The paper introduces Delightful Policy Gradient (DG), a novel weighting mechanism for distributed Reinforcement Learning that gates updates using "delight"—the product of advantage and action surprisal. DG achieves state-of-the-art robustness against distributed frictions like staleness and bugs, outperforming importance-weighted PG by 4x on MNIST and solving 2-3x longer sequences in transformer tasks.
TL;DR
Distributed Reinforcement Learning (RL) is the backbone of modern reasoning models, yet it is plagued by "frictions"—stale weights, bugs, and mismatched hardware. These frictions produce "surprising" data that ruins standard gradients. Delightful Policy Gradient (DG) solves this by gating updates with "delight" (Advantage $ imes$ Surprisal), effectively muting rare failures and magnifying rare successes. It outperforms exact importance sampling without needing to know a single behavior probability.
The Motivation: Why Distributed RL is "Buggy" by Design
Large-scale post-training (like that used for O1 or DeepSeek) relies on thousands of actors generating rollouts. In these systems, "on-policy" assumes a perfect world that doesn't exist. Small mismatches in token probabilities compound, silently turning on-policy training into a messy off-policy battle.
The authors identify a critical insight: The problem isn't just "surprising" data; it's what we do with it.
- Surprising Successes: High-surprisal actions that yield high rewards are "discoveries"—the learner should jump on these.
- Surprising Failures: High-surprisal actions that fail are likely noise, bugs, or staleness. In standard PG, these failures dominate the gradient direction because they have large log-probability gradients, even if they carry zero useful signal.
Methodology: Gating by Delight
The "Delight" ($\chi_t$) of a sample is defined as the product of its advantage ($U_t$) and its surprisal ($\ell_t = -\log \pi_ heta(A_t|H_t)$).
Standard weighting (like Importance Sampling) is sign-blind—it weights successes and failures equally based on distribution mismatch. DG is sign-dependent. It uses a sigmoid gate: $$w_t = \sigma(\chi_t / \eta)$$
- Positive Delight (Discovery): Learner finds a reward where it didn't expect one. The gate opens ($w_t o 1$).
- Negative Delight (Noise/Staleness): Learner sees a failure it already knew to avoid. The gate closes ($w_t o 0$).
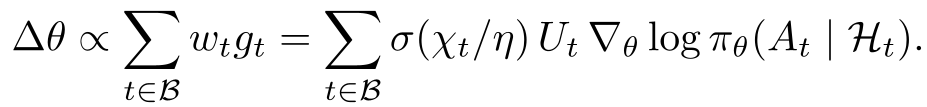
The Self-Reinforcing Dynamic
The paper provides a brilliant tabular bandit analysis showing that DG creates a positive feedback loop. As the policy improves, it becomes better at identifying and suppressing its own "disfavored failures." This shrinks the "overlap moment" of contamination. Standard PG, even with perfect importance weights, cannot recover this because it remains vulnerable to the large-norm gradients of disfavored actions.
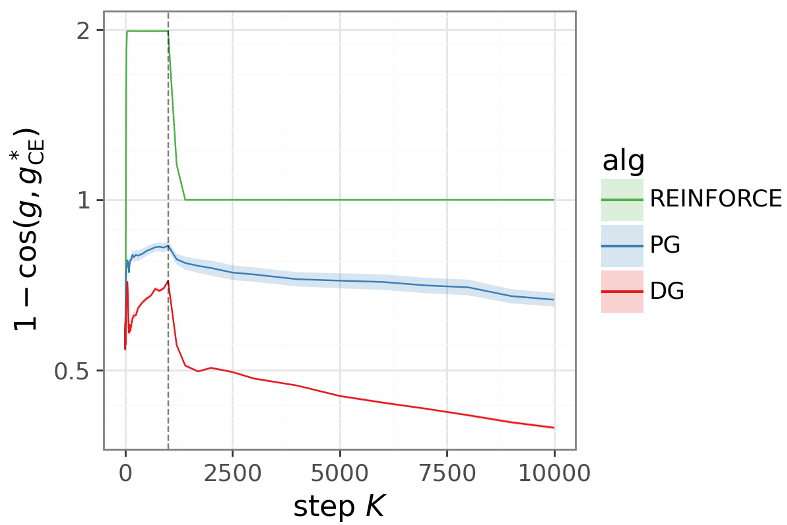
Experimental Results: Dominance Across Frictions
The authors tested DG across four intense "frictions":
- Staleness: Actors using old weights.
- Actor Bugs: Actors outputting junk (e.g., all zeros).
- Reward Corruption: Noisy reward signals.
- Rare Discovery: Extremely sparse rewards.
In the "Token Reversal" transformer task, DG's advantage was not just incremental—it was an order of magnitude. While baseline algorithms like PPO or PMPO collapsed as sequence complexity increased, DG's performance gap actually widened.
Critical Analysis & Future Outlook
The beauty of DG lies in its simplicity. It requires no complex importance ratio clipping and no memory of actor behavior probabilities—which are often lost or corrupted in distributed systems anyway.
Key Takeaways:
- Surprisal-Blindness is Fatal: Algorithms that ignore how "surprising" an action is to the current learner will always be derailed by distributed noise.
- Asymmetry is Essential: Treating successes and failures asymmetrically (filtering failures more aggressively than successes) is the secret to stable RL.
Limitations: While the theoretical grounding is robust, the experiments are currently on small-scale transformers (≈50K parameters). The true test will be applying this to 70B+ parameter models in production environments. If the "Delight" mechanism scales, it could replace PPO/GRPO as the default weighting scheme for the next generation of reasoning LLMs.