DCARL is a novel divide-and-conquer autoregressive framework for long-trajectory video generation (up to 32 seconds). It combines a Keyframe Generator to establish global structural anchors with an Interpolation Generator for dense, coherent frame synthesis, achieving SOTA performance in visual quality and camera adherence.
Executive Summary
TL;DR: DCARL (Divide-and-Conquer Autoregressive Long-trajectory) is a new framework designed to generate stable, high-fidelity videos up to 32 seconds long. It solves the dreaded "visual drift" in autoregressive models by first generating a global "skeleton" of keyframes and then "fleshing out" the video through segment-wise interpolation.
Background: In the landscape of video generation, we have two main camps: Joint VDMs, which are high-quality but computationally heavy, and Autoregressive Models, which can generate "infinite" frames but eventually lose their way (drift). DCARL occupies a unique position as a hybrid, using a divide-and-conquer strategy to bring the stability of joint modeling to the scalability of autoregressive rollout.
The Problem: The Exponential Decay of Reality
Purely Autoregressive (AR) models suffer from Exposure Bias. During training, the model sees ground-truth past frames; during inference, it sees its own slightly imperfect previous frames. These errors compound. Mathematically, the paper proves that if the generator is $L$-Lipschitz continuous, the error grows linearly or even exponentially over time. This manifesting as "melting" objects, disappearing roads, or a total disregard for camera control signals.
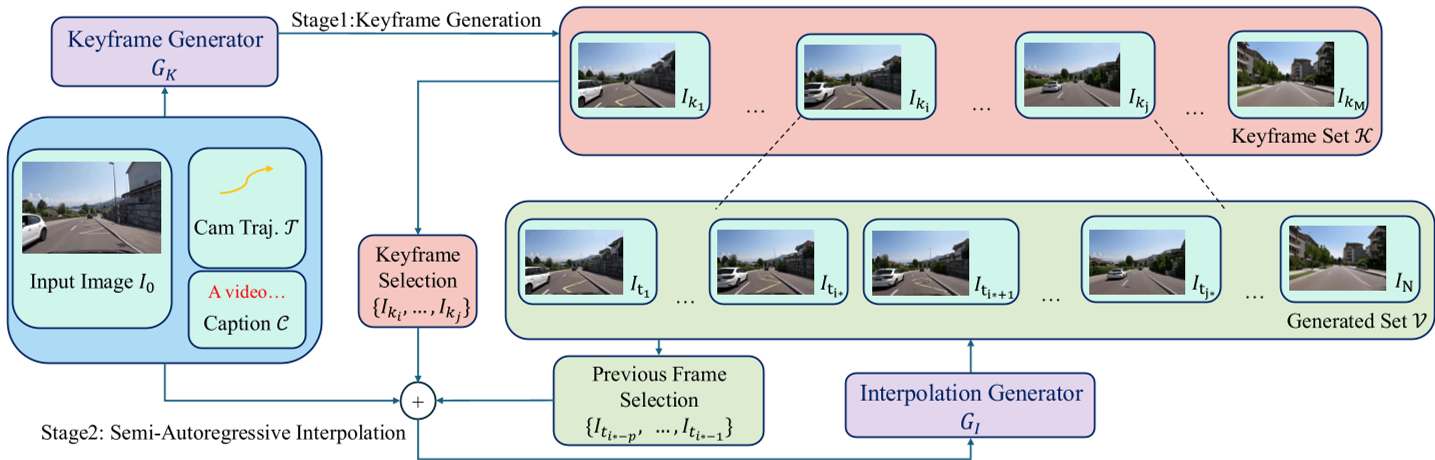
Methodology: Divide, Anchor, and Interpolate
The core philosophy of DCARL is that structure should be global, while details can be local.
1. Keyframe Generation (The Skeleton)
Instead of predicting frame by frame, the Keyframe Generator ($G_K$) predicts a set of sparse frames ($I_{k1}, I_{k2}, ...$) across the entire timeline simultaneously.
- Spatial Preservation: Crucially, the authors avoid temporal compression in the VAE for this stage. Why? Because temporal compression is lossy, and for sparse keyframes with big jumps, it destroys the geometric cues needed for camera control.
2. Interpolation Generation (The Muscle)
Once the keyframes are set, the Interpolation Generator ($G_I$) fills the gaps.
- Motion-Inductive Noisy Conditioning: A brilliant insight here is that models often get "lazy" and just copy-paste pixels from the keyframes. By adding noise to the keyframes during training, the model is forced to learn motion dynamics rather than just identity mapping.
- Seamless Boundary Consistency: To prevent "flickering" at the edges of segments, the model uses a latent substitution strategy, ensuring the transition from one segment to the next is mathematically smooth.
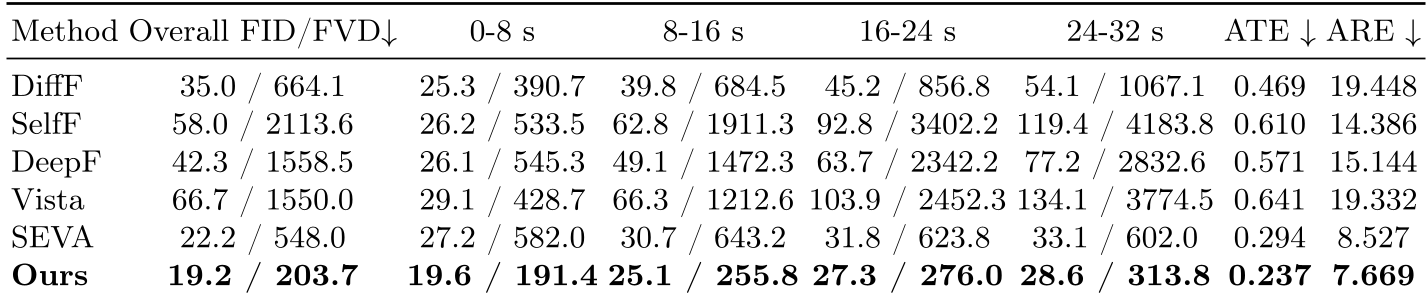
Experiments: Breaking the 30-Second Barrier
The authors tested DCARL on massive datasets like OpenDV-YouTube and nuScenes.
- Controllability: In metrics like Absolute Trajectory Error (ATE), DCARL maintains a tight grip on the intended path, whereas baselines like Diffusion Forcing or Vista begin to veer off as the sequence lengthens.
- Visual Stability: Looking at the FVD scores for segments (0-8s vs 24-32s), DCARL remains remarkably flat, while other models' quality falls off a cliff.
Critical Insights & Takeaways
The most impressive part of this work is the Perturbation Analysis in the appendix. It provides a formal proof that "anchoring" is not just a heuristic—it’s a mathematical necessity to bound the variance of the generative process.
Limitations:
- Long-distance Perception: The model still occasionally struggles with "hallucinated" geometry in complex roundabouts or underpasses.
- Latency: While faster than full-sequence joint DMs, it’s not yet real-time for interactive "video games" or simulators.
Future Outlook: DCARL sets a high bar for World Modeling. By proving that we can stabilize autoregressive diffusion with sparse anchors, it opens the door for minute-long, controllable synthetic environments that could revolutionize how we train autonomous vehicles and robots in simulation.
