The paper introduces a scalable multi-turn synthetic data generation pipeline for code Reinforcement Learning (RL), resulting in the Llama-3.1-8B, Qwen3-8B, and Qwen2.5-32B models. By using a teacher model to iteratively refine problems based on student performance, the method produces "stepping stones" (curated difficulty progressions) that significantly improve code and math performance.
TL;DR
Meta FAIR and collaborators have released a deep dive into scaling Reinforcement Learning (RL) for code generation. The core breakthrough isn't more data, but better-structured synthetic tasks. By using a multi-turn teacher-student pipeline to create "stepping stones" (related problems of increasing difficulty), they've unlocked a way to surpass real-world data performance using a fraction of the compute, showing massive gains across Llama 3.1 and Qwen families.
The Scaling Wall: Why More Data != Better RL
In the Supervised Fine-Tuning (SFT) era, data was king. In the RL era, Exploration is King. The authors identify a critical plateau:
- Easy problems are solved instantly, leading to "entropy collapse" where the model stops exploring.
- Hard problems provide a sparse reward; the model fails 100% of the time, learning nothing.
- Real data is a messy mix where hard problems don't necessarily build on easy ones, making "curriculum learning" less effective.
Methodology: The Multi-Turn "Stepping Stone" Pipeline
Instead of sampling random problems, the authors use a high-reasoning teacher model to "mutate" code snippets.
1. The Iterative Refinement
A teacher receives a "seed" (e.g., a snippet from StarCoder). It generates a problem. If the student solves it too easily (100% pass rate), the teacher is prompted to increase complexity (e.g., adding constraints, budget limits, or complex dependencies). If the student fails, it simplifies the task.
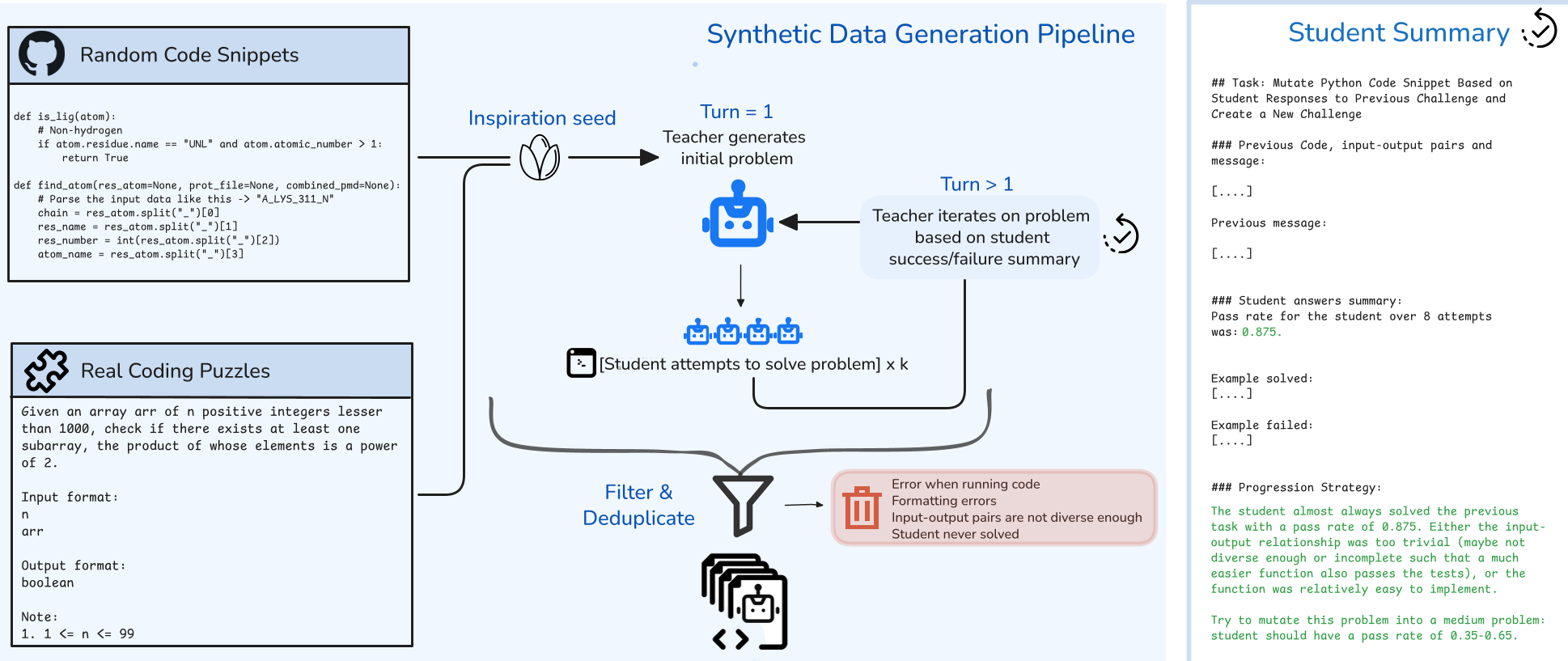
2. Multi-Environment Scaling
The paper introduces four distinct environments:
- Induction: Traditional program synthesis.
- Abduction: Input prediction (given $f(x)$ and $y$, find $x$).
- Deduction: Output prediction (given $f(x)$ and $x$, find $y$).
- Fuzzing: Finding bugs in code.
This structural diversity acts as an independent "scaling axis" that prevents the model from overfitting to specific question templates.
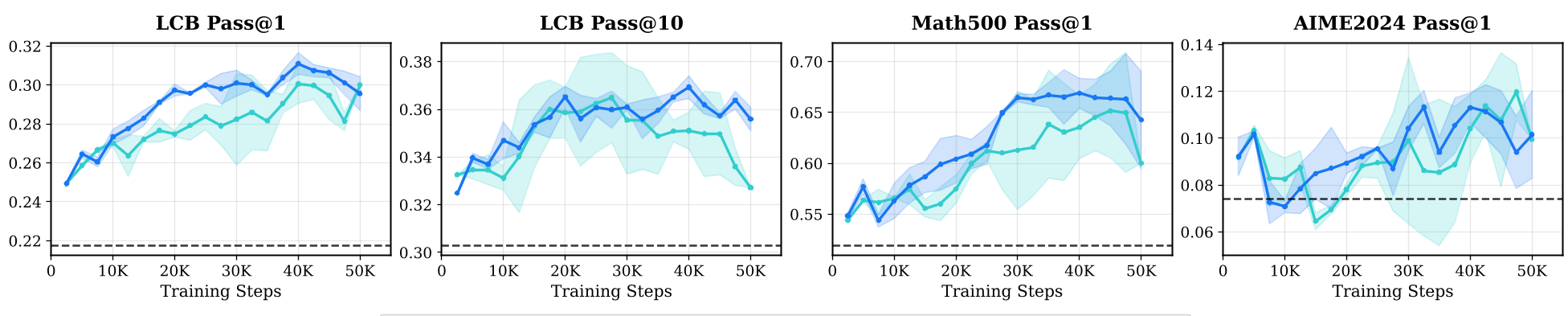
Experimental Insights: The Power of "Medium" and "Reverse"
The researchers conducted extensive sweeps across Llama 3.1-8B and Qwen2.5-32B, revealing counter-intuitive truths about RL training:
- The "Medium" Sweet Spot: Training only on medium-difficulty questions (pass rates ~40-60%) often yields better generalization than training on a mix.
- The Reverse Curriculum Genius: Starting with Hard/Medium tasks and gradually introducing easier ones actually prevents the model from "wasting" its exploration budget early on.
- Synthetic > Real: A mix of 25K Real + 20K Synthetic problems outperformed 81K purely Real problems.
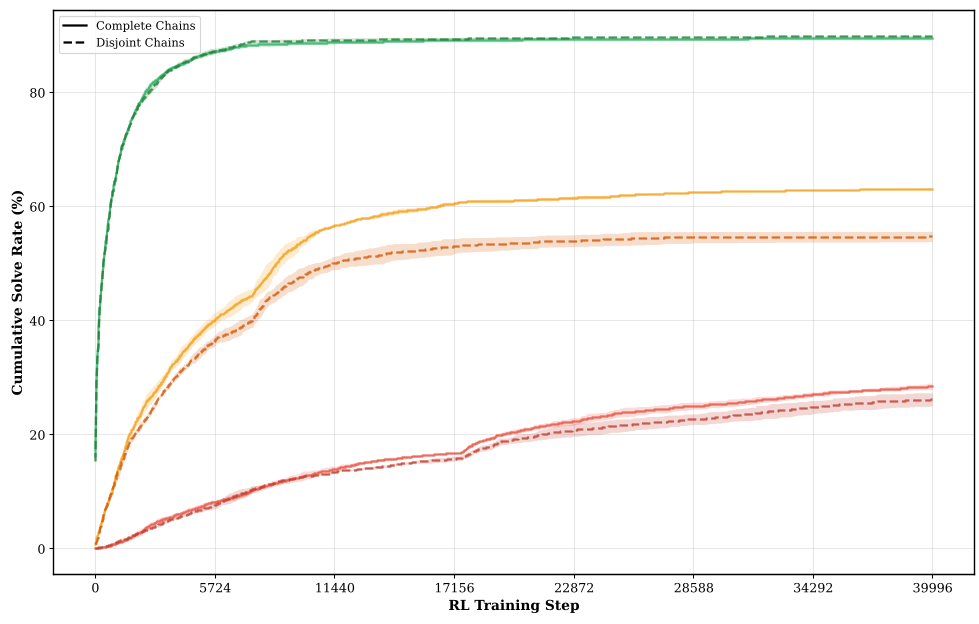
Deep Dive: Chain Examples
The "Stepping Stone" logic is best seen in how a simple "sum of distances" problem evolves into a complex Zhang-Shasha dynamic programming task through teacher mutation. This ensures that the model learns the sub-components of a hard problem before facing the full complexity.
Critical Analysis & Future Outlook
While the results are impressive, the authors note that Curriculum Design is fragile. If you mix easy and hard gradients too aggressively, they interfere. The "Soft Curriculum" actually performed worse than a "Hard Transition" because the model kept reverting to easy solutions.
The Takeaway for the Industry: We are moving from "Big Data" to "Densely Curated Challenges." If you want to scale your LLM's reasoning, stop scraping the web and start building a teacher that knows how to challenge your student.
Conclusion
This work provides a rigorous framework for using synthetic data not just as a filler, but as a structured ladder for RL. As we look toward Qwen3 and Llama 4, expect these "Stepping Stone" pipelines to be the engine behind the next leap in AI reasoning.