CT Open is a live, open-access platform and dynamic benchmark for Clinical Trial Outcome Prediction (CTOP). It introduces four quarterly challenges per year and utilizes a novel, expert-validated decontamination pipeline to ensure evaluated trials have no publicly available results at the time of prediction, achieving SOTA-level contamination resistance.
TL;DR
Predicting whether a clinical trial will succeed is a billion-dollar question. CT Open is a new "live" platform that challenges AI systems to predict trial outcomes before they are announced. By using a sophisticated, multi-stage automated decontamination pipeline, it ensures the AI isn't just "remembering" a result it saw during training, but is actually reasoning about drug mechanisms and trial designs.
The Problem: The "Memory" vs. "Intelligence" Trap
In the world of Large Language Models (LLMs), today's SOTA (State of the Art) might just be tomorrow's training data. Static benchmarks are rapidly losing their utility because models eventually ingest the answers. In high-stakes fields like clinical trials, this is particularly dangerous: an LLM might appear to possess "medical intuition" when it is actually just recalling a 2023 press release.
The authors of CT Open identify a critical nuance: Contamination is not just a database problem. Clinical trial results leak in fragments—an obscure LinkedIn post from a researcher, a blurry photo of a conference poster, or a financial disclosure. Standard registry checks are insufficient to guarantee a "blind" prediction.
Methodology: The Decontamination Fortress
The core innovation of CT Open is its Decontamination Pipeline (Algorithm 1). Unlike past benchmarks that simply check dates on ClinicalTrials.gov, CT Open treats data cleaning as an adversarial search task.
1. The Multi-Layer Search
The pipeline employs a "Global Search" strategy across several modes:
- LLM Mode: Orchestrating GPT-5 and Gemini 3 to browse the web for any mention of results.
- Brave Mode: A customized technical scraping stack that uses deep-web search and DeepSeek OCR to read text within PDFs and images.
- Database Mode: Direct API querying of PubMed, PMC, and preprint servers.
2. The Verification Loop
Once a document is found, it undergoes a two-round GPT-5 verification:
- Round 1 (Matching): Does this document discuss this exact trial? (Checking NCT IDs, drug aliases, and enrollment counts).
- Round 2 (Evidence): Does it actually contain results, or is it just a recruitment announcement?
 Figure 1: The CT Open platform architecture and leaderboard samples.
Figure 1: The CT Open platform architecture and leaderboard samples.
Experiments: Humans and Trad-ML Still Rule
The paper's evaluation phase delivers a sobering "vibe check" for LLM enthusiasts.
Key Findings:
- Traditional Baselines Persist: Simple Random Forests and Feed-Forward Neural Networks (FFNN) trained on structured tabular data (Phase, Enrollment count, MeSH terms) often outperformed the world's most powerful LLMs.
- The Contamination Dip: When Claude Opus 4.5 was tested on the "Winter 2025" set (potentially within its training cutoff), it performed excellently. However, on the "Summer 2025" set—which is strictly uncontaminated—its performance plummeted significantly.
- The Power of Agents: Agentic workflows (o3-mini with web access) showed a unique ability to find "dark data." In one instance, the agent found a patient blog that provided anecdotal evidence of a trial's failure, allowing it to predict a "Comparative Effect" outcome with near-perfect accuracy (reaching 92.75% in specific categories).
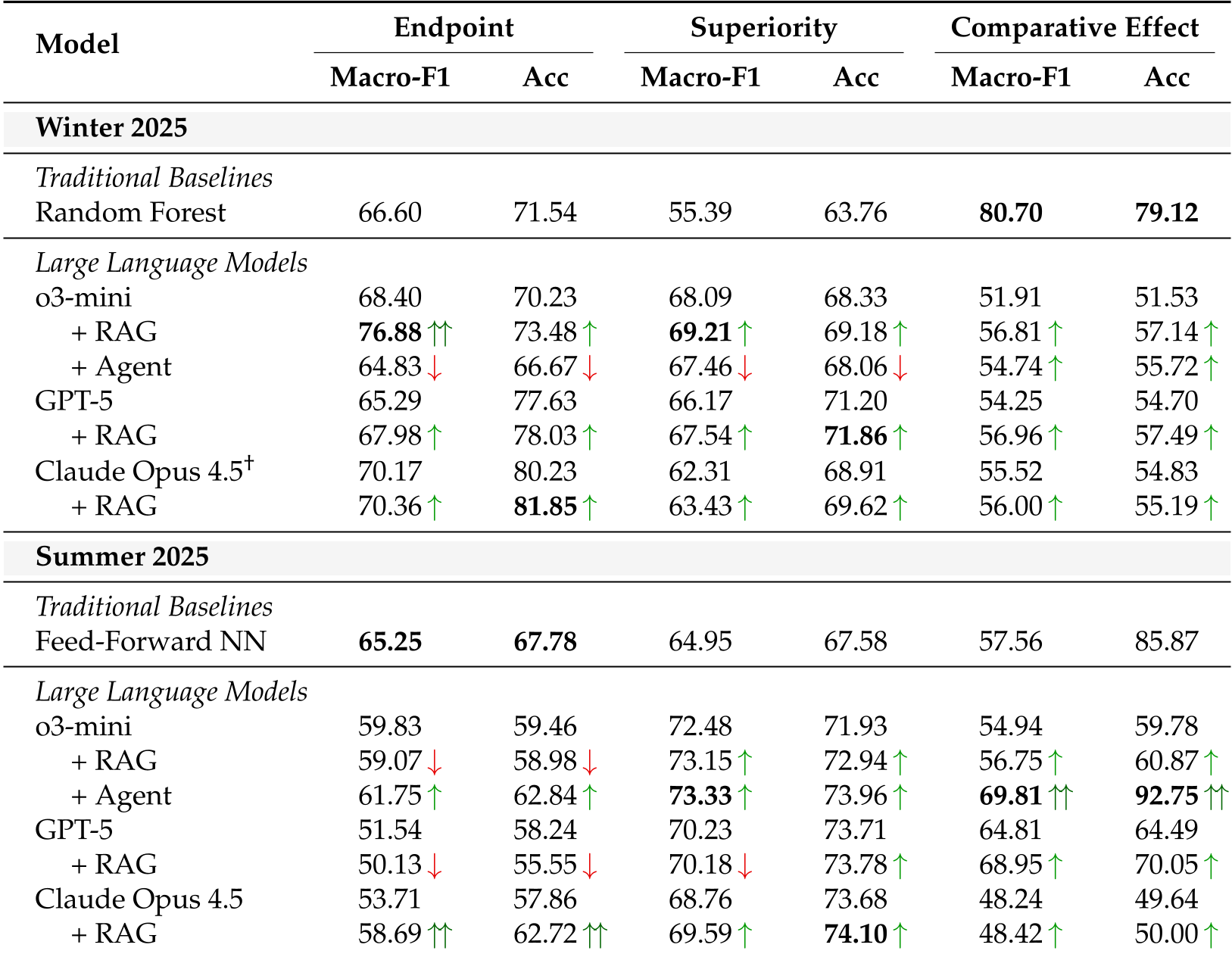 Figure 2: Performance comparison showing the drop in LLM accuracy on the Summer 2025 benchmark.
Figure 2: Performance comparison showing the drop in LLM accuracy on the Summer 2025 benchmark.
Methodology Deep Dive: Agentic Search and RAG
The authors explored whether Retrieval-Augmented Generation (RAG) could bridge the gap. Interestingly, generic retrieval of "preclinical evidence" (like animal studies) often hurt performance. The most effective strategy was "Me-Too" Trial Retrieval: finding previously completed trials of similar drugs in the same disease class. This requires the model to reason: "If drug A failed in this population, why would drug B (the target) succeed?"
Critical Analysis & Conclusion
CT Open is more than just a leaderboard; it is an infrastructure for Forecasting AI.
Takeaway: The study proves that "off-the-shelf" LLMs are not yet reliable biological oracles. They struggle to handle structured tabular data (like patient eligibility) as effectively as classical ML, and they are highly dependent on whether the "answer" was already part of their training set.
The Future: As AI moves toward "AI Scientists" and "Auto-Research," platforms like CT Open will be the ultimate proving ground. The next frontier isn't just processing what we know—it's predicting what we don't.
Platform Access: ct-open.net