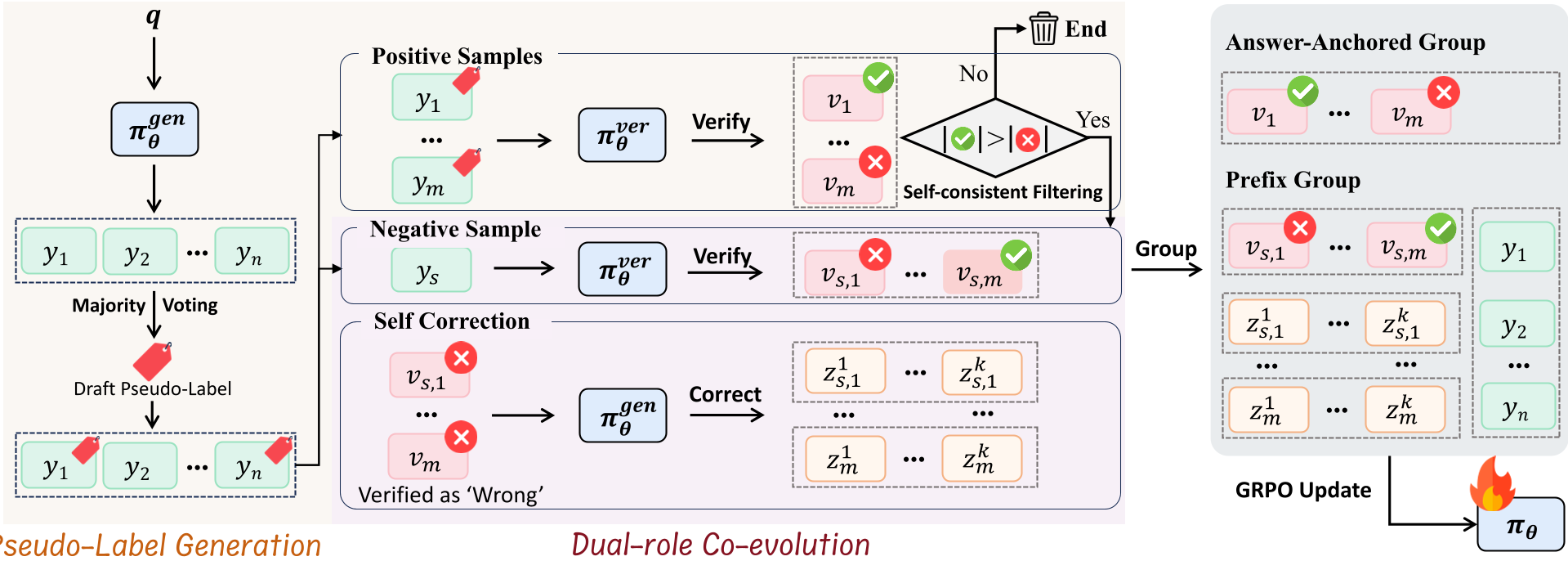
Methodology: Multi-Turn RL and Answer-Anchored GRPO
CoVerRL uses a unified multi-turn RL process:
- Role 1 (Generator): Produces N paths and identifies the majority answer.
- Role 2 (Verifier): Scrutinizes the reasoning. If the verifier disagrees with the majority, that sample is filtered out to avoid corrupting the model.
- Role 3 (Self-Correction): If the verifier flags an error, the model is triggered to generate a revised solution.
To optimize this, they use Answer-Anchored GRPO. Unlike standard GRPO which groups by prefix, this method groups verification paths by their target answer. This reduces variance and allows the model to learn that many different reasoning paths can lead to the same (correct) conclusion.
Results: True Reasoning Emerges
The experiments on MATH500, AMC, and AIME24 show a clear pattern: CoVerRL doesn't just "guess" better; it reasons better.
- Accuracy Boost: Average improvements of ~5% across all benchmarks.
- Verifier Skill: Verification accuracy on Qwen2.5-7B jumped from 54% to 86.5%.
- Transferability: When tested on RewardBench, the 3B Llama-3.2 model trained with CoVerRL scored 70.0, outperforming the much larger Llama-3-70B and GPT-4 Turbo. This proves the model learned principles of logic, not just dataset-specific shortcuts.
Critical Analysis: Why This Matters
The most fascinating part of CoVerRL is the Balanced Training and the Auto-Curriculum Effect. The authors mathematically prove that by balancing positive and negative verification samples, the Group Relative Policy Optimization (GRPO) naturally focuses on the "hard" samples where the model is uncertain, effectively creating an automated curriculum.
Limitations: The method relies on the model having a "Thinking Mode" (long-chain reasoning). Without it, the verifier suffers from "length collapse"—it stops explaining itself and just outputs "Correct/Wrong," causing the co-evolution to fail.
Conclusion
CoVerRL proves that ground-truth labels are not the ceiling for LLM intelligence. By pitting a model's internal logic (Verifier) against its statistical consistency (Generator), we can create a virtuous cycle of self-improvement. For the future of AGI, this suggests that the path to "Superintelligence" may lie in the model's ability to doubt its own consensus.