The paper introduces dinov3.seg, a dedicated Open-Vocabulary Semantic Segmentation (OVSS) framework built on the DINOv3-based vision-language model. It achieves state-of-the-art results across five benchmarks, notably reaching 20.09 mIoU on ADE20K-847 and 27.80 mIoU on Pascal Context-459.
TL;DR
Open-Vocabulary Semantic Segmentation (OVSS) has long struggled with the trade-off between semantic generalization and spatial precision. dinov3.seg bridges this gap by replacing the standard global-biased CLIP backbones with a specialized DINOv3-based architecture. Through dual-stage refinement and a novel local-global inference strategy, it achieves new SOTA benchmarks (Avg. 50.44 mIoU), particularly excelling in identifying "unseen" classes in complex, cluttered environments.
The Localization Bottleneck in OVSS
The core challenge of OVSS is "dense grounding." While Vision-Language Models (VLMs) like CLIP excel at saying what is in an image, they are notoriously bad at saying where exactly it is. Their features, trained on global contrastive losses, often "bloob out" at object boundaries. Prior works tried to fix this with "late-stage" hacking—essentially refining the final heatmaps.
The authors of dinov3.seg argue that this is too little, too late. They suggest that to achieve true pixel-level accuracy, the model needs:
- Spatially Rich Backbones: Moving from CLIP to DINOv3.
- Early Intervention: Refining visual features before they even talk to the text.
- Semantic Ensembling: Using both global scene context and local object parts to describe a class.
Methodology: The Four Pillars of dinov3.seg
1. The DINOv3 Backbone & Text Ensemble
Unlike CLIP, DINOv3 features are learned via self-distillation, which naturally preserves object-centric attention. The model uses "dinov3.txt," where the image encoder is frozen (LiT strategy) and a text encoder is aligned. Innovation: Instead of just using a single text prompt, they use a Global-Local Ensemble. A class like "stairway" is aligned with the global [CLS] token (capturing the scene) and patch features (capturing the steps/railings), leading to more robust retrieval.
2. Dual-Stage Refinement
This is the "special sauce" of the paper.
- Early Refinement: Uses an "AnyUp" module to clean up noisy VLM features using local image structure before the text interaction happens.
- Late Refinement: Uses a Segment Anything Model (SAM) as a "Semantic Prior Encoder" (SPE). These structural priors guide two blocks:
- Spatial Refinement: Enhances coherence using Swin Transformer blocks.
- Class Refinement: Fixes inter-class ambiguity (e.g., distinguishing between a "chair" and a "stool").
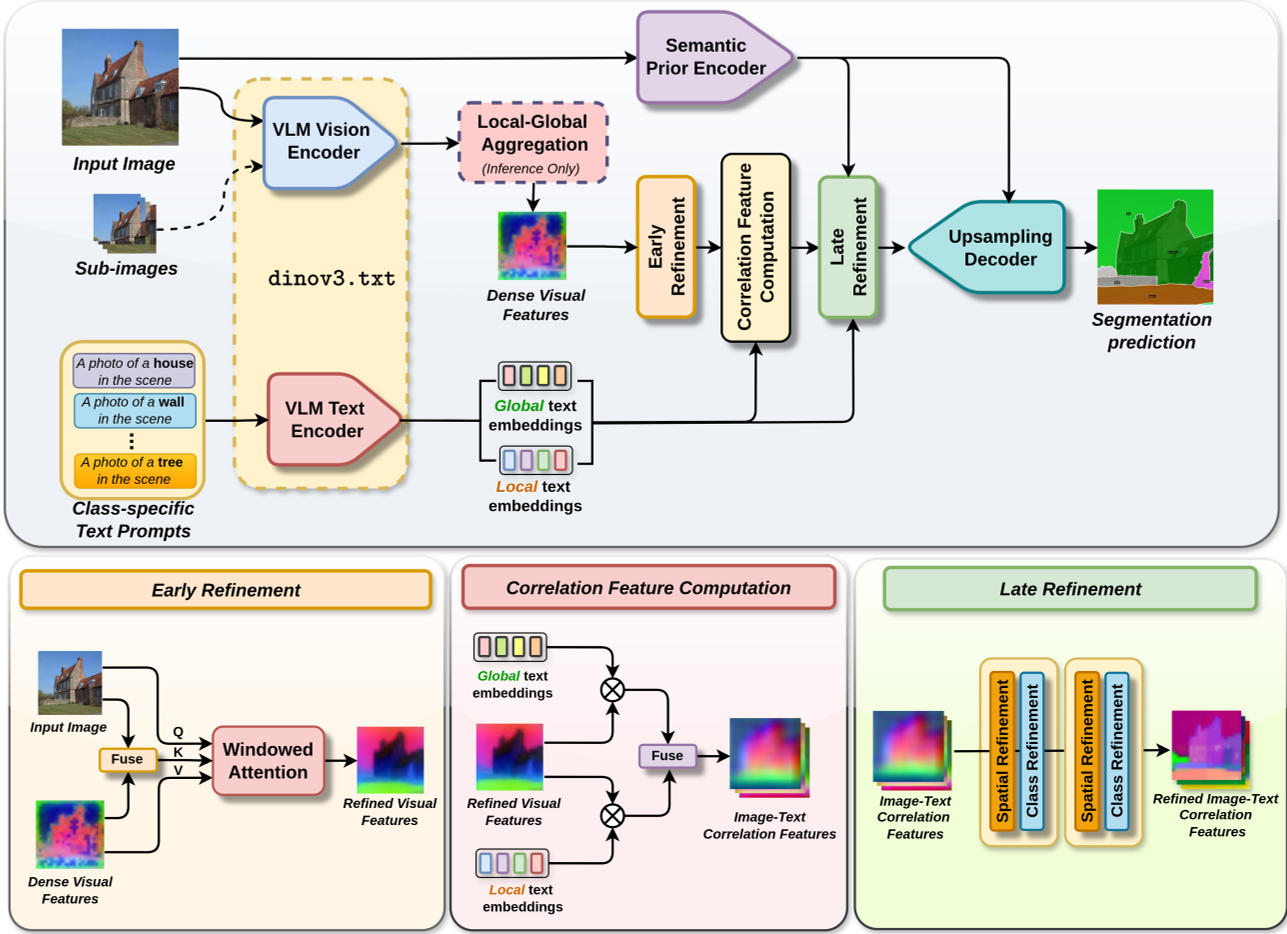
3. Local-Global Aggregation (LGA) Inference
When dealing with high-resolution images, the model uses a sliding-window approach. It processes overlapping 384x384 crops (local) and the resized 640x640 image (global) simultaneously. By averaging these features, the model keeps the "big picture" while capturing the sharp detail of small objects.
Experimental Battlegrounds
The model was tested against 15+ SOTA methods (including SAN, CAT-Seg, and FC-CLIP) on five benchmarks: ADE20K (847/150 classes), Pascal Context (459/59 classes), and Pascal VOC.
Key Result: Unseen Generalization
The most impressive feat of dinov3.seg is its ability to handle zero-shot categories. On the Pascal Context-459 dataset, the improvement on unseen classes was +4.87 mIoU over the previous best, significantly higher than its gains on "seen" classes. This proves the architecture isn't just memorizing categories—it’s actually learning to ground language into pixels.

Table 1: Quantitative results showing dinov3.seg dominating on large-vocabulary benchmarks (A-847, PC-459).
Performance vs. Complexity
While dinov3.seg has a large parameter count (1.1 Billion), its computational efficiency (GFLOPs) is actually much lower than earlier models like OVSeg.
- Inference Speed: 0.37 seconds (vs. 1.31s for OVSeg).
- Efficiency: 4,500 GFLOPs (vs. 13,500+ for SCAN).
 Visual comparison showing superior boundary fidelity in cluttered scenes.
Visual comparison showing superior boundary fidelity in cluttered scenes.
Conclusion and Future Outlook
dinov3.seg represents a paradigm shift from "Prompt-Engineering-centric CLIP-refining" to "Architecture-centric Segmentation-aware Tuning." By respecting the spatial nature of visual features and providing explicit multi-stage refinement, it sets a new bar for Open-Vocabulary tasks.
Future Work: The authors suggest that knowledge distillation from the SAM-based encoder could further slim down the model, making it suitable for real-time edge devices in robotics and autonomous driving.