本文推出了 DreamerAD,这是首个利用潜空间世界模型(Latent World Model)实现高效强化学习(RL)的自动驾驶框架。该方法通过 Shortcut Forcing 技术将扩散模型的采样从 100 步压缩至 1 步,在保持视觉可解释性的同时实现 80 倍加速,并在 NavSim v2 挑战赛中以 87.7 EPDMS 刷新了 SOTA 纪录。
TL;DR
DreamerAD 是自动驾驶领域首个真正意义上兼具生成式高保真度与强化学习高交互频率潜空间世界模型。它成功解决了扩散模型推理慢的顽疾,通过 Shortcut Forcing 将 100 步采样压缩至 1 步,并在潜空间内直接构建奖励模型,让决策 agent 在 0.03s 内就能完成一次“预见未来”并进行自我优化。
背景定位:这是自动驾驶世界模型从“好看”向“好用(可训练)”跨越的关键工作,属于 SOTA 性能刷榜与系统架构创新的结合。
1. 痛点深挖:为什么之前的世界模型没法练 RL?
强化学习(RL)是解决自动驾驶“长尾问题”的终极武器,但它是一个极度“吃数据”的过程。在真车上试错成本太高,在常规 Simulator(如 CARLA)里又有严重的 Sim-to-Real Gap。
由于视频生成式世界模型(Video World Models)能生成极其逼真的驾驶场景,理论上是完美的 RL 模拟器。然而,基于 Diffusion 的模型每一帧都要迭代几十上百次,延迟高达几秒。想象一下,如果教练要花 2 秒钟才能告诉你刚才那脚刹车踩得对不对,你永远学不会开车。
此外,像素级的重建损失(MSE/LPIPS)并不能直接反映驾驶安全性。模型可能生成了一个漂亮的街景,但车轮下的物理约束可能是错位的。
2. 核心机制:DreamerAD 的三板斧
2.1 Shortcut Forcing:单步跨越扩散鸿沟
作者提出了一种递归的步长压缩机制。不同于普通的蒸馏,Shortcut Forcing 在 Rectified Flow 框架下,将采样过程离散化为 2 的幂次方步长空间。通过教师-学生蒸馏模式,模型学会在给定当前信号水平 和目标步长 的情况下,直接预测跨越 的速度向量。
这使得模型在推理时可以“抄近路”,直接从 甚至一步跳到 ,推理速度从原本的每帧 2.0s 降至 0.03s。
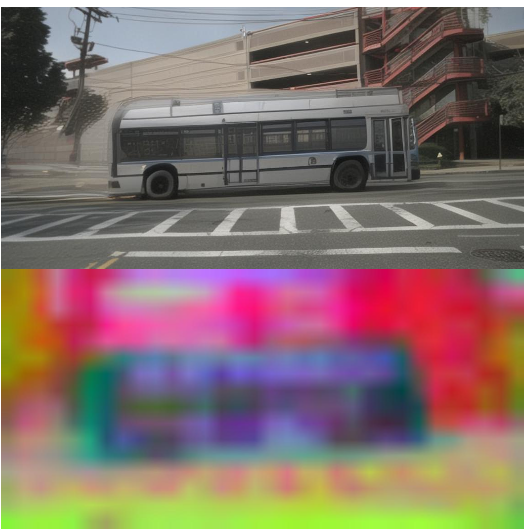 图 1:世界模型在不同轨迹引导下的想象训练。红色代表高碰撞风险,绿色代表安全路径。
图 1:世界模型在不同轨迹引导下的想象训练。红色代表高碰撞风险,绿色代表安全路径。
2.2 AD-RM:潜空间里的“裁判员”
为了让奖励信号更实时,DreamerAD 不再等待完整的视频解码。它直接在 Latent Features(潜特征)上构建了一个自回归密集奖励模型。通过简单的感知器处理 512 维的潜向量,实时给出 8 个维度的驾驶评分。
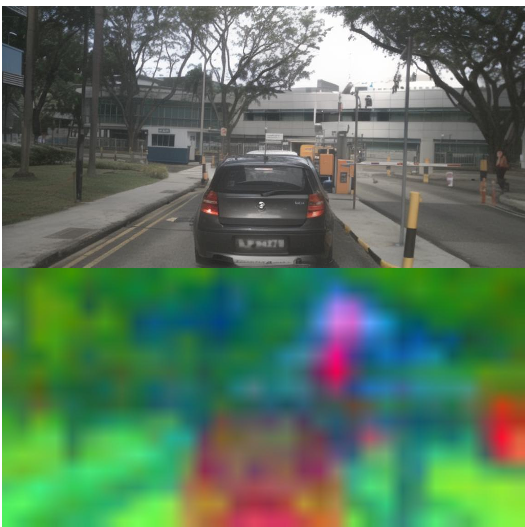 图 2:潜空间特征的 PCA 可视化。可以看到特征在潜空间中已经具备了极强的空间一致性和语义逻辑。
图 2:潜空间特征的 PCA 可视化。可以看到特征在潜空间中已经具备了极强的空间一致性和语义逻辑。
2.3 高斯词汇采样:物理约束下的探索
在 RL 的探索阶段,如果任由模型随机尝试,经常会产生不符合物理定律的轨迹,从而诱发世界模型的生成幻觉(Hallucinations)。DreamerAD 从 8192 个高质量人类驾驶轨迹库中通过高斯分布进行采样,确保 agent 的每一次尝试都在“物理可能的流形”内,极大提升了训练稳定性。
3. 实验战绩:全方位的安全性提升
DreamerAD 在 NavSim v2 闭环测试中展现了统治力。其 EPDMS 分数达到 87.7,相比于目前最先进的 Epona 基线提升了 2.6 个百分点。
| 指标 | Epona (Base) | DreamerAD (Ours) | 提升幅度 | | :--- | :--- | :--- | :--- | | 无碰撞 (NC) | 97.1 | 98.0 | +0.9 | | 车道保持 (LK) | 97.0 | 97.5 | +0.5 | | 舒适度 (EC) | 67.8 | 72.4 | +4.6 | | 综合评分 (EPDMS) | 85.1 | 87.7 | +2.6 |
消融实验证明:
- Shortcut Forcing 不仅提升了速度,还通过减少累积误差提升了生成质量(见下表对比)。
- 单步推理 (1-step) 的性能几乎与 16 步持平,但延迟降低了 13 倍。

4. 深度洞察:为什么这很重要?
DreamerAD 的成功说明了端到端自动驾驶不应该只有一套“看图说话”的逻辑,还必须具备“事后总结”的闭环学习能力。
- 特征的高效复用:它证明了预训练的视频生成器潜特征已经捕捉到了足够的安全语义(如障碍物距离、车道线拓扑),无需昂贵的 3D 检测标注也能训练 RL。
- 速度即一切:在 AI 研究中,100 倍的速度提升往往意味着从“不可能实验”变为“日常迭代”。
局限性: 目前模型在 Ego Progress(行驶进度)上略有下降(-0.8),这表明在强化学习优先保证安全的前提下,模型倾向于采取更为“保守”的驾驶策略,如何在安全性与通行效率之间达成更完美的帕累托最优(Pareto Optimality)是未来的研究重点。
总结
DreamerAD 为自动驾驶在大规模世界模型中进行低成本、高效率的策略进化指明了方向。未来,当我们拥有更强大的基础模型(如 Cosmos 或 Sora 级别)时,这种基于潜空间的强化学习框架将释放出更大的潜力。