本文提出了基于 DINOv3 视觉基座模型的图像篡改检测与定位(IMDL)新基线。通过引入 LoRA 适配器和轻量化卷积解码器,该方法在 CAT-Net 协议下的四个标准基准测试中,将平均像素级 F1 分数提升了 17.0 点,刷新了 SOTA 纪录。
TL;DR
在图像篡改定位(IMDL)领域,研究者们长期深陷于设计日益复杂的“专用架构”中。本文反其道而行之,通过将顶级视觉自监督模型 DINOv3 与 LoRA 适配技术相结合,构建了一个极简的新基线。实验结果令人震惊:即使是最精简的版本也超越了之前所有复杂的专用检测器,在标准测试中 F1 分数最高提升了 17 个百分点。
背景定位:从专用检测器到通用基座
传统的图像取证方法(如 CAT-Net, TruFor)依赖于捕捉噪声模式或压缩痕迹的特殊设计。然而,这些方法往往在面对未见过的篡改手段时显得捉襟见肘。本文作者敏锐地察觉到,与其在架构上“内卷”,不如利用已经在大规模数据上训练好的 Foundation Models。DINOv3 作为视觉领域的最强特征提取器之一,其对空间结构的细腻感知天然适合识别篡改区域的边缘不连续性。
痛点深挖
- 泛化困局:专用模型在 A 数据集表现优秀,但在 B 数据集(如真实世界的 IMD2020)上性能往往腰斩。
- 基准缺失:缺乏一个简单、统一且高性能的 Baseline,导致新方法难以证明其“架构复杂度”的真实价值。
- 数据敏感性:全量参数微调(Full Fine-tuning)在小规模取证数据集上极易崩盘,导致模型丧失预训练阶段获得的通用感知能力。
核心方法论:大道至简
作者提出的架构(如图 1 所示)摒弃了所有花哨的设计,仅由三部分组成:
- 特征引擎:冻结的 DINOv3 (ViT-S/B/L),利用其强大的 Dense Feature 提取能力。
- 适配层:在自注意力的 QKV 投影中嵌入 LoRA。这确保了核心表示不被破坏,同时能高效学习取证相关的特定特征。
- 解码头:仅包含 3 层简单的卷积,将特征图映射为像素级的篡改概率图。
 图 1:基于 DINOv3 的极简取证框架
图 1:基于 DINOv3 的极简取证框架
实验战绩:全线碾压
在最具代表性的 CAT-Net 协议下,基于 ViT-L 的 DINOv3 模型在多个数据集上的表现如下:
- CASIAv1: F1 达 0.907(提升显著)。
- Coverage: 对复制-粘贴这类极具迷惑性的篡改,F1 从 0.58 暴涨至 0.90。
- 参数效率:仅使用 9.1M 可训练参数,性能远超拥有数亿参数的专用 ViT 模型。
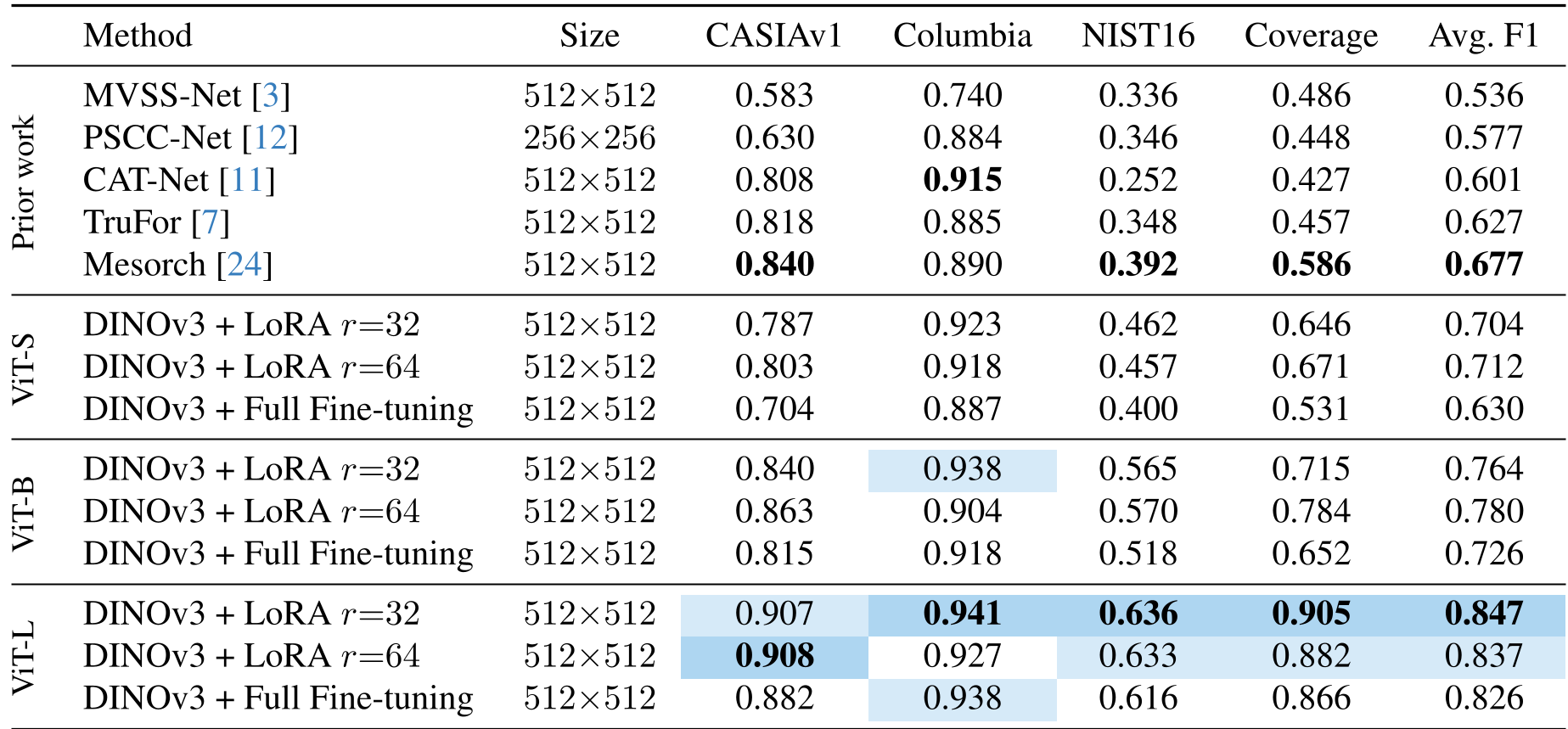 表 1:DINOv3 在 CAT-Net 协议下的卓越表现
表 1:DINOv3 在 CAT-Net 协议下的卓越表现
深度洞察:为什么 LoRA 是关键?
研究发现,在数据稀缺的 MVSS-Net 协议下,全参数微调会发生“灾难性遗忘”或训练不稳定(尤其是 ViT-S 和 ViT-B)。相比之下,LoRA 就像是一个稳压器,它保留了 DINOv3 在预训练阶段获得的、对物理世界规律的理解,仅仅通过微调低秩空间来“对齐”取证任务。这种“保留优于重写”的策略是该模型在极端任务下保持 0.774 F1 高分的秘诀。
鲁棒性与局限性
- 抗噪与抗压缩:由于 ViT 的 Patch 机制,模型对高斯噪声表现出惊人的免疫力。
- 软肋:高斯模糊(Gaussian Blur) 是该模型最大的天敌。模糊会跨越 Patch 边界破坏空间特征,导致 F1 分数出现约 47% 的大幅下滑。
总结与展望
DINOv3 该工作的意义不仅在于刷榜,更在于它为 IMDL 研究领域指明了方向:不要反复制造轮子。 强大的视觉基座模型已经包含了足够多的“取证密码”,未来的研究应更多关注如何通过更高质量、更大规模的取证数据集来激发这些基座模型的潜力。
对于开发者而言,这是一个近乎“开箱即用”的高性能取证工具,它证明了在人工智能时代,“基座模型 + 简单适配” 往往比 “复杂专用设计” 更具生命力。