The paper introduces CoVR-R, a reasoning-first, zero-shot framework for Composed Video Retrieval (CoVR) using Qwen3-VL-8B. It moves beyond keyword matching by explicitly predicting "after-effects"—causal and temporal consequences of an edit (e.g., state transitions, motion, and camera shifts)—achieving a +10.1% R@1 improvement over the previous SOTA on the Dense-WebVid-CoVR benchmark.
TL;DR
Composed Video Retrieval (CoVR) — finding a video based on a reference clip and a text edit — has long been stuck in a "keyword matching" rut. CoVR-R changes the game by introducing a reasoning-aware framework that predicts the after-effects of an edit. By asking "What happens next?" before searching, this zero-shot approach boosts retrieval accuracy by over 10% on dense benchmarks without any task-specific training.
The Gap: Why Keywords Aren't Enough
Imagine you have a video of someone chopping vegetables and you provide the edit: "Now stir them in a frying pan."
Traditional models look for the word "stir" and "pan." However, a truly successful retrieval needs to understand the implicit consequences:
- State Change: Vegetables go from whole to diced.
- Temporal Phase: The action moves from the cutting board to the stovetop.
- Cinematography: A "close-up" might be implied to see the sizzling texture.
Prior SOTA methods often fail here because they treat the text edit literally, ignoring the causal and temporal "chain of events" that connects the source video to the target.
Methodology: Reason-then-Retrieve
The authors propose a two-stage pipeline that leverages the emergent reasoning of Qwen3-VL.
1. Structured After-Effect Inference
Instead of directly matching the edit, the model generates a Reasoning Trace (R). This trace is constrained by a schema covering:
- States: e.g., "raw to browned."
- Actions: e.g., "chopping to stirring."
- Scene: e.g., "outdoor to indoor."
- Camera: e.g., "zoom in to close-up."
- Tempo: e.g., "slow motion to fast-paced."
2. Importance-Weighted Embedding
To convert these text descriptions into searchable vectors, the paper uses a Lexical Category-based weighting scheme. It assigns higher importance () to action verbs and object nouns while down-weighting "filler" words like "the" or "is." This ensures the retrieval embedding is anchored in the most discriminative visual cues.
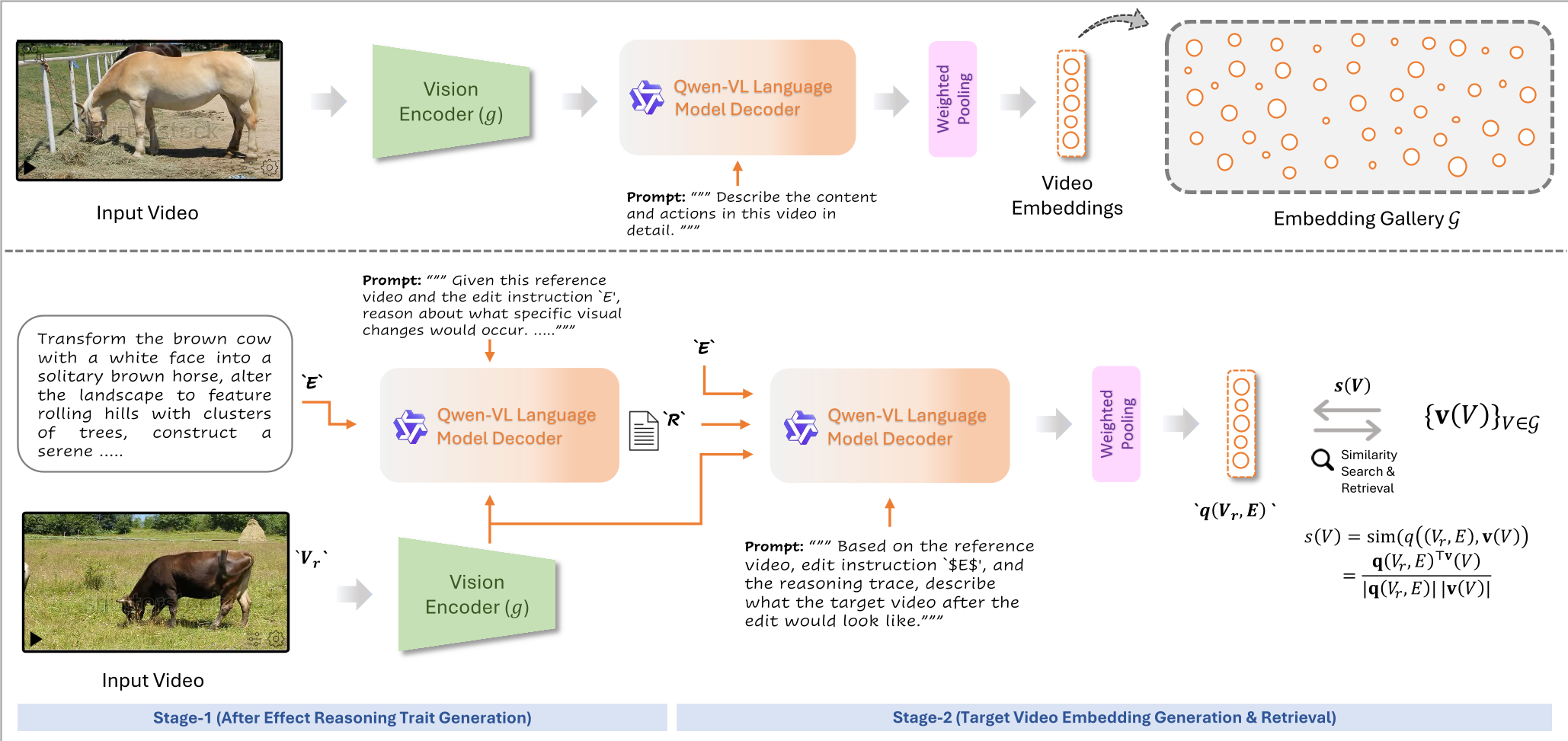 Figure 1: The two-stage architecture showing how reasoning traces guide the generation of the final query embedding.
Figure 1: The two-stage architecture showing how reasoning traces guide the generation of the final query embedding.
The CoVR-R Benchmark: Testing True Intelligence
To prove that reasoning matters, the authors released CoVR-R, a dataset of 2,800 triplets. Unlike previous sets, it includes "hard distractors"—videos that might look similar or share keywords but fail the causal/temporal logic of the edit.
Experimental Results
The results confirm that "thinking" pays off:
- Zero-Shot Supremacy: On the Dense-WebVid-CoVR test set, CoVR-R achieved 61.21% R@1, outperforming the previous supervised SOTA (BSE-CoVR) by a significant margin.
- Reasoning vs. Scale: Interestingly, the 8B parameter model performs remarkably well, though performance scales up to 55.48% R@1 with a 72B backbone.
- The Verbosity Trap: A key ablation study (Table B) revealed that more reasoning isn't always better. "Verbose" traces (186 tokens) actually performed worse than "Standard" traces (89 tokens), as excessive detail introduces noise that dilutes the retrieval signal.
 Table 1: Comparison across different backbones and fusion strategies on the CoVR-R benchmark.
Table 1: Comparison across different backbones and fusion strategies on the CoVR-R benchmark.
Critical Insights & Future Outlook
Why does it work? The core insight is that LMMs are excellent "simulators" of visual physics. By forcing the model to describe the target video before searching, we bridge the gap between abstract text and pixel-level dynamics.
Limitations: The model still struggles with hyper-specific edits (e.g., replacing a specialized pharmacy sign). In these cases, the model captures the "semantic gist" (an urban sign) but loses the exact text specificity required for a Top-1 match.
The Road Ahead: The paper points toward Adaptive Routing. Not every query needs deep reasoning. Simple edits like "make the car blue" can be handled by cheap keyword models, while complex "state-transition" queries should be routed to the expensive reasoning engine. This balance between efficiency and intelligence is the next frontier for explainable video search.
Summary Takeaway: CoVR-R proves that for video retrieval, understanding the consequences of an action is just as important as understanding the action itself.