本文推出了 DR-Venus,一个参数量仅为 4B 的前沿边缘级深度搜索助手(Deep Research Agent)。该模型完全基于 10K 条开源数据,通过改进的数据质量管理和基于信息增益(Information Gain)的强化学习,在多个深度搜索基准测试中超越了 9B 以下的所有模型,并逼近了 30B 级系统的性能。
TL;DR
在 AI Agent 领域,"Deep Research"(深度搜索/调研)一直被认为是 30B 甚至 100B 以上大模型的专利,因为这需要极强的长程规划、工具调用稳定性及信息聚合能力。蚂蚁集团 Venus 团队发布的 DR-Venus-4B 打破了这一固有印象。凭借全新的 IGPO (Information Gain-based Policy Optimization) 强化学习算法和精细的数据配方,这个 4B 小模型在多个榜单上不仅碾压了同级别的 7B/9B 模型,甚至在 Pass@16 评估下通过“思维缩放”接连挑落了 GPT-5 等顶尖闭源模型。
背景定位
DR-Venus 的出现标志着 边缘侧 Agent 进入了“深水区”。它不仅能简单回答问题,还能像人类调研员一样,在互联网上反复搜索、打开网页(Browse)、提取证据、交叉验证。该工作在学术坐标系中处于“高效数据利用”与“高密度强化学习”的交汇点。
痛点深挖:为什么小模型做不了长调研?
传统的 Agent 训练面临两个核心局限:
- 数据质量的“放大效应”:小模型不像 70B 模型那样具备强大的容错性。如果 SFT 轨迹中存在格式混乱或无效的搜索步骤,小模型会迅速学坏,导致推理崩溃。
- 强化学习的“稀疏奖励陷阱”:在长达 200 个 Turn 的调研任务中,只有最后给出的答案对错才是唯一反馈(Outcome Reward)。对于 4B 模型,随机采样到正确答案的概率极低,导致训练早期拿不到正向信号,陷入“优势塌陷”。
核心机制:SFT 重采样 + IGPO 奖励设计
1. Agentic SFT:不只是量大,更要“够长”
作者对 10K 条 REDSearcher 开源轨迹进行了魔改。核心操作是 Turn-aware Resampling:人为提升长轨迹的采样权重。
- 50 步以下的轨迹权重为 1x。
- 100 步以上的轨迹权重直接拉到 5x。 这强行训练了小模型在极长上下文下的耐力。
2. Agentic RL:用“信息增益”喂饱模型
模型不再只是“赌”最后的答案对不对,而是评估每一步操作带来了多少 信息增益 (Information Gain, IG)。

- Turn-level Rewards:模型每一步操作后,计算其使预测正确答案概率提升的程度。
- 格式正则化 (Format Penalty):如果模型在调用工具时写错了 XML 格式,立刻给予惩罚,这比轨迹结束再惩罚要精准得多。
实验与结果分析
在 BrowseComp 等深度搜索基准上,DR-Venus 的表现令人惊艳:
| 模型规格 | Model | BrowseComp (EN) | BrowseComp-ZH | | :--- | :--- | :---: | :---: | | 4B (Ours) | DR-Venus-4B-RL | 29.1 | 37.7 | | 4B | AgentCPM-4B | 24.1 | 29.1 | | 32B | DeepMiner-32B | 33.5 | 40.1 | | 闭源 | GPT-5 High | 54.9 | 65.0 |
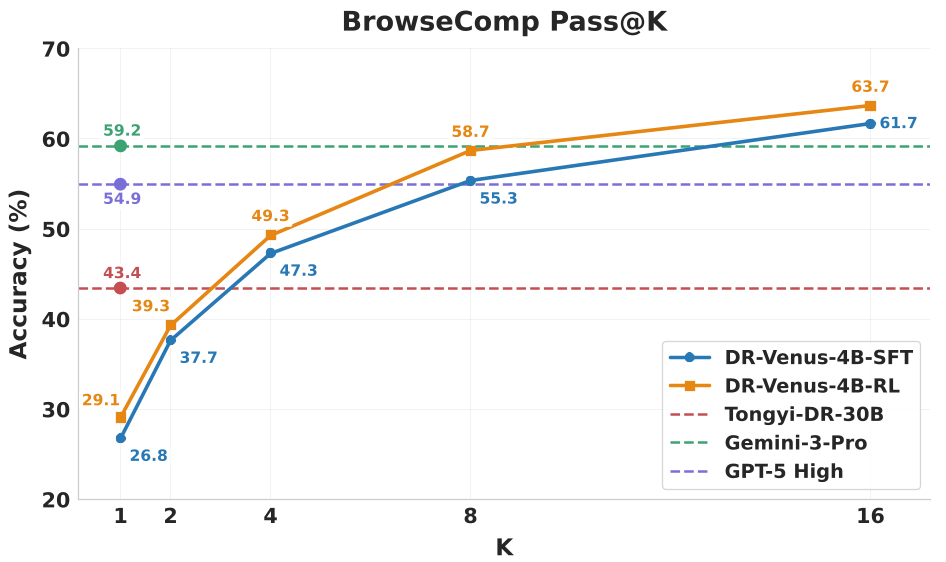 如上图所示,当增加采样次数(Pass@16)时,DR-Venus-4B 的潜力可以被挖掘到 78.5% 以上,这意味着小模型本身已经具备了解决复杂任务的“上限”,缺的是输出的稳定性。
如上图所示,当增加采样次数(Pass@16)时,DR-Venus-4B 的潜力可以被挖掘到 78.5% 以上,这意味着小模型本身已经具备了解决复杂任务的“上限”,缺的是输出的稳定性。
行为洞察:RL 教会了模型“深读”
通过对工具调用的分析,作者发现经过 RL 训练后,模型更倾向于使用 browse(阅读网页详情)而非仅仅停留在 search(查看搜索摘要)。在成功 trajectory 中,浏览占比显著更高。RL 成功纠正了小模型“只搜不看”的浮躁行为。
深度洞察与总结
- 数据的效率远胜规模:仅依靠 10K 左右的高质量开源数据,通过精巧的 RL 方法(IGPO),4B 模型就能在特定领域(Deep Research)与 30B 模型掰手腕。
- 测试时缩放(Test-time Scaling)的奇迹:DR-Venus 在 Pass@16 下的惊人表现预示着,未来边缘侧 Agent 的核心竞争力可能不在于模型参数量,而在于如何通过搜索和思维验证来换取性能。
- 局限性:目前的训练仍高度依赖于已知答案的 Query 对(QA Pairs),如何实现在完全无监督或在线环境下的自主进化,仍是下一步的挑战。
总结:DR-Venus 证明了“边缘调研专家”是完全可行的。它不仅降低了深度调研的门槛,更为隐私敏感、低功耗的 Agent 部署指明了方向。