本文提出了 Prior-Aligned Autoencoder (PAE),一种旨在优化隐空间流形结构以提升生成性能的图像分词器。通过引入空间结构、局部连续性和全局语义三种正则化,PAE 在 ImageNet 256x256 上实现了 SOTA 的 gFID (1.03),并显著加快了扩散模型的收敛速度。
TL;DR
在 Latent Diffusion Models (LDMs) 的世界里,分词器 (Tokenizer) 决定了生成任务的“战场”。传统的 VAE 过度关注于如何“还原像素”,却忽视了这些像素在隐空间里是否让扩散模型“易于学习”。本文提出的 PAE (Prior-Aligned Autoencoder) 通过显式地对齐视觉基础模型 (VFM) 先验,构建了一个在空间、连续性和语义上都更完美的隐流形,在 ImageNet 上刷写了 1.03 gFID 的新记录,且收敛速度提升了 13 倍。
痛点深挖:重建得好,不代表生得好
学术界长期存在一个误区:只要 VAE 的重建 FID (rFID) 足够低,下游的扩散模型生成效果 (gFID) 就会自然变好。然而,作者通过对照实验发现(如下图 2a),当隐通道维度增加时,重建质量虽然在稳步提升,生成质量却可能停滞不前甚至倒退。
原因在于“重建-生成不匹配” (Reconstruction-Generation Mismatch):
- 空间破碎化:隐空间的 Token 之间缺乏连贯的空间拓扑。
- 流形突变:隐空间中微小的微扰可能导致解码后的图像发生巨大的感知剧变,使得扩散模型难以平稳预测。
- 语义混沌:语义相近的样本在隐空间里可能被抛得极远。
核心逻辑:定义“扩散友好”的隐空间
作者指出,一个对扩散模型友好的隐流形必须具备三要素:
- 空间结构连贯性 (SSC):每个 latent 内部的 Token 关系应体现真实的物体结构。
- 局部感知连续性 (LPC):流形应该是光滑的,支持平滑的去噪轨迹。
- 全局语义质量 (GSQ):相似语义的样本应在隐流形上聚集。
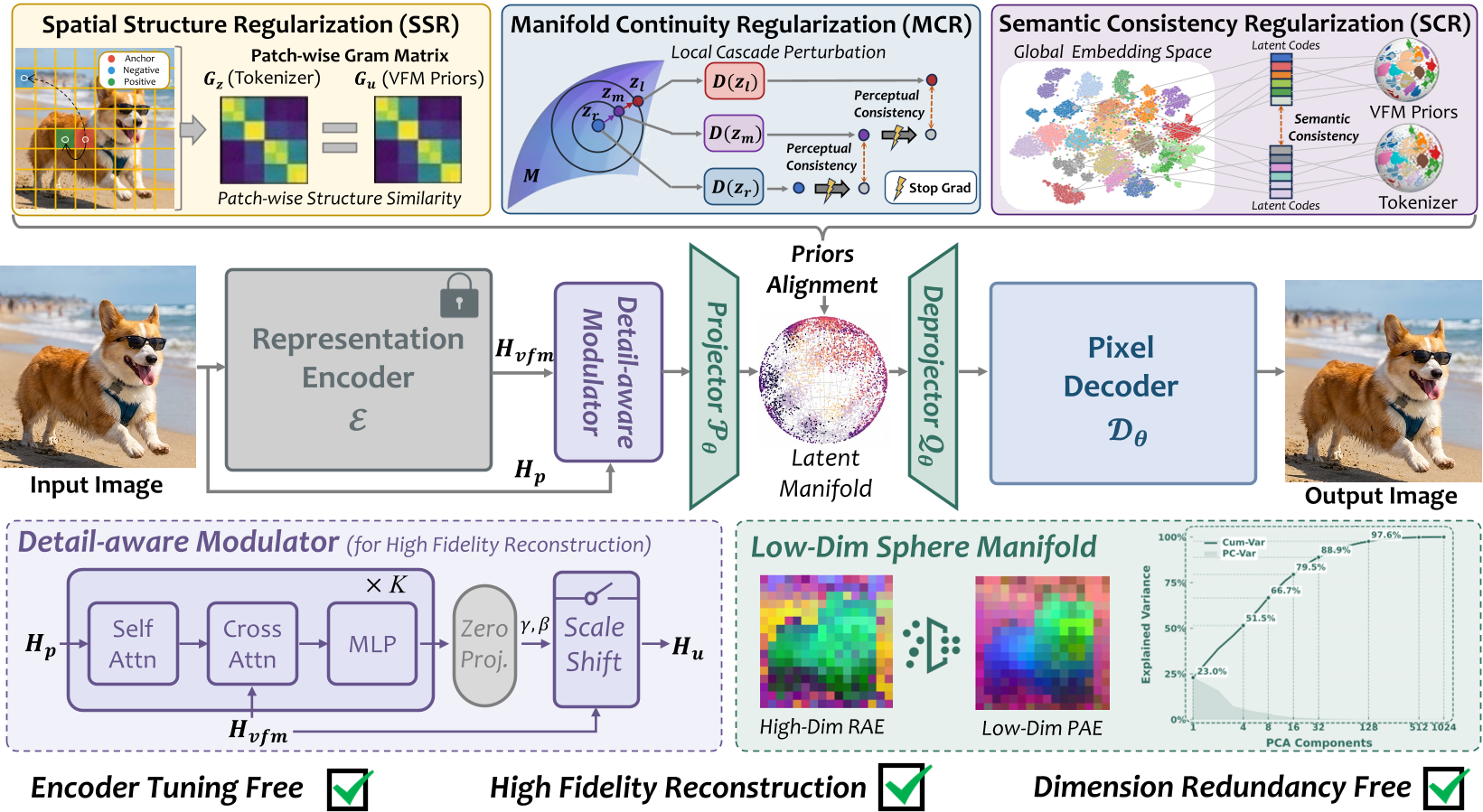
方法论详解:PAE 如何塑造流形?
PAE 并非简单地蒸馏 VFM 的特征。它采用了以下精密的正则化设计:
1. 细节预测调节器 (DAM)
单纯使用 VFM 特征(如 DINOv2)由于抽象度太高,往往丢失高频细节。PAE 引入了 DAM (Detail-aware Modulator),它通过 Cross-Attention 将像素级细节注入到冻结的 VFM 特征中,既保留了先验结构,又解决了重建模糊的问题。
2. 空间结构正则化 (SSR)
通过对齐 Latent Token 和 VFM 特征的 Gram 矩阵,确保空间拓扑一致性,让生成模型不必浪费容量去“补偿”空间错位。
3. 级联扰动连续性正则化 (MCR)
这是本文的精髓之一。PAE 并不只是强迫带噪 latent 还原原图,而是构建了“中度扰动”到“无扰动”、“重度扰动”到“中度扰动”的一致性级联。这种设计让解码器在 latent 的邻域内表现得极其灵活且稳定。
4. VFM 先验精炼 (Refining Priors)
VFM 特征通常维度过高。作者设计了一个轻量级投影器,将 VFM 特征压缩到与 Tokenizer 匹配的规格,并进行低通滤波处理,过滤掉噪声,提取纯净的结构先验(见下图 4)。

实验战绩:SOTA 与 13 倍加速
对比所有当前主流的分词器(包括 RAE, AlignTok, FAE 等),PAE 展示了统治级的表现:
- 收敛速度:在 80 个 Epoch 时,PAE 诱导的扩散模型就已经超过了其他模型 800 Epoch 的效果。
- 极端效率:在仅使用 15 步采样时,PAE 的结果就优于基线模型的 250 步采样。
- 最高上限:800 Epoch 训练后,gFID 达到了 1.03 (ImageNet 256x256),这是目前的行业天花板。

深度洞察与总结
PAE 的成功印证了一个深刻的直觉:生成模型的瓶颈可能不在于模型架构有多大,而在于它所处的“坐标系”是否足够稳健。
核心总结 (Takeaway)
- 不要迷信重建 FID,它只是指标,不是目标。
- 隐空间的“几何光滑性”对应着推理时的“采样效率”。
- 结合 VFM 先验的最佳方式是“对齐流形”而非直接“继承特征”。
局限性与未来
目前的验证主要集中在 ImageNet。未来在超高分辨率、变长 Token(多模态统一)以及更复杂的视频生成场景下,这种基于流形的正则化是否依然稳健,值得进一步探索。