本文提出了 Dream-MPC,一种基于梯度的模型预测控制(MPC)方法。它通过在学习到的隐空间(Latent Space)中,结合策略网络生成的候选轨迹、不确定性正则化以及动作跨时间重用机制,在 24 个连续控制任务中实现了 SOTA 性能,并克服了以往梯度 MPC 方法表现不如无梯度方法的难题。
TL;DR
长期以来,强化学习社区一直存在一个“魔咒”:在利用环境模型进行规划时,基于梯度的优化(Gradient-based MPC)在实践中往往输给简单的随机采样方法。本文提出的 Dream-MPC 正式打破了这一僵局。它通过策略引导初始化、不确定性约束和历史动作重用,在显著降低计算量的前提下,在 24 个高维控制任务上刷新了 SOTA 战绩。
1. 痛点:为什么梯度 MPC 以前“不行”?
在 Model-based RL 中,我们希望通过最小化预测代价来寻找最优动作序列。
- 无梯度方法(如 CEM/MPPI):简单粗暴,通过并行采样成千上万条轨迹找最好的。但在高维空间(如人形机器人控制),搜索空间呈指数级增长。
- 梯度方法:本应更高效,但面临两个死穴:
- 局部最优:从随机初始化开始优化,极易陷入局部的“坑”里。
- 模型过度开发(Model Exploitation):模型总有误差,优化算法会专门寻找模型“以为很强”但物理上错误的动作。
2. 核心机制:Dream-MPC 的三大法宝
Dream-MPC 的架构逻辑在于“少而精”。它不再盲目采样,而是精准引导优化过程。
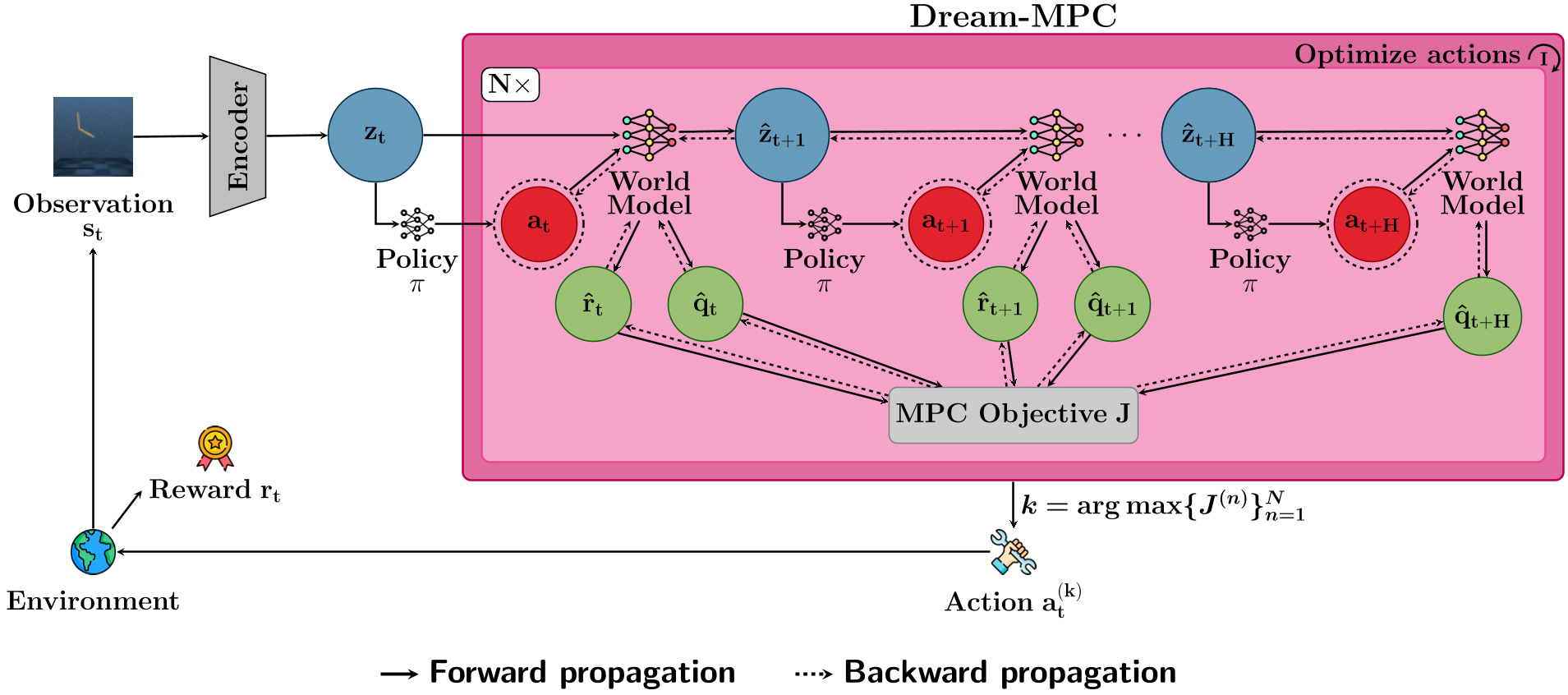
2.1 策略预热(Warm-start)
与其从纯噪声开始,Dream-MPC 从训练好的策略网络 中采样 个(通常仅 5 个)轨迹方案。这为梯度上升提供了一个极佳的起点,使其能够迅速向全局最优收敛。
2.2 不确定性正则化
为了防止模型“自欺欺人”,作者在目标函数 中引入了惩罚项项: 其中 是 Q 函数集成(Ensemble)的预测标准差。不确定性越高,得分越低,强制规划器选择更有把握的动作。
2.3 动作重用与摊销(Amortization)
为了提高效率,Dream-MPC 会将上一时刻优化好的动作序列按照比例 传递给当前时刻。这种“记忆”功能使得算法在每步计算时,即使只进行 1 次梯度迭代也效果卓群。
3. 实验结果:全方位吊打基准
实验覆盖了 DeepMind Control Suite, HumanoidBench 和 Meta-World 共 24 个任务。
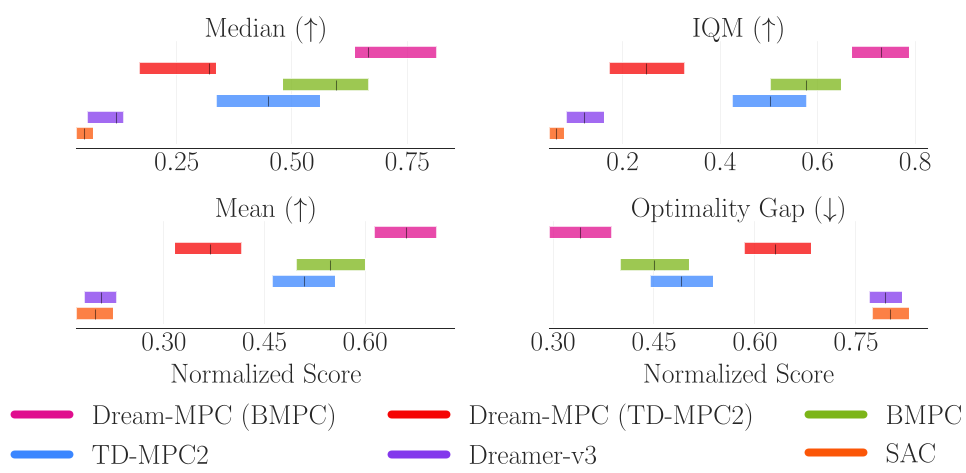
3.1 性能与稳定性
在 BMPC 模型基础上,Dream-MPC 的所有关键指标(IQM, Mean, Median)均大幅优于原始 MPPI 采样和 Dreamer-v3 等基线。
3.2 极端效率提升
这是最令人振奋的数据:
- TD-MPC2 (MPPI):每步需要 9216 次 模型评估。
- Dream-MPC:每步仅需 15 次 模型评估。 在计算量缩小几百倍的情况下,依然实现了性能反超。在其测试平台上,推理延迟保持在 18ms 左右,完全满足机器人实时控制(50Hz+)的需求。
4. 深度洞察:为何它能更稳?
通过对梯度信号的 SNR(信噪比)分析发现,Dream-MPC 的梯度稳定性随规划长度增加的衰减速度比传统 Grad-MPC 慢得多。这说明策略引导和不确定性约束有效地将优化路径框定在了模型预测准确的可信区域内。
5. 总结与展望
Dream-MPC 重新证明了梯度 MPC 的生命力。它不仅解决了高性能控制中计算量的大头问题,还通过优雅的正则化手段平衡了“探索”与“稳健”。未来的研究方向可能包括自动调节优化步长 以及将此框架扩展到多任务的大规模预训练世界模型中。
一句话总结:如果你觉得 MPPI 采样太慢且在高维空间失效,Dream-MPC 提供的基于梯度的“精准打击”方案正是你需要的。