SITH (Semantic Inspection of Transformer Heads) is a data-free and training-free interpretability framework that analyzes CLIP's Vision Transformer in weight space by decomposing Value-Output (VO) matrices into singular vectors. Using the novel COMP (Coherent Orthogonal Matching Pursuit) algorithm, it maps these vectors to sparse, human-interpretable concepts, achieving SOTA results in fine-grained model editing and mechanistic understanding.
TL;DR
SITH (Semantic Inspection of Transformer Heads) is a revolutionary data-free and training-free framework for interpreting CLIP. Instead of looking at image activations, it looks directly at the model weights. By decomposing attention matrices using SVD and a new algorithm called COMP, SITH identifies specific "concept vectors" inside attention heads. This allows for surgical model edits—like removing bias or NSFW content—simply by zeroing out specific singular values.
Impact: This work shifts mechanistic interpretability from a dataset-heavy task to a pure linear algebra problem, proving that CLIP’s weights are a direct map of human concepts.
The Motivation: Interpretation Without Bias
Most interpretability tools (like Sparse Autoencoders) are dataset-dependent. If your probe dataset is biased, your interpretation is biased. Furthermore, identifying that a "head" likes "colors" is too coarse. We need to know which specific feature inside that head represents "Fire-Engine Red" vs "Navy Blue."
SITH solves this by bypassing data entirely, looking at the Weight Space.
Methodology: The Core Mechanics
1. Weight Matrix Factorization
SITH focuses on the Value-Output (VO) matrix ($W_{VO}$) of each attention head. In the Transformer "circuit" view, the VO matrix determines what information is written into the residual stream.
SITH applies Singular Value Decomposition (SVD): $$W_{VO} = U \Sigma V^T$$
- Left Singular Vectors ($u_i$): What the head "reads" from the input.
- Right Singular Vectors ($v_i$): What the head "writes" to the output.
- Singular Values ($\sigma_i$): The technical "strength" or importance of that feature.
2. COMP: Making Math Human-Readable
To turn abstract vectors into words, the authors developed COMP (Coherent Orthogonal Matching Pursuit). Standard matching pursuit just looks for the best mathematical fit. COMP adds a coherence term to ensure the words chosen make sense together (e.g., "sea," "ocean," and "beach" instead of "sea," "toaster," and "politics").
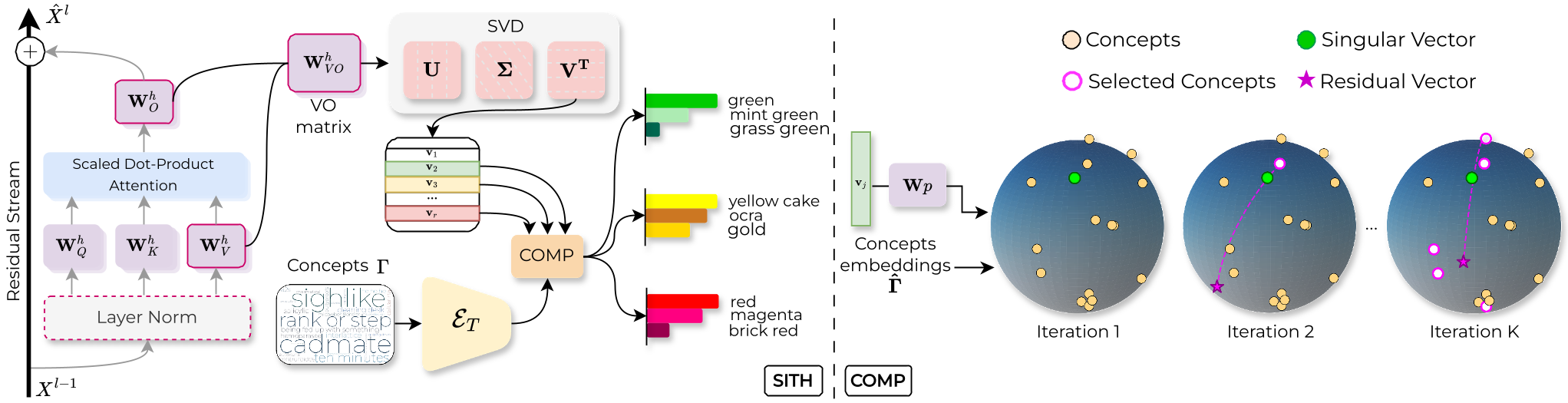 Figure 1: The SITH pipeline—from VO weight matrices to coherent concept clusters via SVD and COMP.
Figure 1: The SITH pipeline—from VO weight matrices to coherent concept clusters via SVD and COMP.
Interpretable Model Editing: Performance Results
Because SITH maps specific weights to specific concepts, we can "edit" the model without retraining.
Anti-Bias and Safety
- Spurious Correlations: On the "Waterbirds" dataset (birds on wrong backgrounds), SITH identifies "background" vectors. Setting $\sigma_i = 0$ for those vectors improved accuracy significantly, outperforming head-level ablation methods like TextSpan.
- NSFW Filters: SITH identifies "unsafe" vectors. By suppressing them, the model becomes safer in retrieval tasks without losing general performance.
Fine-Tuning Insights
SITH reveals that when we fine-tune CLIP, we aren't learning new concepts. Instead, we are simply re-weighting the existing semantic basis. The "subspace shift" is subtle but task-aligned.
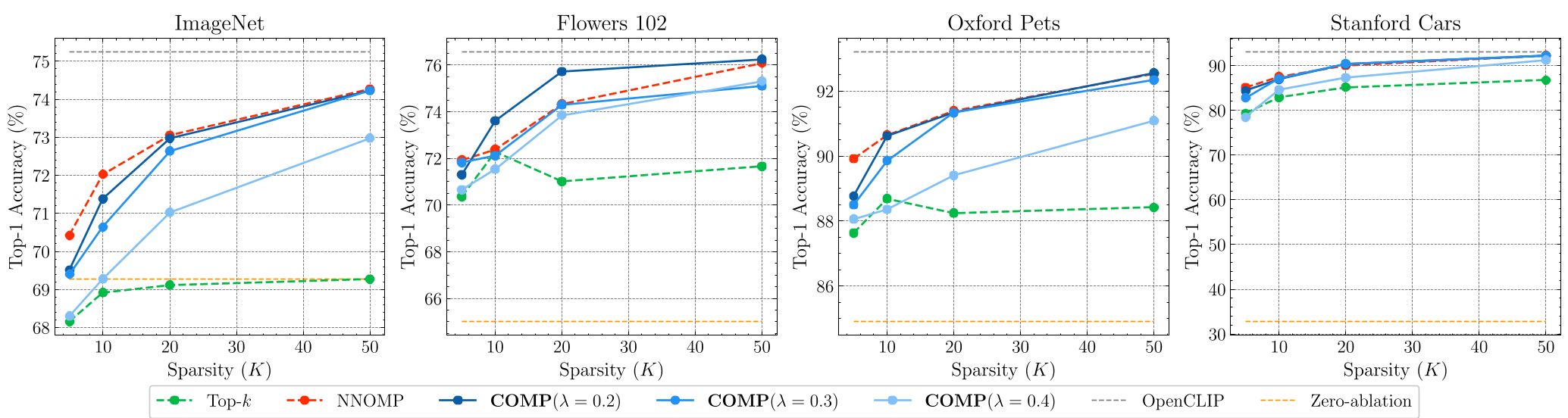 Figure 2: Substituting original singular vectors with SITH-reconstructed versions shows minimal loss in zero-shot accuracy, proving the fidelity of the decomposition.
Figure 2: Substituting original singular vectors with SITH-reconstructed versions shows minimal loss in zero-shot accuracy, proving the fidelity of the decomposition.
Visual Evidence: Grounding Weights
Does a weight vector actually "see" what we think it does? The authors retrieved images from CC12M that most resembled specific singular vectors. The results are startling: a vector identified as "Two Children" consistently retrieves images of pairs of kids.
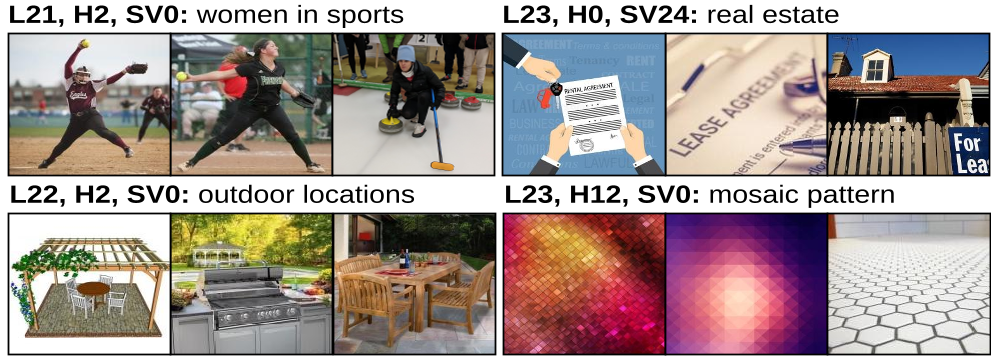 Figure 3: Top-3 images matched to singular vectors—confirming that the weight-based interpretations align with visual reality.
Figure 3: Top-3 images matched to singular vectors—confirming that the weight-based interpretations align with visual reality.
Deep Insight & Conclusion
The SITH framework is a masterclass in mechanistic interpretability. It proves that the "vision-language" alignment in models like CLIP is so robust that it is reflected directly in the geometry of its weights.
Takeaway: We no longer need massive datasets to understand or fix VLMs. By applying spectral analysis to model weights, we can achieve surgical, data-free interventions that make AI safer, more robust, and more transparent. The future of AI safety and adaptation may not lie in more data, but in better linear algebra.