The paper introduces Distribution-Guided Policy Optimization (DGPO), a critic-free reinforcement learning framework designed for fine-grained credit assignment in Large Language Models (LLMs). By reinterpreting distribution deviation as an exploratory signal rather than a penalty, DGPO achieves state-of-the-art results on mathematical reasoning benchmarks like AIME 2024 (60.0% Avg@32).
TL;DR
Current LLM alignment relies on "one-size-fits-all" rewards for long reasonings, often penalizing creative exploration through rigid KL penalties. Distribution-Guided Policy Optimization (DGPO) flips this script. By replacing KL divergence with the bounded Hellinger distance and using entropy gating, DGPO identifies the exact tokens responsible for logical breakthroughs. It achieves SOTA math reasoning (AIME 2024: 60%) with virtually the same memory footprint as a standard GRPO baseline.
1. The Bottleneck: Coarse Rewards and Explosive Gradients
Reinforcement Learning for LLMs, specialized for complex reasoning (Chain-of-Thought), has recently moved toward "critic-free" methods like GRPO. While efficient, these methods treat every token in a 1,000-token sequence as equally "good" or "bad" based on the final answer. This is the Coarse Credit Assignment problem: a brilliant logical leap is treated no differently than a comma or a transition word.
Furthermore, traditional RL uses Reverse KL Divergence to keep the model from drifting too far from its original state. However, the KL penalty is unbounded. If a model explores a novel path that the original model thought was highly improbable, the penalty "explodes," leading to gradient spikes and forcing the model to be overly conservative (Mode-Seeking Conservatism).
2. Methodology: From Penalty to Guide
DGPO re-imagines distribution deviation. Instead of a penalty, it treats deviation as a guidance signal.
The Bounded Hellinger Distance
To avoid the gradient explosion of KL, DGPO uses the Hellinger distance (). Because it is bounded between , it provides a smooth signal even during aggressive exploration.
Entropy Gating: Filtering "Fake Innovations"
How do we know if a model is exploring or just hallucinating? DGPO introduces an Entropy Gate.
- High Deviation + High Entropy: The model is trying something new and isn't sure—this is likely a pivotal reasoning step.
- High Deviation + Low Entropy: The model is confidently outputting nonsense—this is a hallucination.
By scaling the Hellinger deviation by the policy's Shannon entropy, DGPO amplifies the weights for genuine insights while suppressing hallucinations.
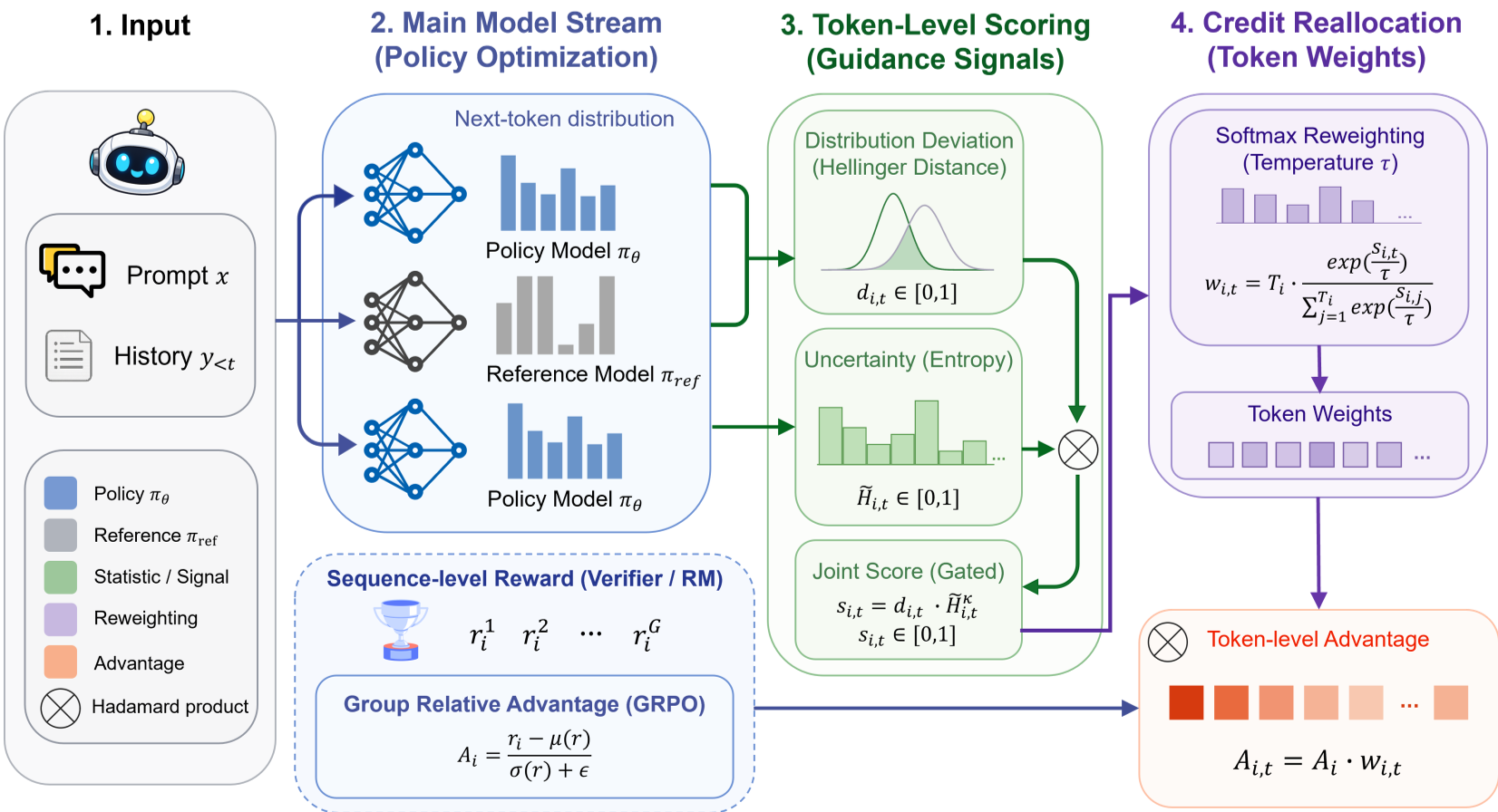 Figure 1: The DGPO pipeline shows how sequence-level advantages are redistributed into token-level weights using entropy-gated distribution metrics.
Figure 1: The DGPO pipeline shows how sequence-level advantages are redistributed into token-level weights using entropy-gated distribution metrics.
3. Results: Breaking the Performance Ceiling
The effectiveness of DGPO was verified on the toughest math benchmarks current LLMs face: AIME 2024 and AIME 2025.
| Method | AIME 2024 (Avg@32) | AIME 2025 (Avg@32) | | :--- | :---: | :---: | | DAPO | 50.0% | 38.0% | | FIPO | 56.0% | 43.0% | | DGPO (Ours) | 60.0% | 46.0% |
In addition to pure accuracy, the Ablation Study (Fig 3) confirms that the Hellinger distance and Entropy Gating are critical; removing the entropy gate alone causes a 5% drop in performance.
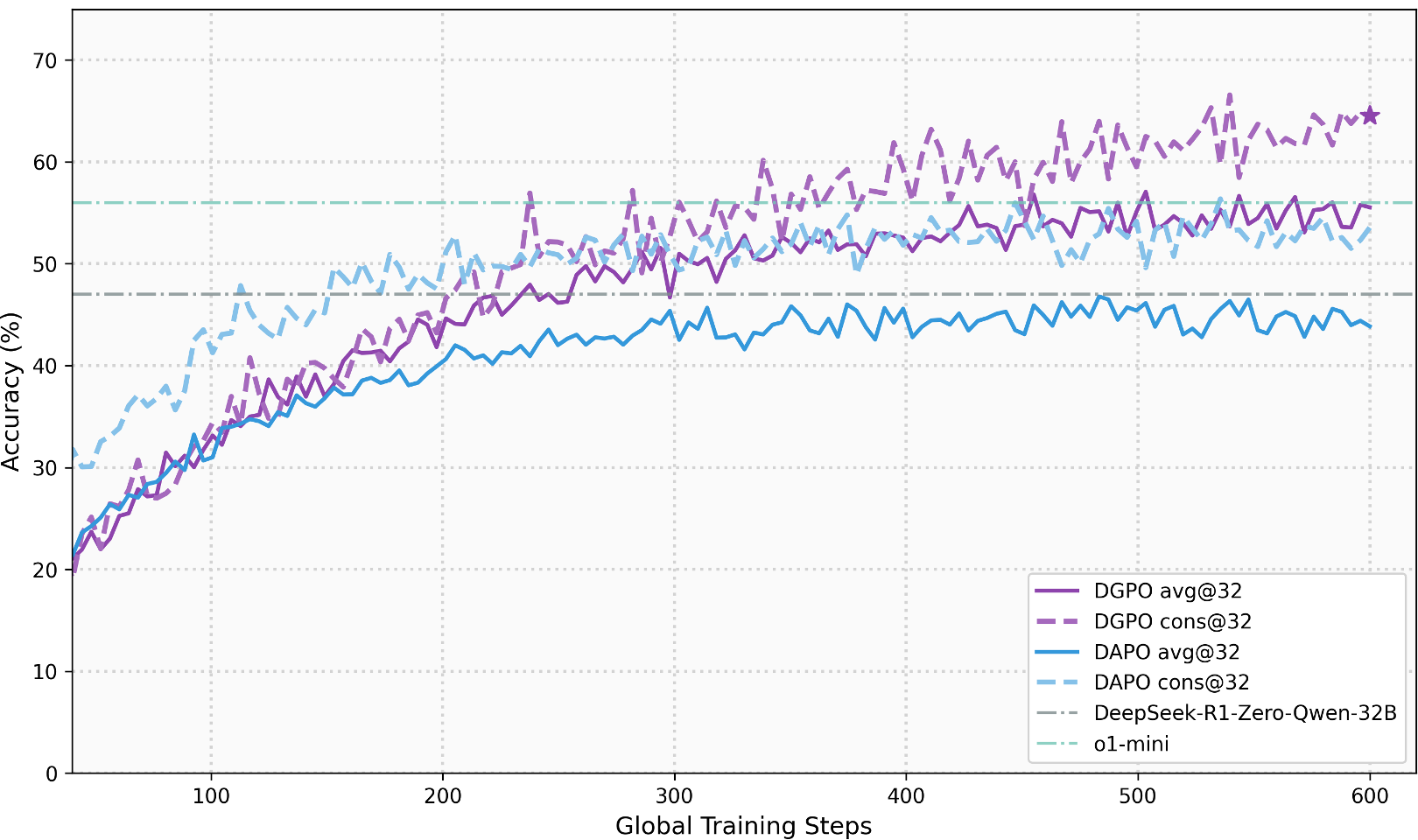 Figure 2: Training progress on AIME benchmarks shows DGPO's superior convergence and final accuracy compared to baselines.
Figure 2: Training progress on AIME benchmarks shows DGPO's superior convergence and final accuracy compared to baselines.
4. Efficiency: Fine-Grained Performance at Group-Relative Cost
One might expect that token-level credit assignment requires a complex "Process Reward Model" (PRM) or a memory-heavy "Value Network" (Critic). DGPO achieves this critic-free.
- Memory: Stays at ~46GB/GPU (vs. 72GB for traditional PPO).
- Speed: Only a 3.6% time overhead over vanilla GRPO.
This is because the probabilities needed for Hellinger and Entropy calculations are already computed during the standard forward pass of the policy and reference models.
5. Visualizing the "Reasoning Leaps"
Qualitative analysis confirms the mechanical intuition. In successful CoT traces, DGPO assigns higher weights (visualized as darker background colors) to key mathematical substitutions and logical deductions, while "filler" words receive almost zero gradient updates.
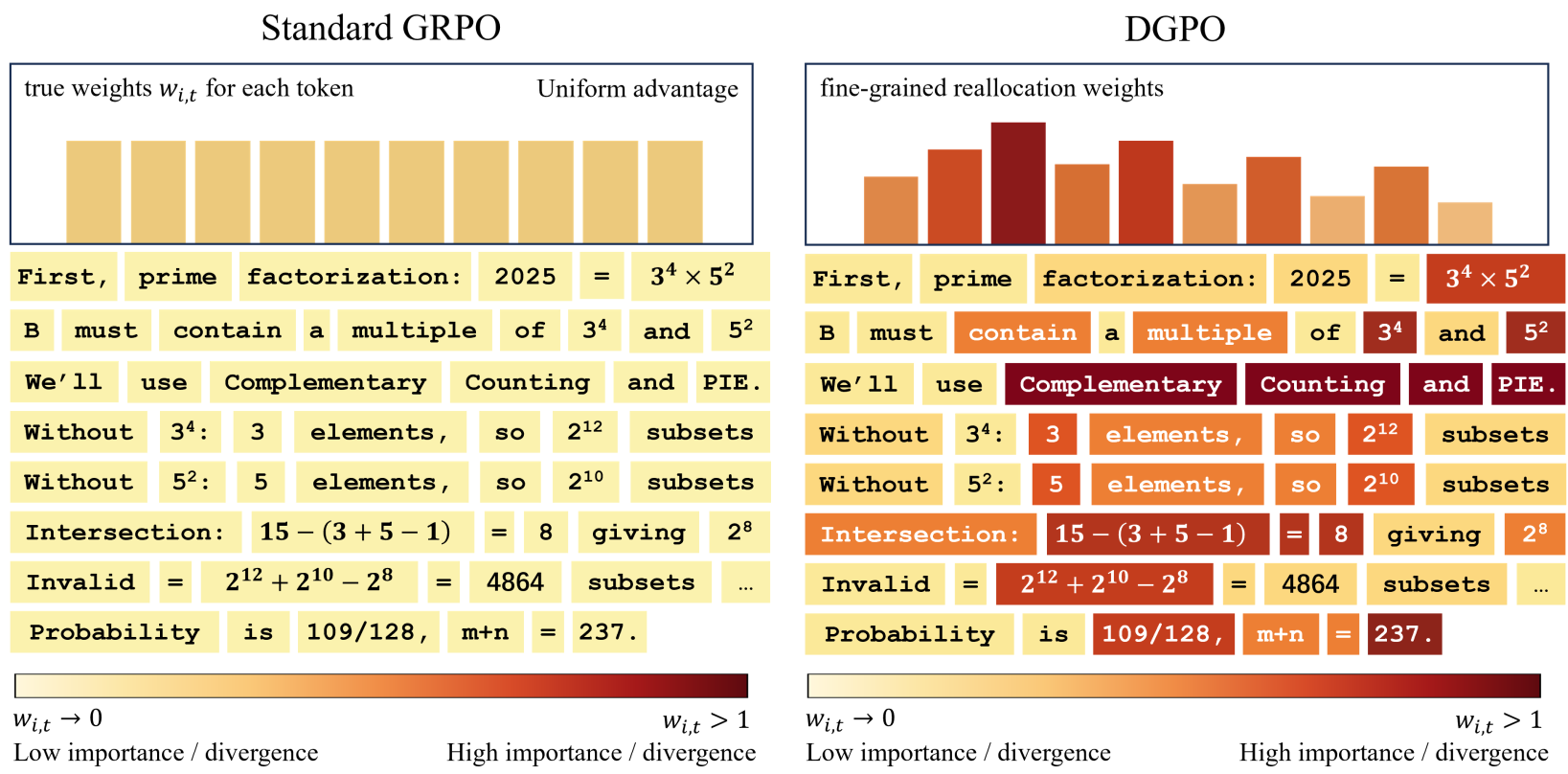 Figure 3: Qualitative visualization of token-level importance weights. DGPO identifies and emphasizes the most critical parts of the reasoning chain.
Figure 3: Qualitative visualization of token-level importance weights. DGPO identifies and emphasizes the most critical parts of the reasoning chain.
6. Critical Analysis & Future Outlook
Conclusion: DGPO successfully solves the temporal credit assignment problem without the overhead of external reward models. It proves that the model's own "internal sense of surprise" (deviation) and "uncertainty" (entropy) are sufficient to guide deep reasoning.
Limitations: Currently, the results are concentrated on mathematical reasoning. Future work will need to prove if this entropy-gated redistribution works as effectively for creative writing or open-ended coding tasks where the definition of a "pivotal step" is more subjective.
The Bigger Picture: This research signals a shift toward intrinsic reward mechanisms—where the LLM's own probabilistic state helps it decide what it should learn from, potentially reducing our reliance on expensive human-annotated step-level data.