DiffusionAnything is a unified image-space diffusion policy that bridges meter-scale navigation and centimeter-scale pre-grasping motion planning. By employing multi-scale FiLM conditioning and trajectory-aligned depth reasoning, it achieves state-of-the-art performance in zero-shot generalization to novel scenes from only 5 minutes of self-supervised data per task.
Executive Summary
TL;DR: DiffusionAnything is a compact, end-to-end diffusion policy that enables a single robot model to handle both wide-area navigation (meters) and precise pre-grasping (centimeters). By replacing heavy semantic reasoning with lightweight multi-scale FiLM conditioning and trajectory-aligned depth, it achieves robust zero-shot generalization while running at 10 Hz on standard onboard hardware.
Positioning: This work moves beyond the "modular vs. VLA" debate. It provides a middle ground: a unified, geometry-informed policy that is as flexible as a foundation model but as efficient as a task-specific controller.
The Core Challenge: The Scale Gap
In robotics, navigation and manipulation have historically lived in different "worlds." Navigation is about global routing and meter-scale obstacle avoidance, while manipulation demands centimeter-level dexterity.
- The Modular Problem: Cascading separate models leads to "hand-off" failures and high latency.
- The VLA Problem: Large models like RT-2 or GR00T require massive compute and often "hallucinate" in novel spaces because they lack explicit geometric understanding.
DiffusionAnything asks: Can we use a single Diffusion UNet to solve both, simply by telling the model the 'scale' and 'focus' of the current task?
Methodology: Context-Aware Diffusion
The authors' secret sauce is Contextual Modulation. Instead of just feeding an image into a Diffusion model, they inject a context vector $\mathbf{c}$ that includes:
- Task Mode: Navigation vs. Pre-grasping.
- Depth Scale: Is 1 unit in the model a meter or a centimeter?
- Spatial Attention: Where should the robot look (the floor or the apple)?
Multi-Scale FiLM Architecture
The architecture uses Feature-wise Linear Modulation (FiLM) at different scales of the UNet. For navigation, the model prioritizes coarse scales to understand the global layout. For manipulation, it amplifies fine-scale features to pinpoint object edges.
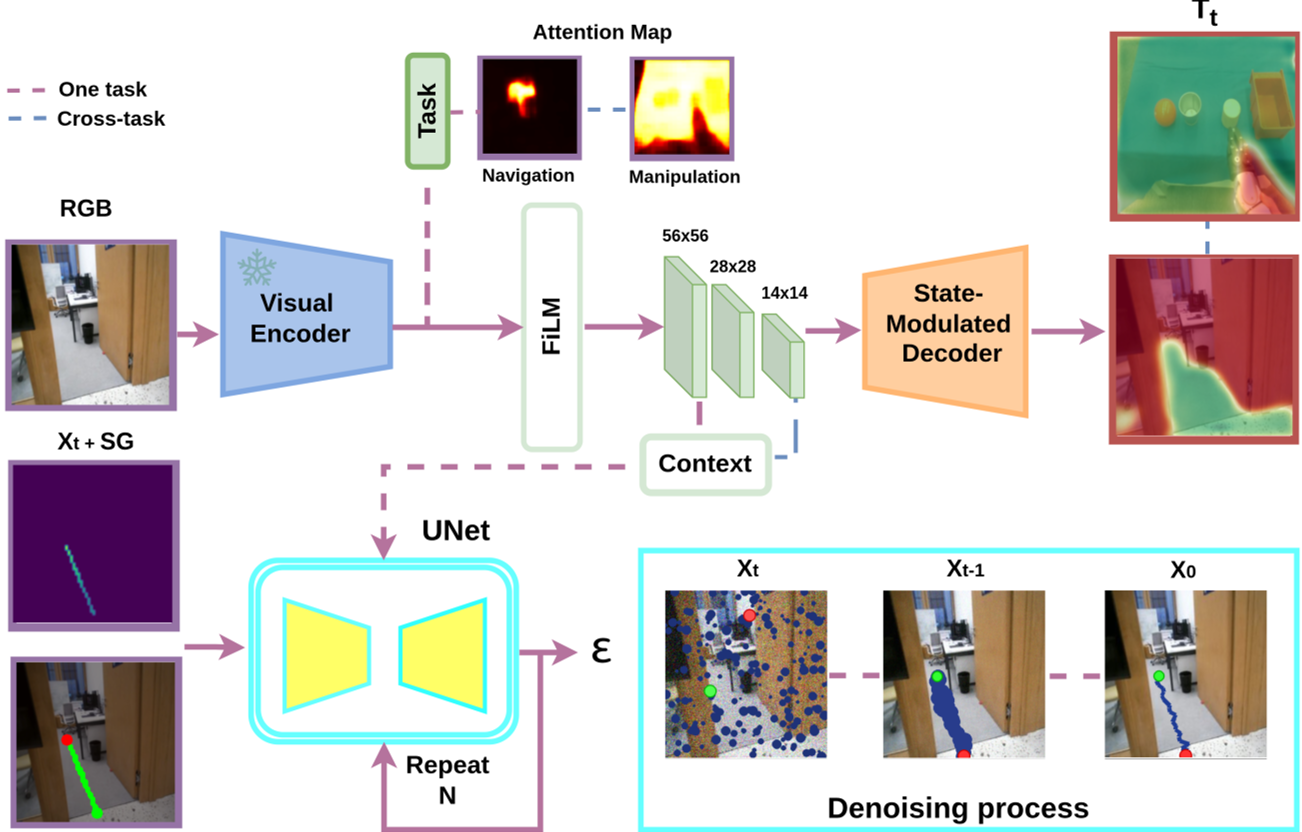 Fig 1: The Context-aware cross-task diffusion policy. Notice how the same weights are modulated to change behavior.
Fig 1: The Context-aware cross-task diffusion policy. Notice how the same weights are modulated to change behavior.
Trajectory-Aligned Depth
One of the most elegant optimizations here is Trajectory-Aligned Depth. Predicting a full depth map is slow. Instead, DiffusionAnything only predicts the depth at the specific waypoints it intends to travel. This focuses the "computational budget" exactly where it matters for collision checking.
Experiments: Real-World Superiority
The model was tested on a Unitree G1 humanoid. The training was remarkably efficient: only 5 minutes of video data per task was needed, thanks to a self-supervised pipeline (AnyTraverse) that automatically labels traversability and goals.
Key Performance Metrics:
- Navigation: 100% success rate in autonomous goal selection (0.29m accuracy).
- Pre-grasping: 4.71 cm mean error, a 6x improvement in precision over the navigation mode using the same model weights.
- Efficiency: 2.0 GB VRAM usage at 10 Hz—making it truly "onboard-ready."
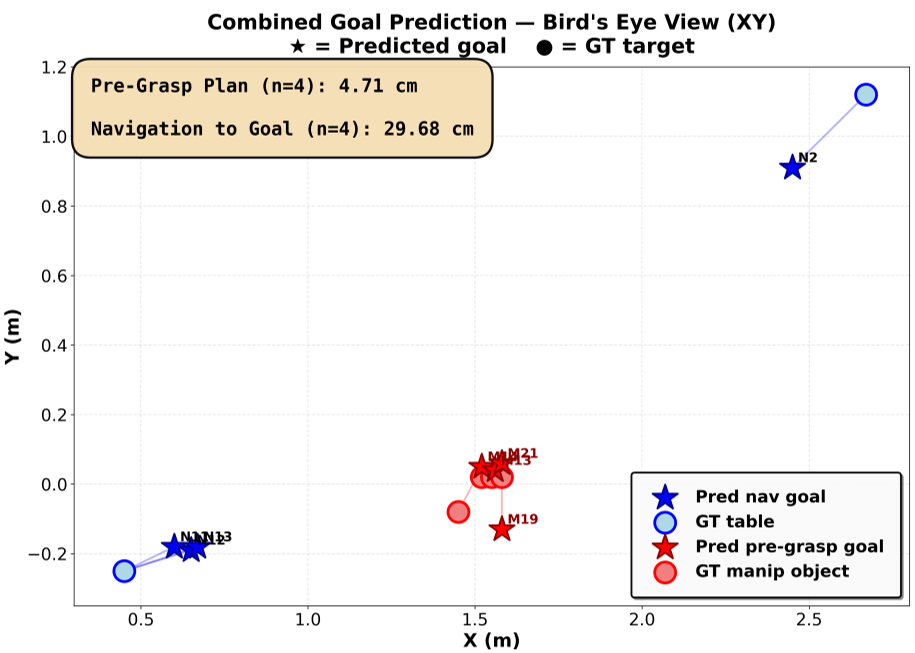 Fig 2: Goal prediction accuracy comparison showing the model's ability to switch from coarse (navigation) to fine (manipulation) precision.
Fig 2: Goal prediction accuracy comparison showing the model's ability to switch from coarse (navigation) to fine (manipulation) precision.
Zero-Shot Generalization
When compared to GR00T n1.6, DiffusionAnything excelled in novel scenes where the VLA model failed. The authors argue this is because DiffusionAnything learns geometric principles (where is the floor? where is the object distance?) rather than just memorizing visual patterns.
Critical Analysis & Future Outlook
Why it works: By conditioning on "depth scale," the model effectively learns a relative coordinate system that adapts to the task. It doesn't need to choose between being a "navigator" or a "manipulator"; it is a "spatial reasoner" that adjusts its resolution.
Limitations:
- The model currently lacks force feedback (haptic sensing).
- It relies on the quality of the AnyTraverse supervisor for initial training.
Future Impact: This research paves the way for truly generalist robots that can be deployed in a home and learn a new task (like opening a specific drawer) in under 15 minutes of observation, all while running on a single GPU.
Takeaway: If you want a robot to generalize, don't just give it more data—give it better geometric inductive biases.