本文提出了 DA-Flow,一种专门针对真实场景中受损视频(如模糊、噪声、压缩伪影)进行鲁棒光流估计的方法。通过将图像修复扩散模型(Restoration Diffusion Models)与 RAFT 架构融合,DA-Flow 在 Sintel 和 Spring 等基准测试的降质版本中显著超越了现有模型,实现了 SOTA 精度。
TL;DR
传统光流模型在面对模糊、噪点和压缩卡顿的“烂画质”视频时往往束手无策。来自 KAIST 的研究团队推出了 DA-Flow,其核心思想是:利用原本用来“修图”的扩散模型(Restoration Diffusion Models)作为特征提取器。通过赋予扩散模型时空感知力,新模型在极度恶劣的画质下依然能精准捕捉像素级的运动轨迹,在多个受损视频基准上将误差降低了 30% 以上。
背景定位:从“鲁棒性”转向“退化感知”
光流估计(Optical Flow)是计算机视觉的基石,但此前学术界更多关注在干净数据上的指标。虽然有如 RobustSpring 这样的工作开始关注鲁棒性,但它们大多只是做数据增强。DA-Flow 认为,当图像受损严重到纹理消失时,单纯靠卷积匹配是不够的,必须引入生成式先验(Generative Priors)。这使得该工作在领域坐标系中属于“将生成模型先验引入判别式底层任务”的前沿探索。
痛点与动机:为什么 RAFT 们在噪声中失效了?
现有的 SOTA 模型(如 RAFT, SEA-RAFT)依赖于特征编码器提取的精确描述子。
- 信息丢失:传感器噪声或压缩伪影会产生假纹理,诱导模型产生错误的 Correlation(相关性)信号。
- 时空缺失:简单的图像修复模型是逐帧操作的,缺乏帧间一致性。
- 特征坍缩:视频扩散模型虽然有时间轴,但往往通过 3D 卷积或压缩潜空间(Latent Space)把特征搞“混”了,导致无法进行像素级的两两匹配。
方法论详解:DA-Flow 的“升维策略”
1. 模型的“提升”(Lifting)
作者选择 DiT4SR(一种基于 Transformer 的图像修复扩散模型)作为骨架。为了让它理解运动,作者打破了它原本逐帧处理的限制,引入了 Full Spatio-temporal Attention。
- 直觉:让第 帧的每一个像素 Token 不仅看本帧,还能跨过时间看到第 帧的所有像素,从而在去噪的过程中自发学习运动对应关系。
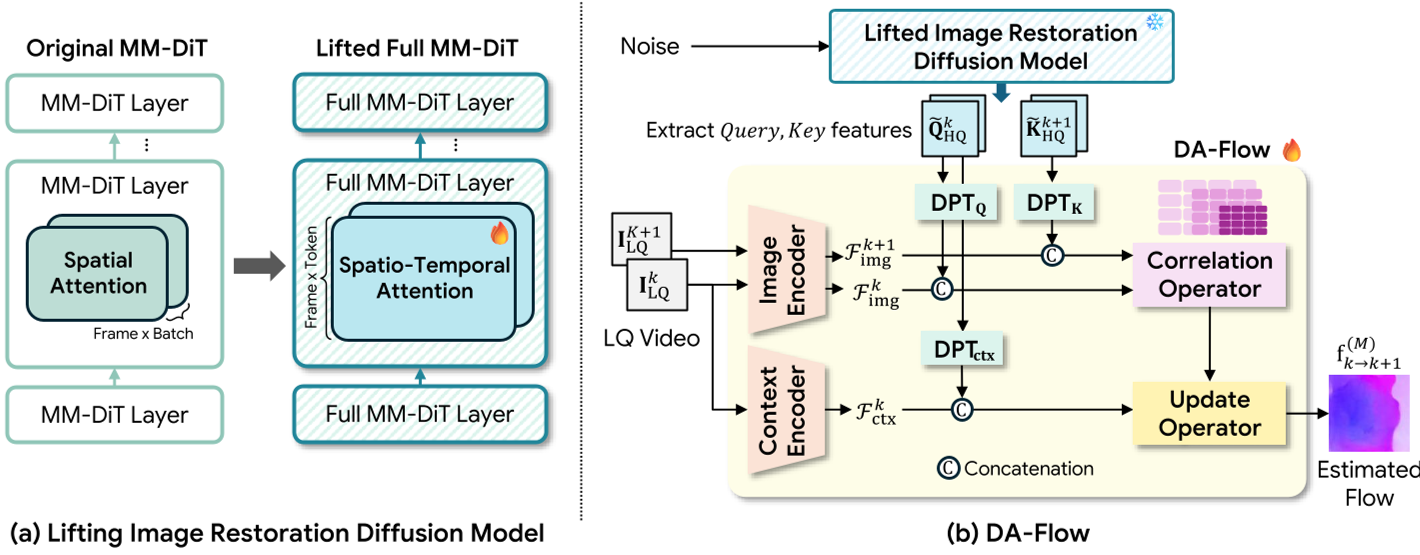 图 1:DA-Flow 整体逻辑。通过将修复扩散模型“提升”至视频域,提取其 Query/Key 特征。
图 1:DA-Flow 整体逻辑。通过将修复扩散模型“提升”至视频域,提取其 Query/Key 特征。
2. 混合特征编码与多尺度上采样
虽然扩散模型特征(Diffusion Features)对退化很敏感(Degradation-Aware),但其分辨率较低(1/16)。
- 混合驱动:DA-Flow 将扩散特征与 RAFT 原有的 CNN 特征拼接。CNN 负责保留局部细微纹理,扩散特征负责提供全局几何和退化感知的先验。
- DPT 上采样:使用基于 Vision Transformer 的 DPT 头部将粗糙的扩散特征还原到 1/8 分辨率,确保运动边界的锐利度。
实验与结果:即便画质模糊,运动依然清晰
研究人员在 Sintel、Spring 和 TartanAir 三大基准的“受损版”上进行了严苛测试。
1. 定量战绩
在 Sintel 数据集上,DA-Flow 的 EPE 指标达到了 6.912,而之前的最强模型 SEA-RAFT 仅为 10.185。这种跨越式的提升充分验证了扩散模型特征在处理极端分布偏移时的优越性。
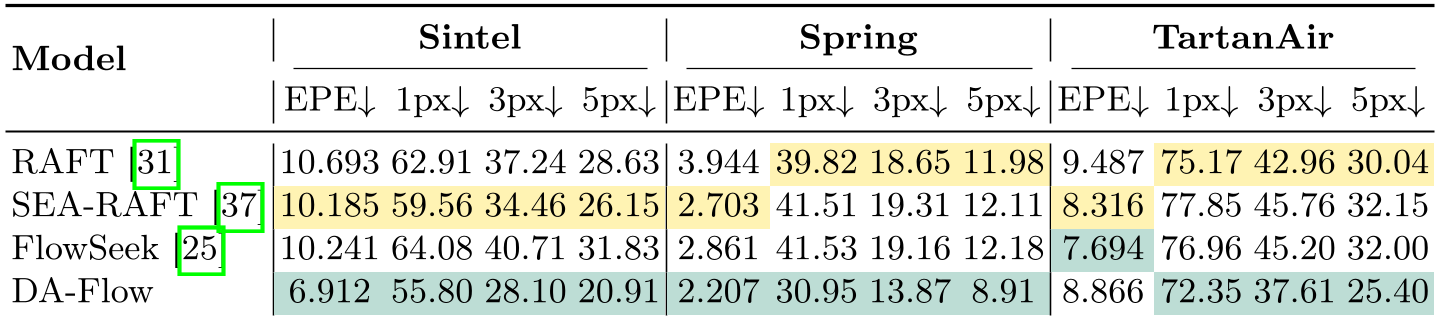 表 1:在不同退化 benchmark 上的性能对比。DA-Flow 在 Sintel 和 Spring 上展现了统治级表现。
表 1:在不同退化 benchmark 上的性能对比。DA-Flow 在 Sintel 和 Spring 上展现了统治级表现。
2. 定性视觉对比
正如可视化结果所示,传统模型(如 FlowSeek)在背景噪声大或物体边缘模糊时会出现大量暗影和断裂。而 DA-Flow 输出的光流图边界锐利,结构完整。
 图 2:在受损视频上的定性表现。DA-Flow(最右列)生成的流量图最接近 Ground Truth(最左列)。
图 2:在受损视频上的定性表现。DA-Flow(最右列)生成的流量图最接近 Ground Truth(最左列)。
深度洞察与总结
关键发现(Takeaways)
- Query/Key 比 Post-AdaNorm 更有效:实验证明,扩散模型内部 Attention 层的 Q/K 特征天生带有匹配属性,比经过归一化后的特征更适合做密集对应。
- 无监督的潜力:哪怕不经过特定的任务微调(Zero-shot),“提升”后的修复模型特征已经具备了一定的运动感。
局限性与展望
- 推理延迟:扩散模型需要多步去噪(本文使用了 10 step),这使得 DA-Flow 的速度远慢于实时光流模型。
- 未来方向:作者指出,如何利用**单步蒸馏(One-step Distillation)**技术在保持退化感知特性的同时提升推理速度,是未来的研究重镇。
结论:DA-Flow 成功地将扩散模型从“修图师”变为了“领航员”,为现实世界复杂环境下的视觉运动分析开辟了新的技术路径。