本文提出了 DGPO (Distribution-Guided Policy Optimization),一种无需 Critic 网络的大语言模型强化学习对齐框架。该方法通过引入 Hellinger 距离和熵门控机制,将序列级的粗粒度奖励动态分配至 Token 级,在 AIME 2024 等数学推理任务中刷新了 SOTA 纪录。
TL;DR
在强化学习(RL)对齐领域,如何让模型知道长篇大论中哪一步才是“神来之笔”?来自北大、上交和清华的研究团队提出了 DGPO (Distribution-Guided Policy Optimization)。它摒弃了容易导致训练崩溃的 KL 散度,转而使用有界的 Hellinger 距离 结合 熵门控机制,将粗糙的整句奖励精准重分配给关键 Token,在 AIME 数学竞赛测试中展现了卓越的推理提升。
痛点深挖:被平庸化的“神来之笔”
当前的 LLM 强化学习框架(如 DeepSeek 的 GRPO)虽然提升了效率,但面临两个致命伤:
- 信用分配模糊 (Coarse Credit Assignment):如果你解对了一道复杂的数学题,GRPO 会给这几千个 Token 全体发奖。但事实上,只有中间那两行关键的公式推导才是成功的核心,其他的连接词(如 "Therefore", "We take")完全是陪衬。
- 保守的 KL 惩罚 (Mode-seeking Conservatism):为了防止模型跑偏,传统方法使用 KL 散度作为惩罚。然而 KL 是无界的,一旦模型想尝试一种参考模型(Reference Model)没见过的创新解法,KL 惩罚就会瞬间爆炸,导致梯度尖峰,扼杀了模型的“好奇心”。
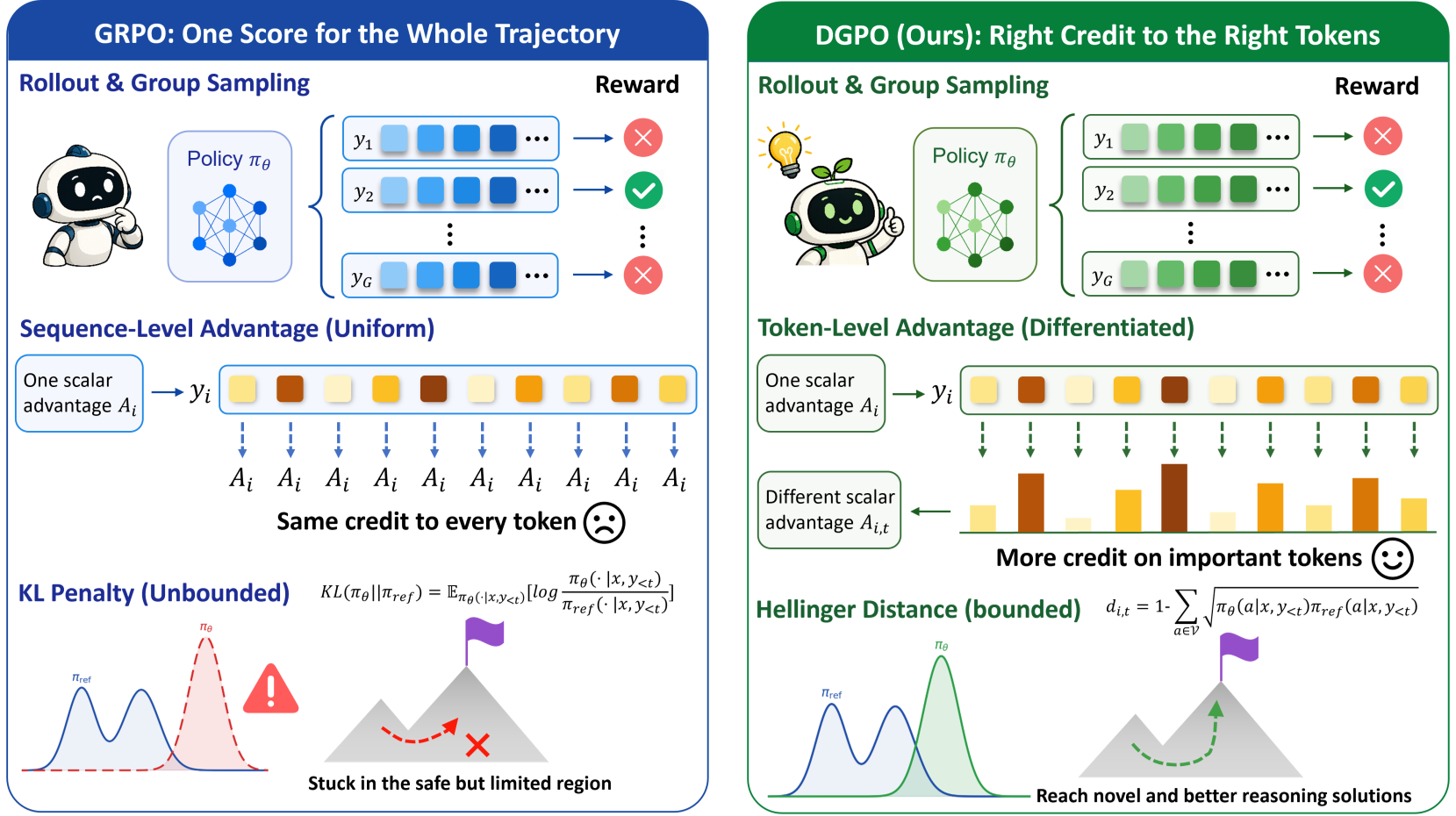 图 1:GRPO 与 DGPO 的直观对比。DGPO 能动态识别并奖励关键 Token,而不仅仅是整句广播。
图 1:GRPO 与 DGPO 的直观对比。DGPO 能动态识别并奖励关键 Token,而不仅仅是整句广播。
核心算法:分布偏差即指引
DGPO 的核心直觉在于:凡是模型在成功路径上产生的、相对于原始分布的显著偏差,往往就是关键的认知飞跃。
1. Hellinger 距离:安全地探索
不同于 Reverse KL,Hellinger 距离 的取值范围严格限定在 [0, 1] 之间。这意味着即使模型探索到了参考模型认为概率极低的区域,梯度也不会失控。它像是一个带有“安全护栏”的向导,鼓励模型在一定范围内大胆尝试新解法。
2. 熵门控 (Entropy Gating):过滤“自信的胡说”
大模型有时会以极高的自信输出错误的幻想(幻觉)。为了防止奖励这些“伪创新”,DGPO 引入了策略熵。只有当 分布偏差大 (di,t) 且 模型本身面临不确定性 (Hi,t) 时,该步才会被认定为真实的逻辑探索。这种协同效应过滤了低熵的噪声。
3. 优势重分配 (Advantage Redistribution)
通过一个带有温度参数的 Softmax 归一化,DGPO 将序列级物理优势 转化为 Token 级的权重 ,公式如下: 这保证了梯度总量的平衡,但实现了“按劳分配”。
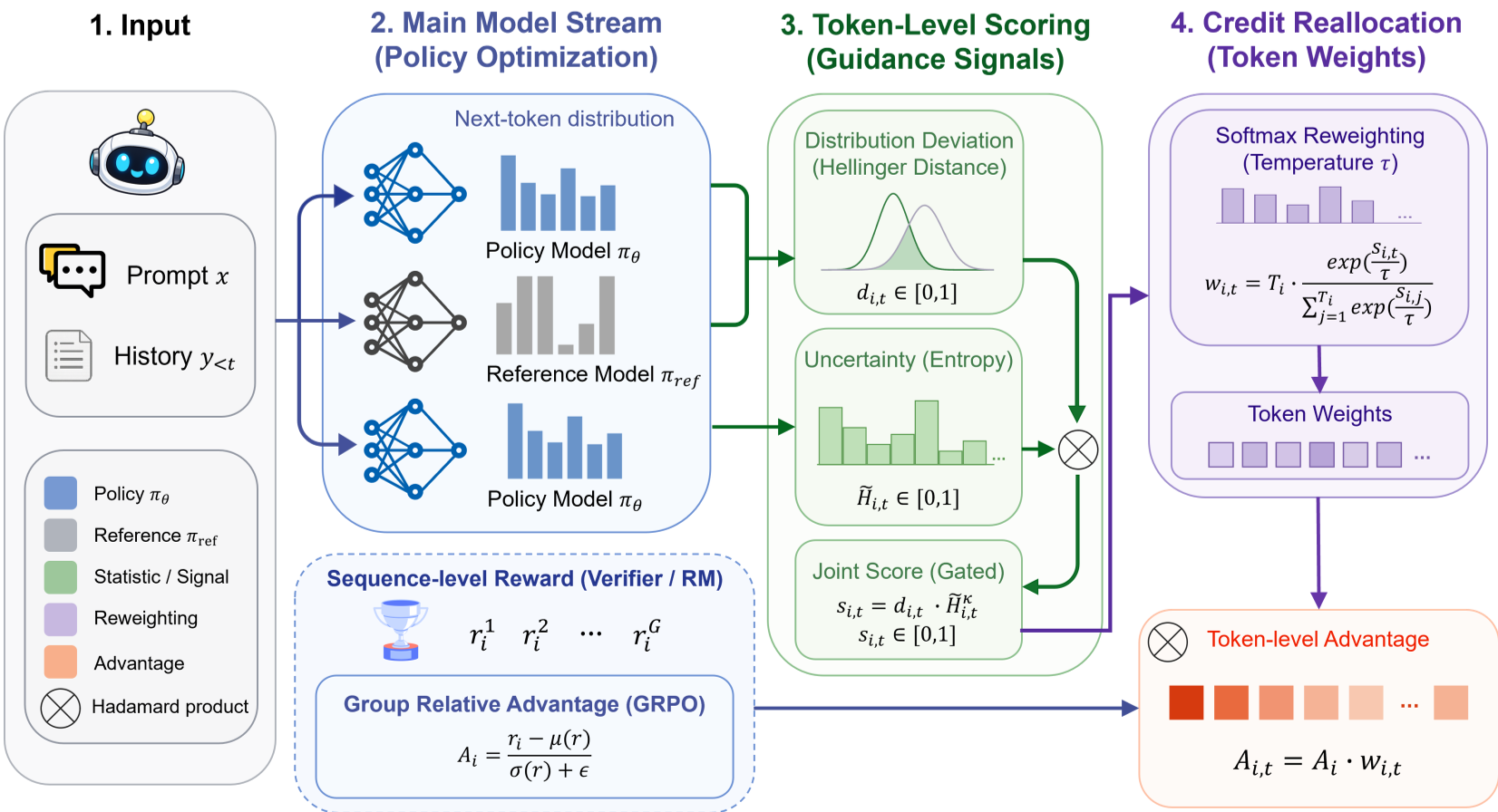 图 2:DGPO 的计算流水线:利用策略自身的概率动态实现细粒度监控。
图 2:DGPO 的计算流水线:利用策略自身的概率动态实现细粒度监控。
实验战绩:数学推理的新高度
在 AIME 2024 和 AIME 2025 两个极具挑战性的数学推理榜单上,DGPO 表现惊人。基于 Qwen2.5-32B 架构,DGPO 展现了比 DAPO 更强的性能增长曲线。
- 高分表现:在 AIME 2024 上达到 60.0% 的 Avg@32 准确率。
- 低成本:虽然实现了类似过程奖励模型(PRM)的效果,但 DGPO 相比 GRPO 仅增加了 3.6% 的耗时,内存占用几乎未变。因为它复用了 policy forward 时生成的 Logits,无需额外的 Value Network。
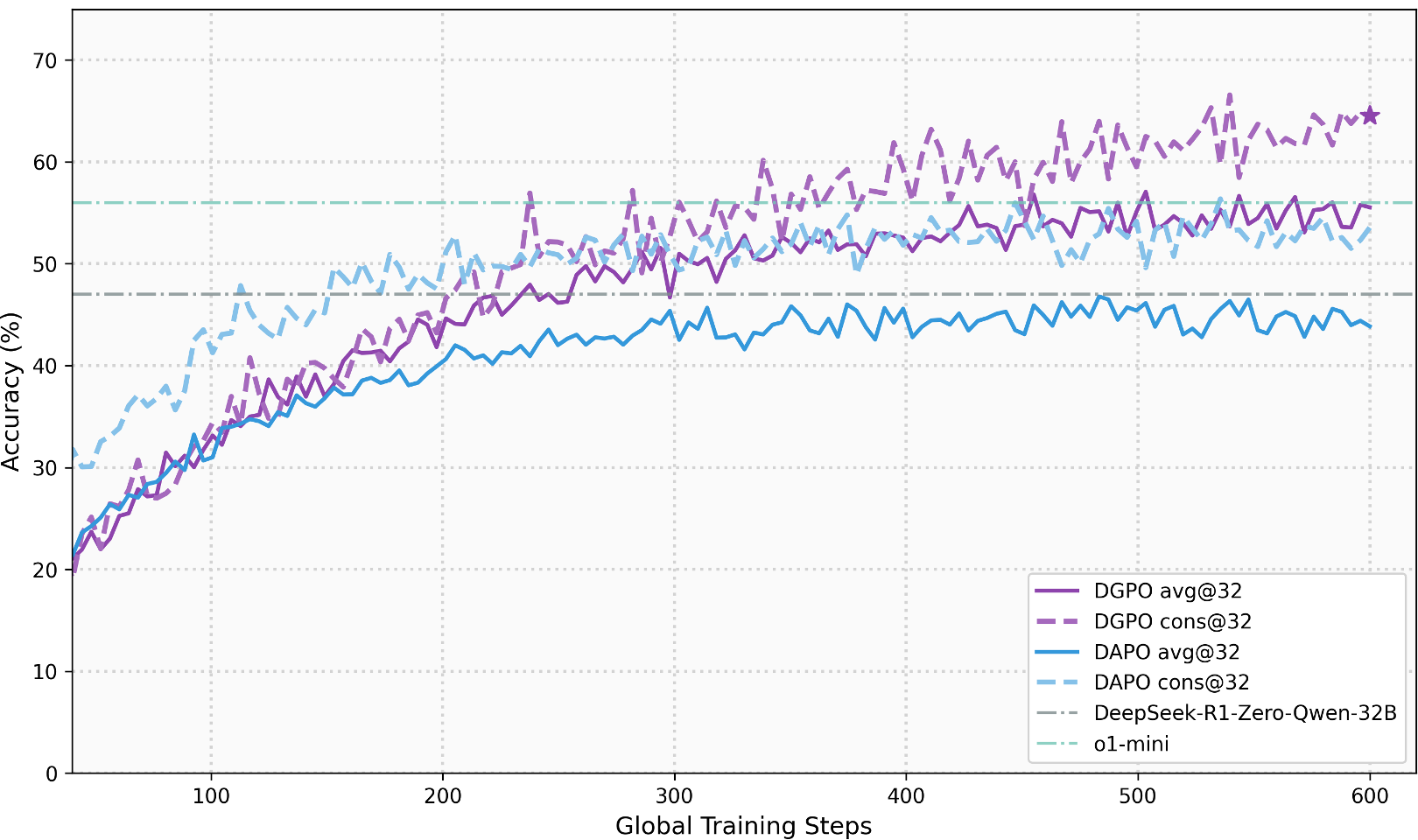 图 3:Qwen2.5-32B 在训练过程中的 AIME 准确率提升曲线。
图 3:Qwen2.5-32B 在训练过程中的 AIME 准确率提升曲线。
深度洞察:可视化中的真相
论文的定性分析(图 4)非常有趣。背景色的深浅代表了权重 的大小。我们可以清晰地看到,在解题的数学推导核心步骤,权重显著加深;而在普通的语法填充词处,权重变浅。
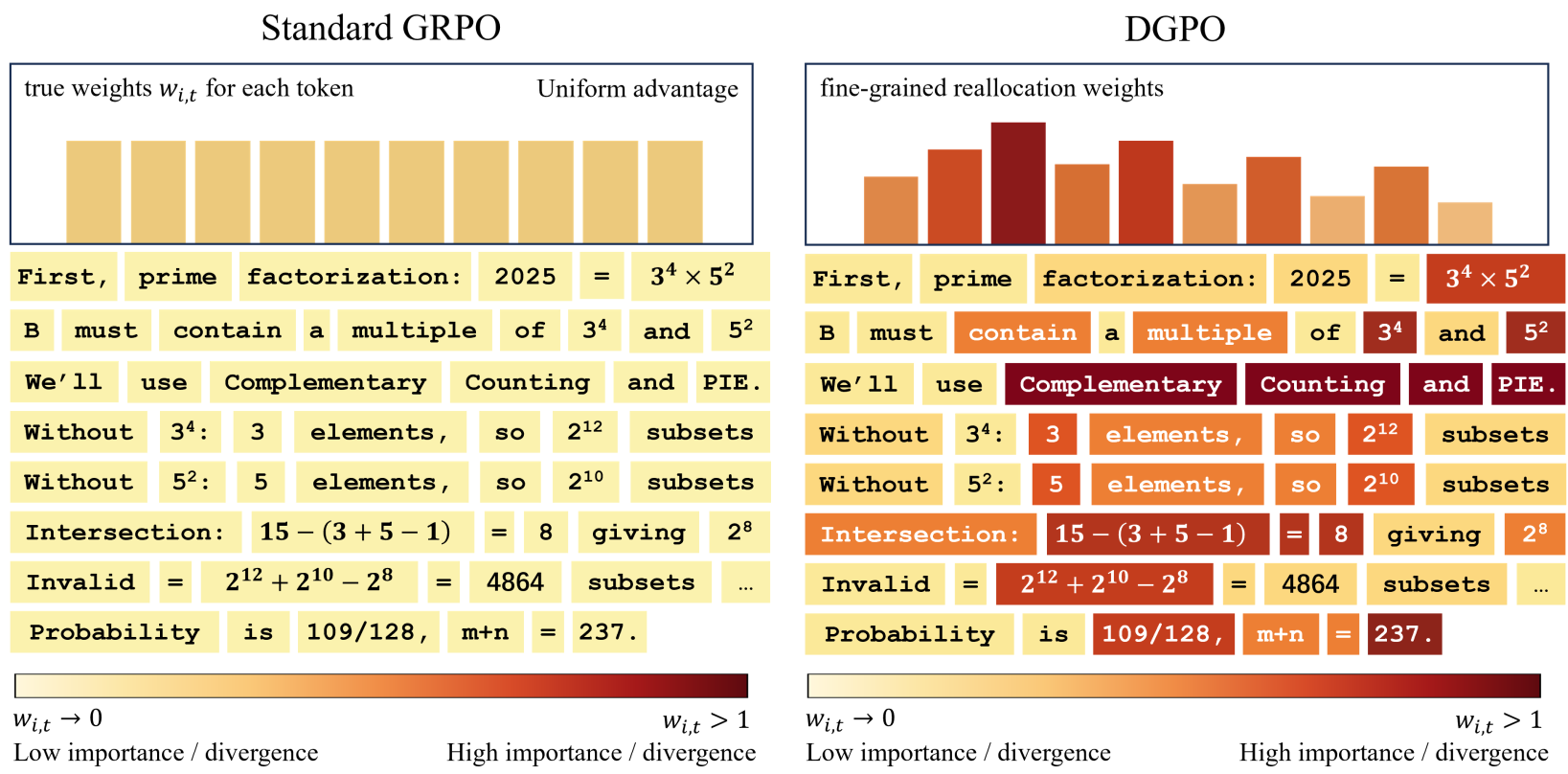 图 4:Token 级信用分配可视化,深色部分即为被 DGPO 识别出的“关键决策点”。
图 4:Token 级信用分配可视化,深色部分即为被 DGPO 识别出的“关键决策点”。
总结与启示
DGPO 的成功告诉我们:强化学习中的“惩罚”不应该是僵化的约束,而是可以转化为进化的动力。 它巧妙地利用了模型在训练过程中的“认知偏差”和“不确定性”来反哺训练,无需昂贵的人工过程标注,也能让模型学会深度思考。
局限性:目前实验主要集中在数学领域。这种基于概率测度(Hellinger/Entropy)的分配方式在创意写作等“分布更发散、目标更模糊”的任务中是否依然有效,值得进一步探索。