The paper introduces R-C2, a reinforcement learning framework that enhances Multimodal Large Language Models (MLLMs) by enforcing cross-modal cycle consistency. It achieves new SOTA performance on benchmarks like ScienceQA and ChartQA by using an autonomous, label-free reward signal to align visual and textual representations.
Executive Summary
TL;DR: Researchers from Rutgers, Columbia, and UChicago have unveiled R-C2 (Cross-Modal Cycle Consistency), a reinforcement learning framework that forces MLLMs to be "honest" across sensory inputs. By requiring a model to reconstruct its own reasoning path in a loop (Image $\rightarrow$ Query $\rightarrow$ Text $\rightarrow$ Answer), R-C2 eliminates the need for expensive human labels and outperforms traditional voting mechanisms by up to 7.6 points across major benchmarks.
Background Orientation: This work sits at the intersection of Self-Supervised Learning and Multimodal Alignment. While most current SOTA models rely on scaling up instruction-tuning data, R-C2 suggests that the "modality gap"—the phenomenon where a model contradicts itself when looking at a picture vs. reading text—is actually a feature, not a bug, providing a dense signal for self-improvement.
The Problem: The "Majority-is-Wrong" Trap
In theory, an MLLM should give the same answer whether it "sees" a chart or "reads" the underlying data table. In practice, they fail miserably. When models are used for self-improvement, they typically rely on Majority Voting—if 3 out of 5 rollouts say "A," the model assumes "A" is correct.
However, as the authors point out, if the model has a systematic bias in its vision encoder, the majority will simply be consistently wrong. In multimodal settings, this is compounded: a model might be 100% confident in its (incorrect) visual interpretation while its textual interpretation is correct but outnumbered.
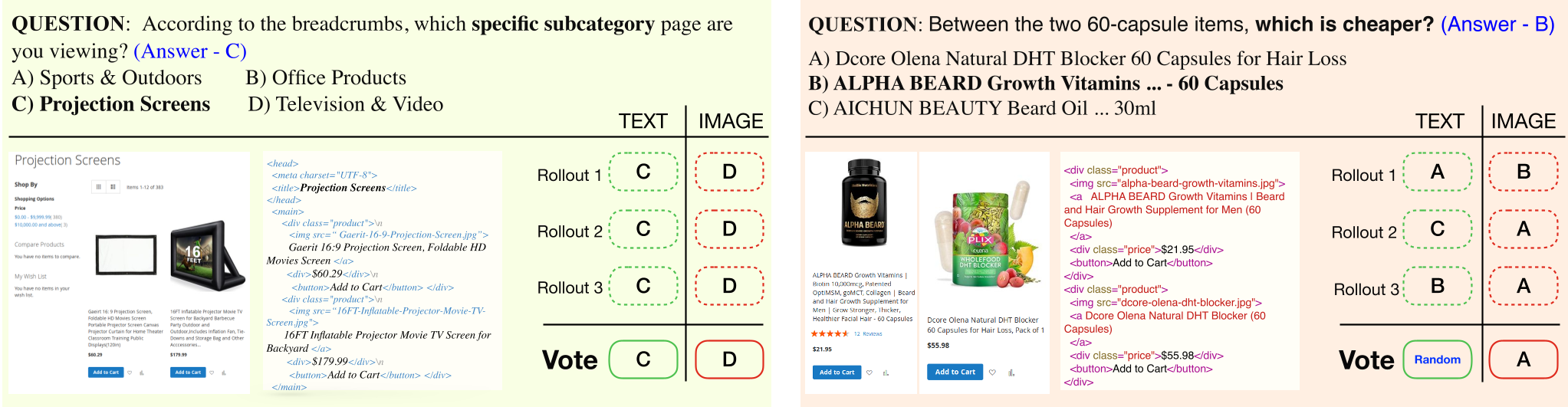 Figure 1: Traditional voting leads to "Consistent Conflict" where systematic bias is reinforced.
Figure 1: Traditional voting leads to "Consistent Conflict" where systematic bias is reinforced.
Methodology: The 4-Way Reasoning Cycle
R-C2 moves from consensus-based rewards to verification-based rewards. Instead of just asking "What is the answer?", R-C2 asks, "If this is the answer, can I reconstruct the question using a different modality and still get back to this answer?"
The R-C2 Workflow:
- Candidate Selection: Start with an answer ($a_{orig}$).
- Backward Inference: Generate a query ($q$) that would lead to that answer, given a specific modality (e.g., looking at an HTML source).
- Cross-Modal Forward Inference: Switch to the opposite modality (e.g., looking at a Screenshot) and try to answer that generated query.
- Reward: If the reconstructed answer matches $a_{orig}$, the model receives a binary reward $+1$.
By utilizing all four paths ($T \rightarrow T, T \rightarrow I, I \rightarrow T, I \rightarrow I$), the model is forced into a state of Inductive Bias where visual and textual markers must map to the same semantic latent space.
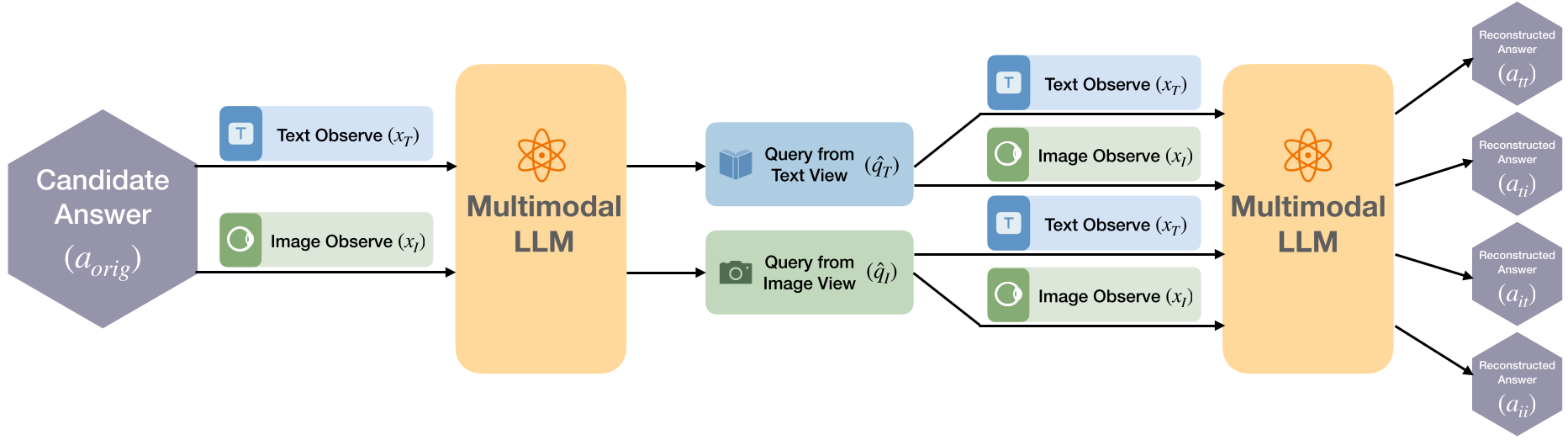 Figure 2: The 4-way cross-modal reasoning cycle ensures both internal stability and cross-modal alignment.
Figure 2: The 4-way cross-modal reasoning cycle ensures both internal stability and cross-modal alignment.
Experiments: SOTA Achievements
The authors tested R-C2 on Qwen2.5-VL-3B and Qwen3-VL-8B. The results demonstrate that R-C2 isn't just "flavor text"—it drives hard performance gains:
- ScienceQA: +7.8% (Text) and +7.3% (Vision).
- MathVista: +6.0% improvement in visual mathematical reasoning.
- Consistency Ratio: On A-OKVQA, the agreement between modalities jumped by 12.5 points, proving that the model is no longer "guessing" differently based on the input format.
Ablation Insight: The Power of Conflict
One of the most profound findings in the paper is shown in the image below. The researchers found that as they increased the ratio of inconsistent data (samples where modalities disagreed) in the training set, the model's performance actually improved.
 Figure 3: Harder examples (cross-modal disagreements) provide a stronger training signal for the RL objective.
Figure 3: Harder examples (cross-modal disagreements) provide a stronger training signal for the RL objective.
Critical Analysis & Conclusion
Takeaway
The industry's obsession with "more data" often overlooks the quality of the model's internal logic. R-C2 proves that we can bootstrap super-intelligence in MLLMs by simply demanding they be consistent. It turns the "modality gap" into a self-supervised classroom.
Limitations
While highly effective, R-C2 currently relies on an offline strategy (pre-generating cycle data) to remain computationally efficient. An online, "on-the-fly" cycle generation might yield even higher gains but requires significant GPU optimization.
Future Outlook
This methodology paves the way for truly autonomous agents. In environments like the Visual Web Arena, where an agent must handle both UI screenshots and DOM trees, R-C2 provides the stability needed for reliable long-horizon reasoning without needing a human to label every single step.