本文系统性地综述了大型语言模型(LLM)在强化学习(RL)中的信度分配(Credit Assignment, CA)方法,涵盖了从单轮推理(Reasoning)到多轮智能体(Agentic)及多智能体(Multi-Agent)的演进。文章调研了 2024 年至 2026 年间的 47 种方法,提出了基于粒度和方法论的二维分类法,并指出事后反思(Hindsight)和特权评论家(Privileged Critic)是解决长路径智能体信度分配的关键 SOTA 趋势。
TL;DR
在强化学习(RL)训练大模型的下半场,我们正面临从“结果导向”向“过程理解”的范式转移。本文深度解读了 2026 年最新的 RL 综述,探讨了当 Trajectory 长度从 500 扩张到 100 万个 Token 时,如何精准判断哪一个“决策点”才是成功的功臣。
核心成就:
- 梳理了 47 种前沿 CA 方法。
- 揭示了智能体 RL 中“回声陷阱”的成因。
- 提出了未来超长路径(Long-horizon)训练的演进路线。
1. 痛点:为什么“结果正确”还不够?
目前的 LLM 强化学习(如 DeepSeek-R1)广泛采用 GRPO。其逻辑简单粗暴:如果最后答案对了,给所有 Token 发奖金;如果错了,全员受罚。
但是在 智能体(Agentic RL) 场景下,这会引发灾难:
- 信噪比崩塌:一个复杂的软件开发任务(SWE-bench)可能涉及 100 轮交互、50 万个 Token。第 3 轮的一个致命 API 调用错误,会被第 99 轮的正确格式化操作掩盖。
- 非确定性环境:外部工具的返回是随机的,传统的 Monte Carlo 采样(如 VinePPO)因无法重置环境(Checkpointing)而失效。
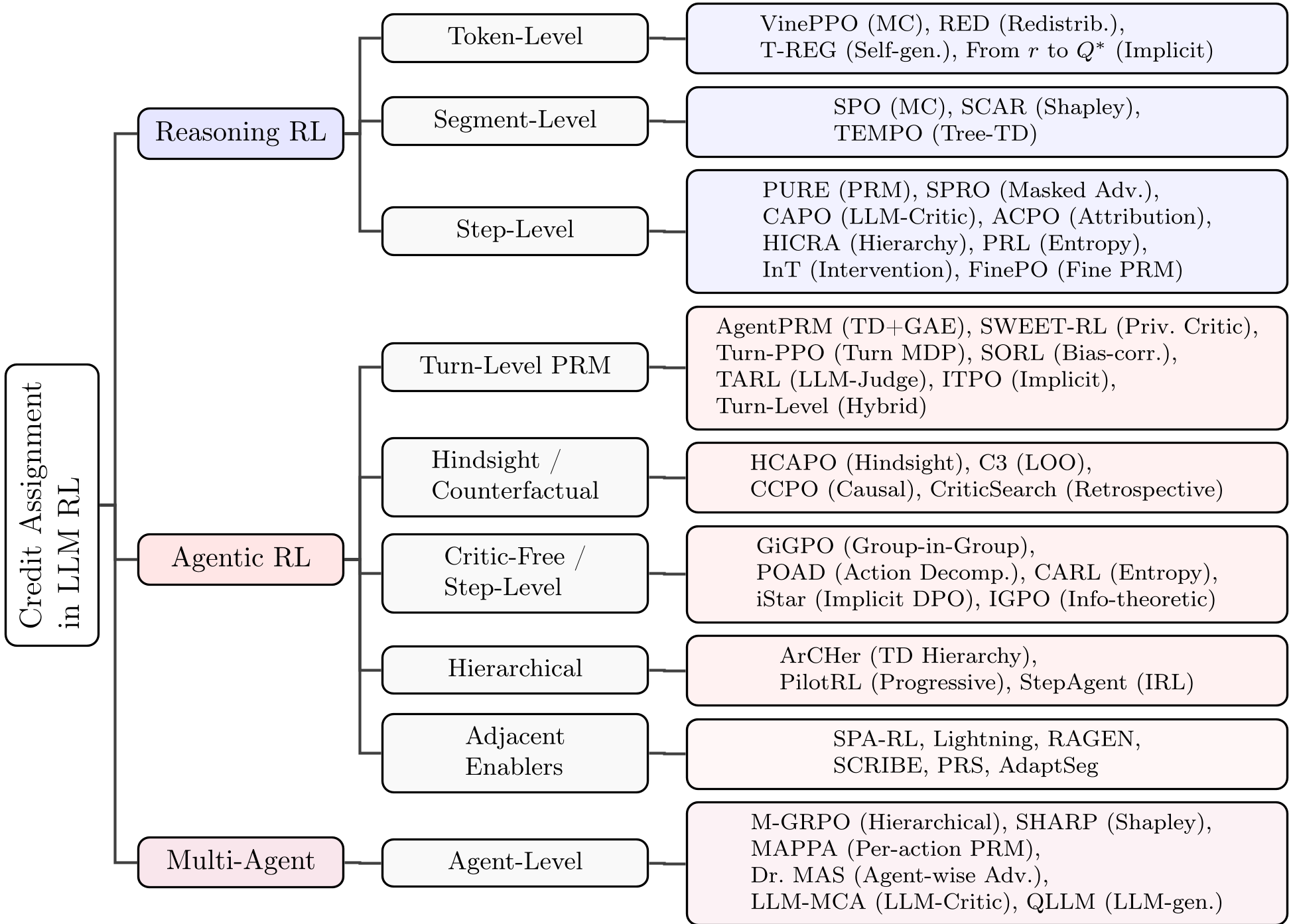
2. 方法论:二维坐标系下的技术谱系
作者提出了一套极其严密的分类法,将 CA 问题的解法划分为两个维度:粒度(Granularity) 与 手段(Methodology)。
2.1 架构演进:从 Token 到 Turn
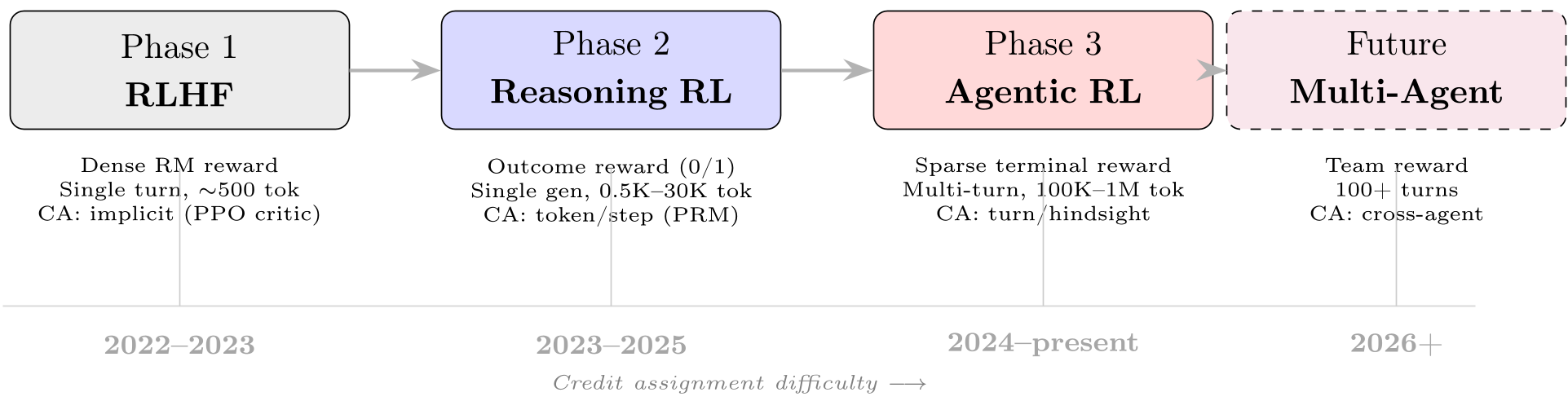
在推理任务中,重点是 Token 或步骤级 的过程奖励模型(PRM)。而在智能体任务中,轮次(Turn) 成为了自然的基本单位。Turn-PPO 和 ArCHer 等方法通过在 Turn 级别构建 MDP,有效过滤了 Token 级别的噪声。
2.2 核心算法:LLM 作为自己的法官
综述中一个显著的趋势是 LLM-as-Critic。不同于传统 RL 中需要拟合一个复杂的 Value Network,现在的 SOTA 方法直接利用 LLM 的语义能力:
- HCAPO (事后反思):在轨迹完成后,让 LLM “复盘”:“如果当时没点那个链接,结果会变吗?”
- CARL (关键动作识别):利用动作熵(Action Entropy)识别关键决策点(Bifurcation Points),只对这些 20% 的节点进行梯度更新,效率提升 72%。
3. 实验对比:谁是真正的 SOTA?
论文对比了多项核心战绩,结论一目了然:精细化的信度分配是高性能的代名词。
- 推理场景:SPO(分段策略优化) 在 MATH 任务上比 GRPO 提升了 7.6%,证明了将 CoT 切分为语义段进行信度计量的有效性。
- 智能体场景:AgentPRM 引入了 TD 学习和 GAE 高级优势估计,在 WebShop 等任务上比传统的采样方法(ORM)效率高出 8 倍。
4. 深度洞察:智能体 RL 的特殊挑战
相比推理任务,智能体 RL 的信度分配面临三大“幽灵”:
- 部分可观测性(POMDP):智能体看不到数据库全貌,必须识别哪些动作是为了“获取信息”。
- 特权评论家(Privileged Critic):在训练时,评论家可以看到正确答案,而智能体看不到。SWEET-RL 利用这种非对称信息,为智能体提供了上帝视角的引导。
- 分岔点问题:绝大多数动作(如排版、确认)是冗余的。如何精准定位那 1% 决定生死的动作,是未来大规模 Agent 训练的核心。
5. 总结与展望
信度分配正在从“数学公式”转向“语义分析”。 在 2026 年的节点看,未来的 RL 训练将不再仅仅是算力的堆砌,而是对轨迹中因果链条的深度挖掘。
未来的三个方向:
- 超长路径处理:应对 1000 步以上的多天任务。
- CA 与探索的耦合:让智能体去探索那些“信度最模糊”的区域。
- 多智能体博弈:解决“三个和尚没水喝”的责任追究问题(SharpValue 方法)。
资深主编点评:这篇综述不仅仅是论文的堆砌,它预言了 LLM 训练的下一个瓶颈点。如果说 2024 年是推理(Reasoning)之年,那么 2026 年必将是智能体(Agentic)在信度分配技术加持下真正落地的元年。