本文提出了 CUBE (Common Unified Benchmark Environments),一种旨在统一 AI Agent 评测标准的通用协议。它结合了 MCP (Model Context Protocol) 的异步能力与 Gym 的强化学习语义,旨在解决当前 Agent 评测集因接口不一导致的集成碎片化问题。
TL;DR
随着 AI Agent 评测集在 2026 年迎来爆发式增长,研究人员正陷入深重的“系统工程泥潭”。本文提出的 CUBE (Common Unified Benchmark Environments) 是一套通用的协议标准,它整合了 MCP 的异步工具调用能力与 Gym 的评测逻辑,让 Agent 评测集可以实现“一次包装,到处运行”。
1. 痛点:Agent 领域的“集成税”
在当前学术界,评估一个 Agent 的能力是一项极具挑战的工程任务。如果你想在 WebArena 上测试 Agent 的网页导航能力,又想在 SWE-bench 上考察它的代码修复能力,你不得不为每个环境编写完全不同的逻辑驱动。
这种现象被称为 集成税 (Integration Tax):
- 基础设施复杂性:有的环境需要 Docker,有的需要全量虚拟机(VM),有的需要实时联网。
- 接口不统一:有的通过 Shell 交互,有的通过 HTML 坐标,有的则是阻塞式的 Step 函数。
- 资源开销巨大:环境初始化慢、内存占用高,且难以在不同的云平台或超算集群中灵活迁移。
 表 1:四种主流 Agent 评测集在环境、托管和集成难度上的巨大差异
表 1:四种主流 Agent 评测集在环境、托管和集成难度上的巨大差异
2. 核心直觉:CUBE 的四层分层架构
CUBE 的设计哲学是**“解耦”**。它借鉴了计算机网络的协议层思想,将 Agent 与环境的交互分解为四个层次:
2.1 任务层 (Task Level) - MCP + Gym 的融合
传统的 Gym.step() 是阻塞式的,但在 Web 搜索或长时间编译任务中,Agent 不应该干等。CUBE 引入了 Model Context Protocol (MCP),支持异步动作执行。
- MCP 负责:工具发现、异步调用。
- Gym 负责:重置 (
reset)、评估 (evaluate)。 这种融合让 Agent 既能拥有灵活的工具箱,又能进行标准的强化学习训练。
2.2 评测集层 (Benchmark Level)
负责管理共享的基础设施。例如,WebArena 需要一个后台运行的 GitLab 服务器供所有任务共享,CUBE 通过 cube/spawn 和 cube/shutdown 统筹这些资源的生命周期。
2.3 包管理层 (Package Level)
CUBE 实现了“声明式”资源配置。评测集作者只需声明需要多少 RAM、是否需要 Docker,而具体的部署方式(是在本地运行,还是在 Kubernetes 集群运行)则交给 CUBE 的后端插件处理。
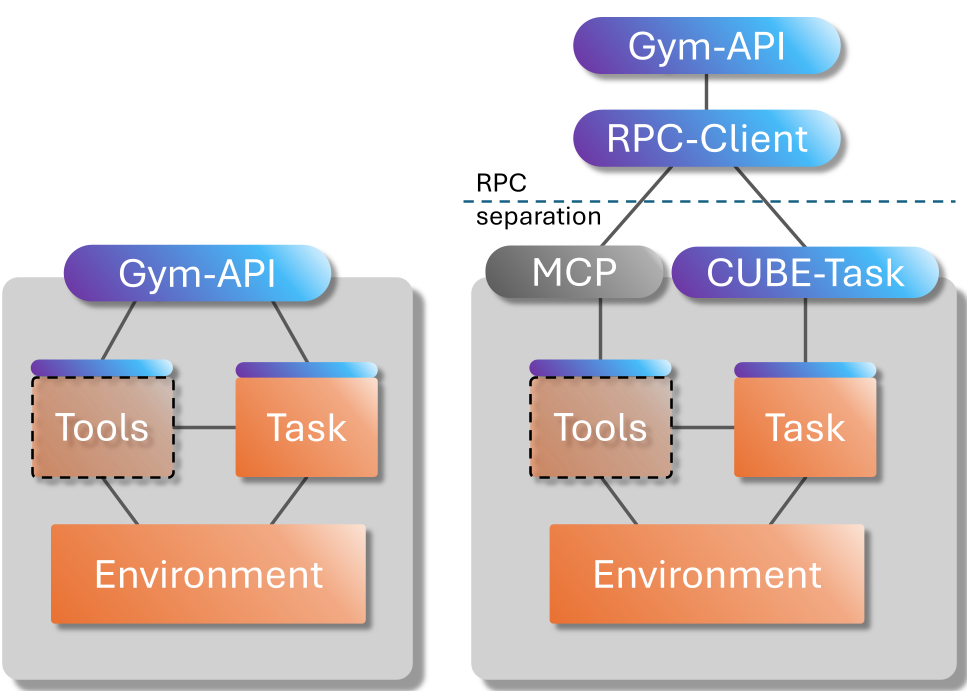 图 1:CUBE 命令流:左侧为逻辑解耦,右侧为 Python 与 RPC 的自动双层包装
图 1:CUBE 命令流:左侧为逻辑解耦,右侧为 Python 与 RPC 的自动双层包装
3. 实验验证:跨越孤岛的桥梁
CUBE 并不只是纸上谈兵。作者展示了如何利用一套统一的 API 对接多种异构平台:
- 性能评估:通过 RPC 方式提供灵活性,通过 Python 直接调用模式消除序列化耗时,满足高频 RL 训练需求。
- 调试工具:每个 CUBE 包都必须自带
Debug Task和Debug Agent。这意味着你不需要消耗任何 LLM Token,就能通过一个脚本化 Agent 验证环境是否安装正确。
 表 5:CUBE 与 NeMo Gym, AgentBeats, OpenEnv 等主流平台的差异化定位
表 5:CUBE 与 NeMo Gym, AgentBeats, OpenEnv 等主流平台的差异化定位
4. 深度洞察
CUBE 的核心贡献不在于发明了某种强大的算法,而是在于它确立了 Agentic Stack 的边界。
为什么这很重要? 如果每个平台都试图建立自己的封闭生态(例如只支持自家的 Docker 格式),那么小团队提出的创新评测集将永远无法获得可见度,因为大实验室不愿花时间去集成它们。CUBE 提供的注册表 (Registry) 允许开发者一键发布自己的评测库,这种“去中心化”的发现机制将极大地促进 Agent 领域的民主化。
5. 局限与未来
尽管 CUBE 设计巧妙,其面临的最大挑战仍然是 Adoption (采用率)。
- 阻力:现有的成熟平台(如 NeMo Gym)可能有路径依赖,不愿轻易改写底层接口。
- 解决方案:作者通过建立早期的“联盟”并行包装了 9 个最常用的评测集,试图通过提供现成的“糖果”来吸引用户入场。
总结 (Takeaway)
CUBE 的野心是成为 Agent 界的 ImageNet 或 Hugging Face Transformers。在 Agent 已经能够自主操作系统的今天,我们确实需要一种像“USB 接口”一样的标准,让研究者从繁琐的驱动编写中解脱出来,回归到探索 AI 智能本质的道路上。