DecoupleVS is a decoupled vector storage management framework designed for disk-based Approximate Nearest Neighbor Search (ANNS). By separating high-dimensional vector data from auxiliary index metadata, it introduces tailored lossless compression and latency-aware I/O scheduling, achieving up to 58.7% storage reduction while improving search throughput by up to 2.18x compared to state-of-the-art monolithic systems like DiskANN.
TL;DR
As vector datasets scale to the billion and trillion levels, "monolithic" storage—where vectors and their indices are packed together—is hitting a wall. DecoupleVS breaks this paradigm. By decoupling vector data from index metadata, it enables tailored lossless compression (XOR-delta + Elias-Fano) and a latency-aware search pipeline. The result? A massive 58.7% reduction in storage footprint and a 2x boost in search throughput without losing a single bit of precision.
The Problem: The High Cost of Co-location
Modern disk-based ANNS systems like DiskANN and SPANN typically store full-precision vectors and their neighbor lists together. While this simplifies I/O, it introduces three "hidden" costs:
- Space Inefficiency: Neighbor lists are often as large as the vectors themselves. Page-alignment requirements lead to internal fragmentation.
- Read Amplification: Graph traversal reads massive amounts of data, but only a fraction is used for the final re-ranking.
- Write Amplification: Updating a single vector requires rewriting entire index sections to keep the data co-located.
As SSD prices surge due to AI demand, these inefficiencies translate directly into massive operational costs.
Methodology: The Power of Decoupling
The core insight of DecoupleVS is that vectors and indices have different semantics and access patterns.
1. Tailored Lossless Compression
Instead of using general-purpose tools like LZ4, DecoupleVS exploits the physical properties of the data:
- For Vectors: It uses XOR-based delta compression. Since dimensions in normalized vectors often have similar byte-positional distributions, XORing against a "base vector" and then applying Huffman coding significantly reduces entropy.
- For Indices: Neighbor IDs are sorted and compressed using Elias-Fano encoding, a succinct data structure that allows for high compression while remaining searchable.
2. Hierarchical Storage Layout
To handle the variable-sized blocks created by compression, DecoupleVS introduces a segment -> chunk -> block hierarchy.
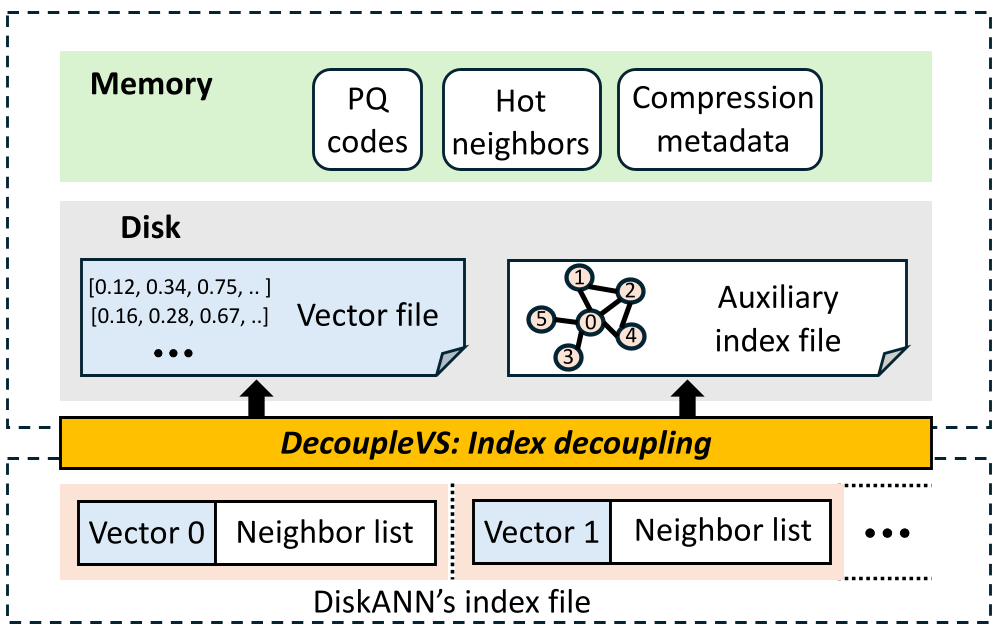 Figure: The DecoupleVS Architecture showing the separation of Vector Data (Segments) and Auxiliary Index.
Figure: The DecoupleVS Architecture showing the separation of Vector Data (Segments) and Auxiliary Index.
3. Latency-Aware Search Pipeline
DecoupleVS removes vector data I/Os from the critical path of graph traversal. It explores the graph using only the index and prefetches full-precision vectors only when the search "stabilizes." This adaptive prefetching ensures that the SSD's bandwidth is used for the most promising candidates.
Experimental Results: SOTA Performance
DecoupleVS was tested on billion-scale public and proprietary datasets.
Storage Savings: On a proprietary billion-scale dataset, DecoupleVS reduced storage by 58.7% compared to DiskANN. Even on pre-quantized datasets like SIFT100M, it saved over 40% by eliminating internal fragmentation and compressing the index.
Search Throughput:
By optimizing cache efficiency (more compressed neighbor lists fit in RAM) and pipelining I/Os, DecoupleVS achieved up to 2.58x throughput gain.
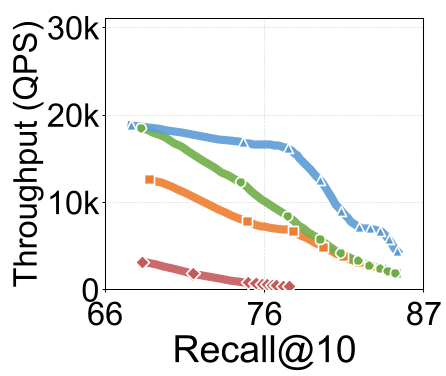 Figure: Search Throughput (QPS) vs. Recall@10. DecoupleVS (blue) consistently stays at the Pareto frontier.
Figure: Search Throughput (QPS) vs. Recall@10. DecoupleVS (blue) consistently stays at the Pareto frontier.
Updates: Through a log-structured append-only strategy for vectors and batched merges for indices, DecoupleVS maintained search performance during heavy update workloads, where monolithic systems often see latency spikes.
Deep Insight: Why This Matters
The "co-location" strategy was a relic of an era where disk seeks were the primary bottleneck. In the era of high-speed NVMe and billion-scale embeddings, the bottleneck has shifted to Data Volume and Memory Bandwidth.
DecoupleVS proves that by treating the vector database like a specialized file system—one that understands the mathematical distribution of vectors—we can achieve massive cost savings without the accuracy loss associated with lossy compression (like Product Quantization).
Conclusion
DecoupleVS is a masterclass in storage systems design for AI. It demonstrates that as models grow, our storage architectures must become "context-aware," treating different parts of the data object with specialized logic. For any organization running massive RAG (Retrieval-Augmented Generation) clusters, these 58% savings are game-changing.
Limitations: There is a slight increase in CPU overhead due to decompression, though this is largely mitigated by high-performance Huffman implementations and multi-threading.