DFM-VLA is a novel Vision-Language-Action (VLA) framework that introduces Discrete Flow Matching to robotic manipulation, enabling iterative action token refinement. By modeling a token-level probability velocity field, it achieves SOTA results on CALVIN (Avg. Len 4.44) and LIBERO (95.7% success rate), outperforming existing autoregressive and diffusion-based VLAs.
TL;DR
Current robots often fail because of "early commitment" errors—once a Vision-Language-Action (VLA) model picks a token, it's stuck with it. DFM-VLA breaks this cycle by introducing Discrete Flow Matching to robot control. Instead of predicting actions once, it iteratively refines the entire action sequence using a probability velocity field. It hits an impressive 4.44 average success length on CALVIN and 95.7% on LIBERO, setting a new bar for discrete action models.
The Problem: The "Irreversible Commitment" Trap
Most modern VLA models (like OpenVLA or RT-1) view action generation through two lenses:
- Autoregressive (AR): Tokens are generated one by one. If token #1 is wrong, tokens #2-6 are built on a shaky foundation.
- Discrete Diffusion (DD): Tokens are predicted in parallel but typically follow a "mask-and-fill" logic where once a token is "filled," it isn't revisited.
In robotics, a tiny deviation in the first few milliseconds of a trajectory (the first tokens) can lead to a total task failure. Existing models lack a mechanism to say, "Wait, now that I've planned the whole arm movement, I realize my initial grip angle was slightly off—let me fix it."
Methodology: Refining Actions via Probability Flow
DFM-VLA moves away from "predicting tokens" to "modeling flow." It treats the action sequence as a state $x_t$ that evolves from pure noise ($t=0$) to a clean action ($t=1$) across refinement iterations.
1. The Core Architecture
The model uses a unified token space for vision (VQ-VAE), language (Emu3), and actions (FAST + BPE). By wrapping images and actions in specific markers (boi/eoi and boa/eoa), the transformer backbone learns the cross-modal dependencies required for manipulation.
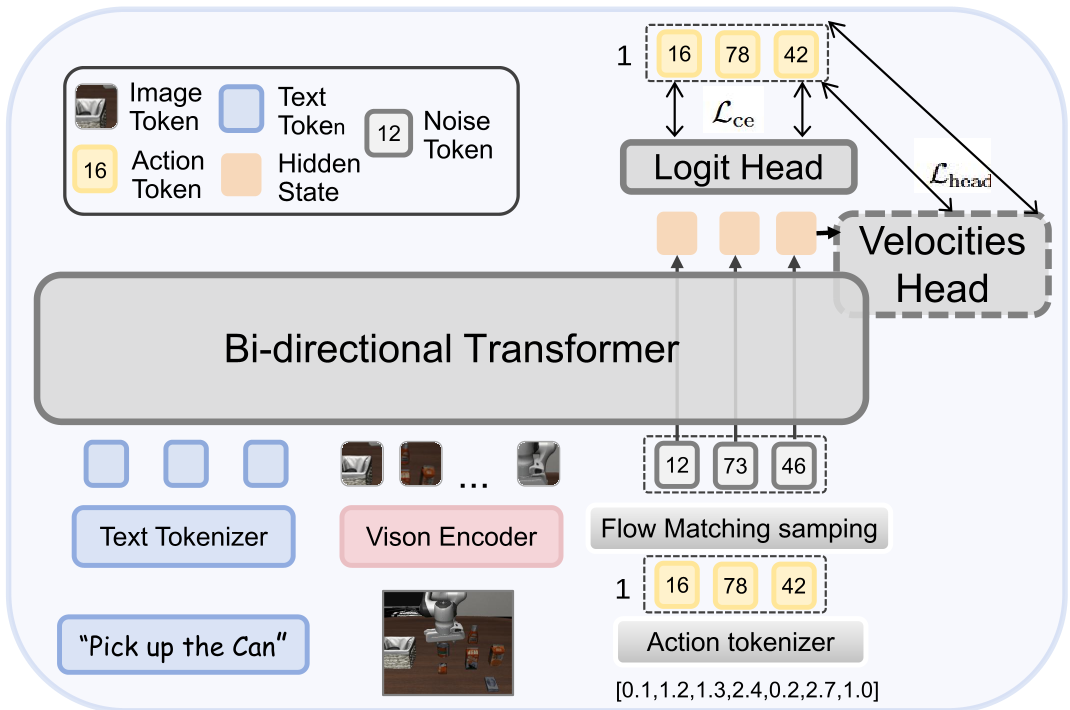
2. Action-Embedding-Guided Velocity
The secret sauce is how the model knows how to change a token. The authors use the semantic distance in the embedding space to guide the "velocity."
- Intuition: If the model is uncertain, it moves the current token toward a "neighborhood" of tokens that are semantically closer to the target action. This creates a smooth, monotonic refinement process rather than random hopping between vocabulary IDs.
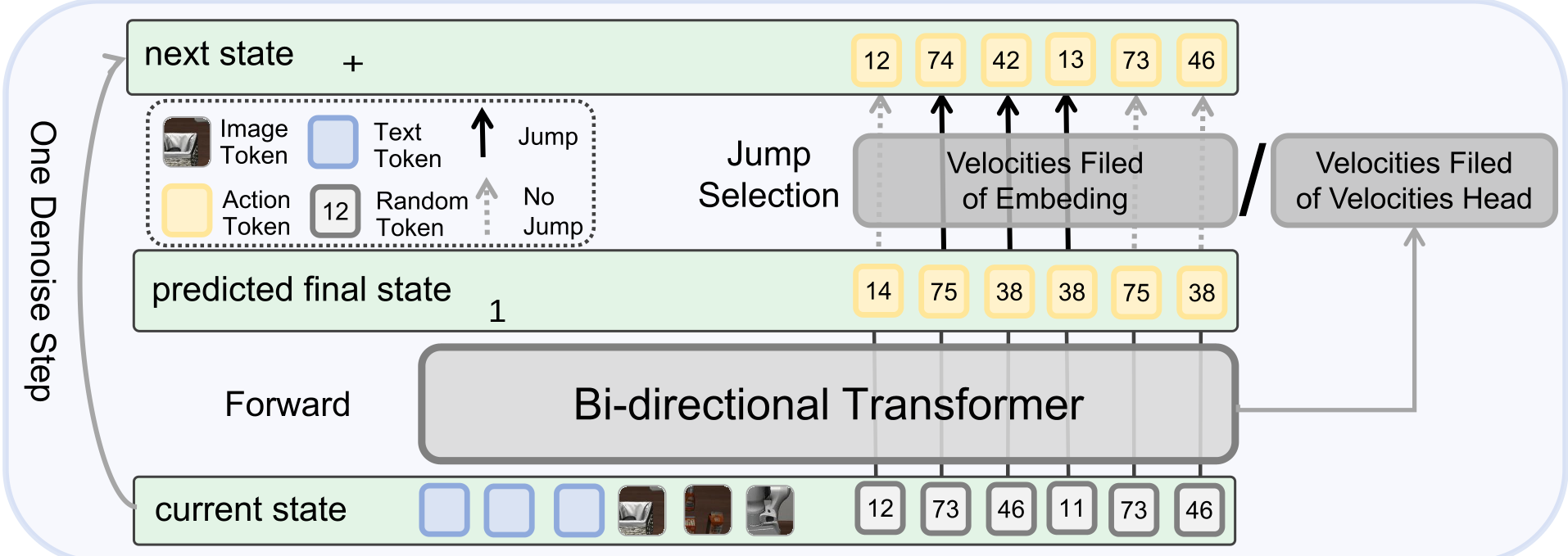
3. Two-Stage Decoding
To balance "creative correction" with "perfect execution," DFM-VLA uses a hybrid approach:
- Iterative Refinement (T_fine): Uses stochastic jumps (Euler discretization of a CTMC) to explore and correct errors.
- Deterministic Validation (T_val): Switches to greedy decoding at the very end to "lock in" the best sequence and ensure stability.
Experiments: Dominating the Benchmarks
DFM-VLA was tested against the heaviest hitters in the field (Octo, RT-1, RDT, etc.).
Simulation Performance
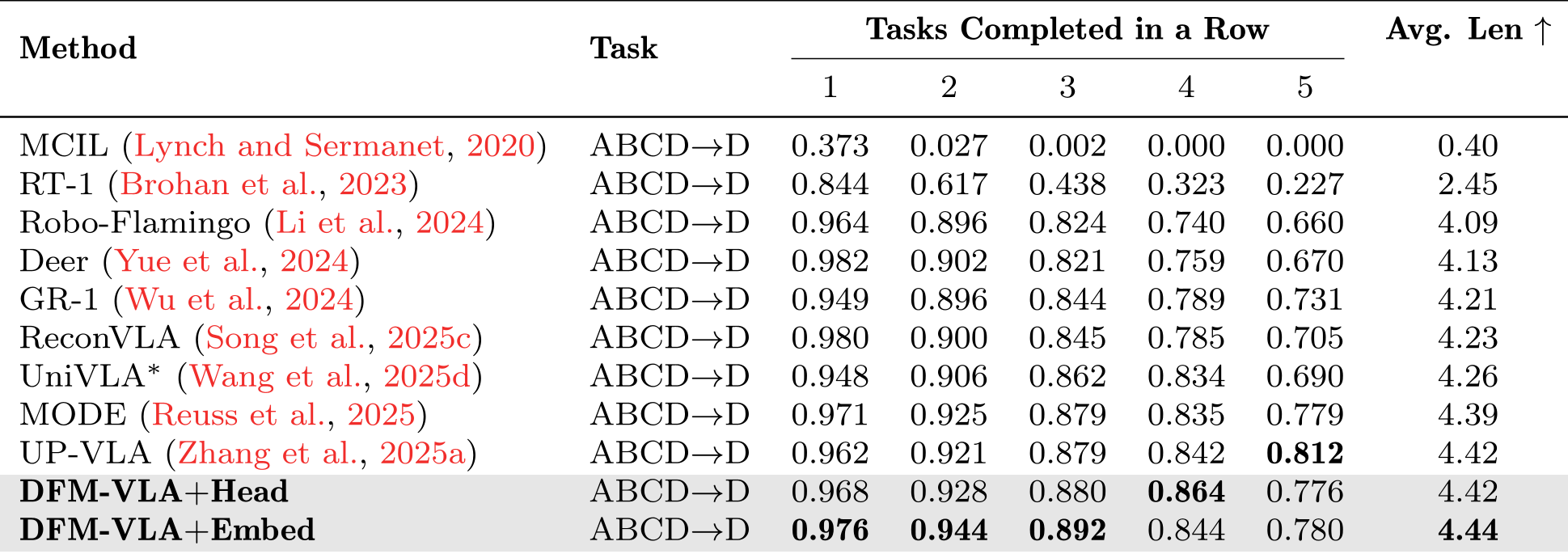
On CALVIN, a benchmark for long-horizon consistency, DFM-VLA achieved an average success length of 4.44/5, proving its ability to stay on track during multi-step tasks. On LIBERO, it hit 95.7%, specifically excelling in "Object" and "Long" suites where precision and memory are key.
Real-World Robustness
In real-world bimanual tasks (like lifting a pot), DFM-VLA outperformed the continuous diffusion model RDT (70.8% vs 60.0% success rate). This is a significant result—it suggests that a well-refined discrete model can be more robust than continuous models that are traditionally preferred for precise spatial tasks.
Deep Insight: Efficiency vs. Quality
One might worry that "iterative refinement" is too slow for a real robot. However, the authors integrated Adaptive KV Caching. Since actions only change slightly between refinement steps, most of the Transformer's memory (KV Cache) can be reused. This allows DFM-VLA to run at 121 FPS, effectively making it faster than many autoregressive models while being more accurate.
Conclusion and Future Outlook
DFM-VLA proves that the "irreversible commitment" of current VLAs is a significant bottleneck that can be solved mathematically through Flow Matching. By allowing the model to "change its mind," we get agents that are significantly more resilient to noise and early-stage planning errors.
What's next? The embedding-guided velocity opens the door for "Action CoT"—where a model might refine its reasoning and its physical actions simultaneously in a unified flow.
Senior Editor's Note: This work signals a shift from "Scaling Laws for Prediction" to "Scaling Laws for Refinement" in Embodied AI.