本文推出了 CUA-SUITE,这是一个针对计算机使用智能体(CUAs)的大规模专业桌面任务数据集。核心包含 VIDEOCUA(55小时/600万帧 30fps 人类专家视频)、GROUNDCUA(5.6万张标注截图)及 UI-VISION 评测基准,旨在解决通用智能体在复杂桌面软件中感知与规划不佳的问题。
TL;DR
尽管 AI 智能体在处理网页任务时已游刃有余,但在面对 Blender、VS Code 或 FreeCAD 等专业桌面软件时却经常“抓瞎”。本文推出的 CUA-SUITE 填补了这一空白:它提供了超过 55 小时的 30fps 人类专家操作视频(VIDEOCUA)、像素级 UI 标注(GROUNDCUA)以及严苛的基准测试。研究表明,现有的最强模型在桌面软件上的失败率仍高达 60%,而 CUA-SUITE 的出现为构建真正的“视觉世界模型”铺平了道路。
痛点深挖:为什么桌面端是 GUI 智能体的“坟墓”?
在过去的几年里,我们看到了大量基于 WebArena 或 Android 任务的智能体,但桌面端(Windows/Linux/macOS)始终是一个顽疾,原因有三:
- 数据稀疏性:现有数据集多为“截图 A -> 动作 -> 截图 B”的离散模式,丢失了人类操作过程中极其关键的动态反馈和运动轨迹。
- UI 异构性:桌面专业软件充满了自定义绘制的画布、密集的工具栏和非标准的图标,传统的 Accessibility Tree(辅助功能树)往往无法正确解析。
- 空间定位偏差:模型可能知道要“点击另存为”,但在 4K 屏幕下,几十像素的偏移就足以导致任务失败。
Methodology:从原始视频到深度推理
CUA-SUITE 的核心直觉是:智能体应该像人类一样通过“看视频”来学习。
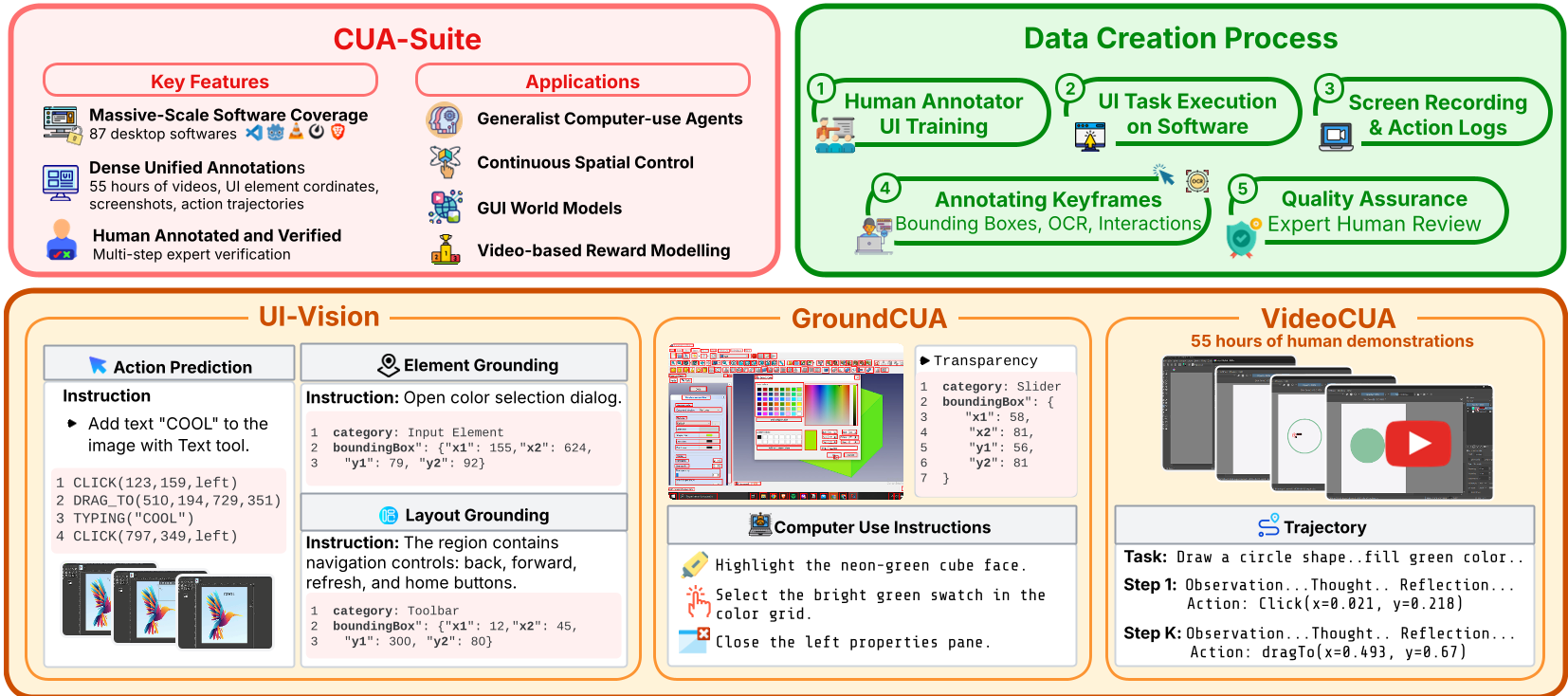
1. VIDEOCUA:连续性是硬道理
作者录制了 10,000 个任务,涵盖 12 个类别(开发、创意、财务等)。与以往不同,每一帧(30fps)都被保留,这意味着智能体可以学习到鼠标移动时的“减速惯性”和点击反馈的实时变化。
2. 多层推理标注(Multi-layered Reasoning)
为了弥补“动作”与“意图”之间的语义鸿沟,作者利用 Claude-4.5 对每一步生成了四层标注:
- 观察(Observation):屏幕上有什么?
- 思考(Thought):基于目标,我现在为什么要这么做?
- 动作(Action Description):自然语言化的动作描述。
- 反射(Reflection):动作后屏幕发生了什么变化?是否符合预期?
这种深度标注平均每步包含 497 个单词,为训练 Vision-Language-Action (VLA) 模型提供了极强的监督信号。
实验与结果:现状比想象中更严峻
作者测试了目前开源界最强的 OpenCUA-32B 模型,结果令人警醒:

- 空间定位失败:在 50 像素的容差下,准确率仅为 37.7%。这意味着模型经常在复杂的面板中“点错位置”。
- 语义与感知的倒挂:人机评估显示,模型在 85.9% 的情况下知道该“做什么动作”,但在定位目标元素时,准确率仅有 52.4%。
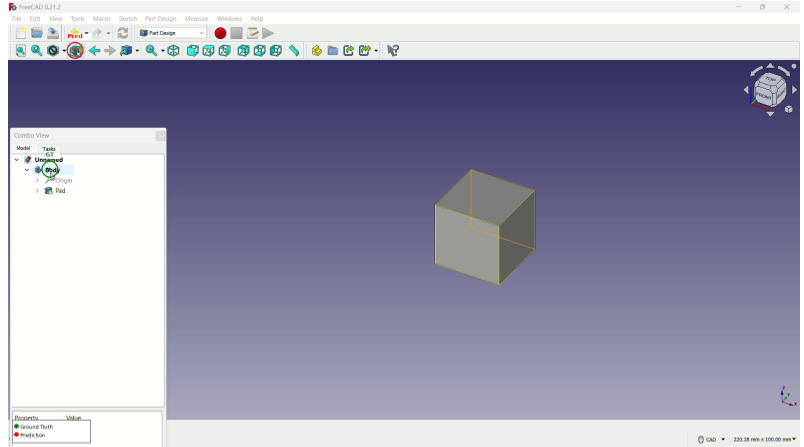 (a) Krita 绘图软件中的跨面板误触:模型在密集的工具栏中迷失了。
(a) Krita 绘图软件中的跨面板误触:模型在密集的工具栏中迷失了。
深度洞察:未来的 AI 助理会是什么样?
CUA-SUITE 的价值不仅在于刷榜,它开启了四个极具潜力的未来方向:
- 通才屏幕解析:不再依赖脆弱的 DOM 或辅助功能树,实现纯视觉的 UI 解析。
- 连续空间控制:让鼠标移动像真人一样平滑,而非瞬间“传送”,这对于实时交互至关重要。
- 视觉世界模型:基于视频流预判点击后的屏幕状态,实现“在大脑中预演”。
- 基于视频的奖励模型:自动判断复杂的专家操作是否成功完成,解决强化学习中的奖励稀疏问题。
总结
CUA-SUITE 证明了,要让 AI 真正接管我们的桌面办公,仅仅靠“看图说话”是不够的。它必须理解人类在操作专业软件时的空间厚度感和逻辑连贯性。这项工作的开源(数据+模型+Benchmark)将极大地推动桌面端通用智能体(Generalist CUAs)的进化。
主编点评:“这是一篇扎实的数据驱动工作。它直面了当前 GUI 智能体中最难的桌面端‘硬骨头’,其 30fps 的视频密度为下一代视觉规划模型提供了最珍贵的原料。”