本文由阿里巴巴 Qwen 团队提出,旨在通过分析强化学习与可验证奖励(RLVR)过程中模型更新的“方向”而非仅仅是“幅度”,来提升 LLM 的推理能力。核心方法是利用 Token 级的对数概率差()来识别关键更新,并据此设计了测试时外推和训练时重加权策略,在数学推理任务上显著超越了 DAPO 等 SOTA 基线。
TL;DR
大语言模型的推理能力在强化学习(RLVR)后突飞猛进,但这种改进是如何发生的?阿里巴巴 Qwen 团队的研究发现:改进并非全局性的,而是发生在极少数“关键 Token”上。通过引入 (对数概率差) 这一新视角,我们不仅能精准识别这些 Token,还能在不增加训练的情况下通过测试时外推(Test-time Extrapolation)进一步压榨模型性能。
痛点深挖:幅度(Magnitude)的盲区
在分析模型微调前后的差异时,学术界惯用 Entropy(信息熵)或 KL Divergence(散度)来衡量变化。然而,这篇论文指出,这些指标只告诉了我们“变化的大小”,却没告诉我们“变化的方向”。
如下图所示,Entropy 和 KL Divergence 在 Base 和 RLVR 模型上的直方图几乎重合,这意味着它们无法区分哪些变化是有利于推理的。而 展示了完美的双峰结构,清晰地划定了两个模型的“偏好边界”。

核心直觉:更新越稀疏,价值越高
为什么 RLVR 带来的改变是稀疏的?作者给出了一个优雅的数学解释(Lemma 3.1):在 Policy Gradient 更新中,梯度的范数与 成正比。 这意味着:模型越不确定的低概率 Token,获得的梯度更新越大。
通过 Token 替换实验证明:我们只需要把 Base 模型生成的回复中,那不到 10% 的关键 Token 换成 RLVR 模型的选择,就能直接达到 RLVR 模型的推理水平。
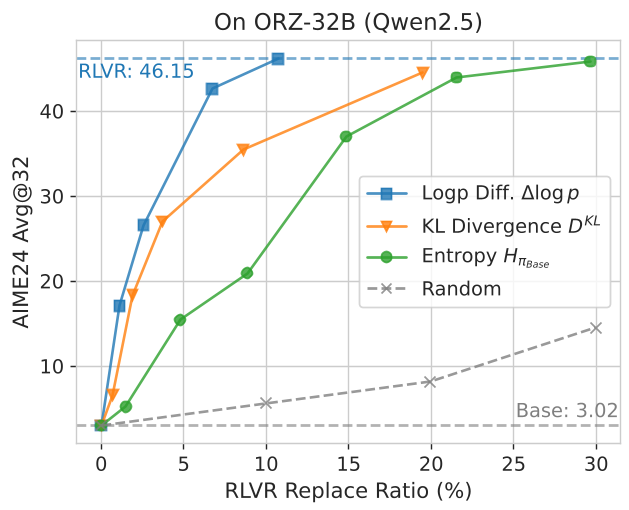
方法论详解:从“识别”到“利用”
1. 测试时选择性外推 (Selective Extrapolation)
既然 代表了“推理的方向”,那我们能不能在这个方向上走得更远?作者提出了外推公式: 通过这种方式,在解码阶段人为放大 RLVR 已经学到的推理信号。这种方法在 AIME 和 Minerva 等多个基准测试中稳定提升了性能,甚至超越了 RL 训练的上限。
2. 训练时优势重加权 (Advantage Reweighting)
在 RLVR 训练阶段,作者通过修改优势函数 ,主动引导模型关注那些低概率的 Token: 这种“概率感知”的加权策略让模型在有限的步骤内更高效地学习 reasoning-critical 的逻辑转折。
实验与结果:全方位吊打基线
在 Qwen2.5-Math 和 Qwen3 模型上的实验显示,该方法在 AIME24/25 和 AMC 等硬核数学竞赛题库上表现优异。特别是对于 Qwen3-8B-Base,使用本方法后的推理精度(Avg@32)从 44.26% 提升到了 46.78%。
深度洞察:这对未来的启示
这篇论文最深刻的价值在于它打破了“越多数据、越大计算量”的迷思。它告诉我们:
- 推理是定向的:不是所有的概率提升都有助于逻辑。
- 低概率 Token 是宝藏:模型感到“困难”的地方(Low-prob),正是 RLVR 真正起作用的地方。
- 测试时干预的潜力:我们不需要每次都重新训练模型,通过对比 Base 模型和微调模型的差异,我们可以在推理测(Inference-side)直接“合成”出更强大的推理模型。
总结: 想要 LLM 变得更聪明?别只看它改了多少,要看它改向了哪里。