The paper introduces Drive My Way (DMW), a personalized Vision-Language-Action (VLA) driving framework that aligns autonomous vehicle behavior with both long-term driver habits and real-time natural language instructions. By leveraging a novel Personalized Driving Dataset (PDD) and reinforcement fine-tuning (GRPO), DMW achieves state-of-the-art adaptation in closed-loop benchmarks like Bench2Drive, significantly outperforming generic E2E models.
TL;DR
Most autonomous vehicles drive like robots—predictable, rigid, and indifferent to whether you are in a rush or enjoying a leisurely Sunday drive. Drive My Way (DMW) changes this by introducing a Vision-Language-Action (VLA) framework that learns your long-term habits and listens to your real-time commands. By combining user embeddings with a residual policy tuned via reinforcement learning, DMW achieves a "human-in-the-loop" experience that mimics individual driving styles without compromising safety.
The Motivation: Why "One Size Fits All" Fails
Standard end-to-end (E2E) driving models are trained on "expert" data to find the single most optimal path for safety and efficiency. However, human driving is inherently subjective:
- The "Late for Work" Dilemma: An aggressive driver might take a tight gap in a merge.
- The "Cautious Commuter": A conservative driver prefers a large Time-to-Collision (TTC) buffer.
- The Intent Gap: Current systems can't process a command like "I'm tired, take it easy" into a specific adjustment of braking pressure or steering smoothness.
DMW addresses this by treating driving not just as a geometric problem, but as a preference alignment problem.
Methodology: The Architecture of Personality
The core of DMW is its ability to fuse long-term "who you are" (Profile) with short-term "what you want" (Instruction).
1. Long-term Preference Encoder
The researchers built the Personalized Driving Dataset (PDD), involving 30 real drivers. They used a contrastive learning objective (InfoNCE) to align a driver's text profile (experience, habits) with their actual driving trajectories. This creates a User Embedding ($z_p$) that acts as a latent personality prior.
2. The Residual Decoder Strategy
Rather than forcing the model to learn driving from scratch, DMW uses a SimLingo VLA backbone to generate a "Safe Base Action." It then adds a Residual Decoder that predicts small adjustments ($\Delta$) to speed and steering based on the user embedding and language prompt.
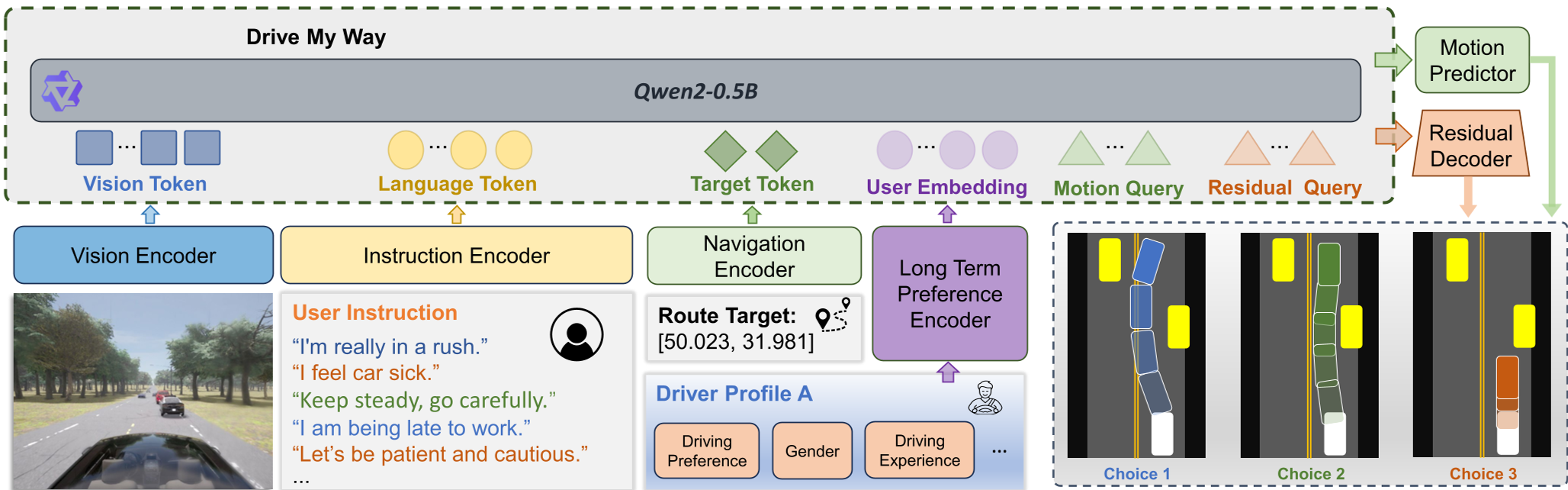
3. Style-Aware Reward Adaptation
To fine-tune this with RL (specifically GRPO), the team used an LLM (GPT-5 equivalent) to dynamically adjust reward weights ($w_s, w_e, w_c$). If a user says "I'm in a rush," the efficiency weight ($w_e$) increases, while the safety threshold ($\beta_{safety}$) becomes more "permissive" within safe legal bounds.
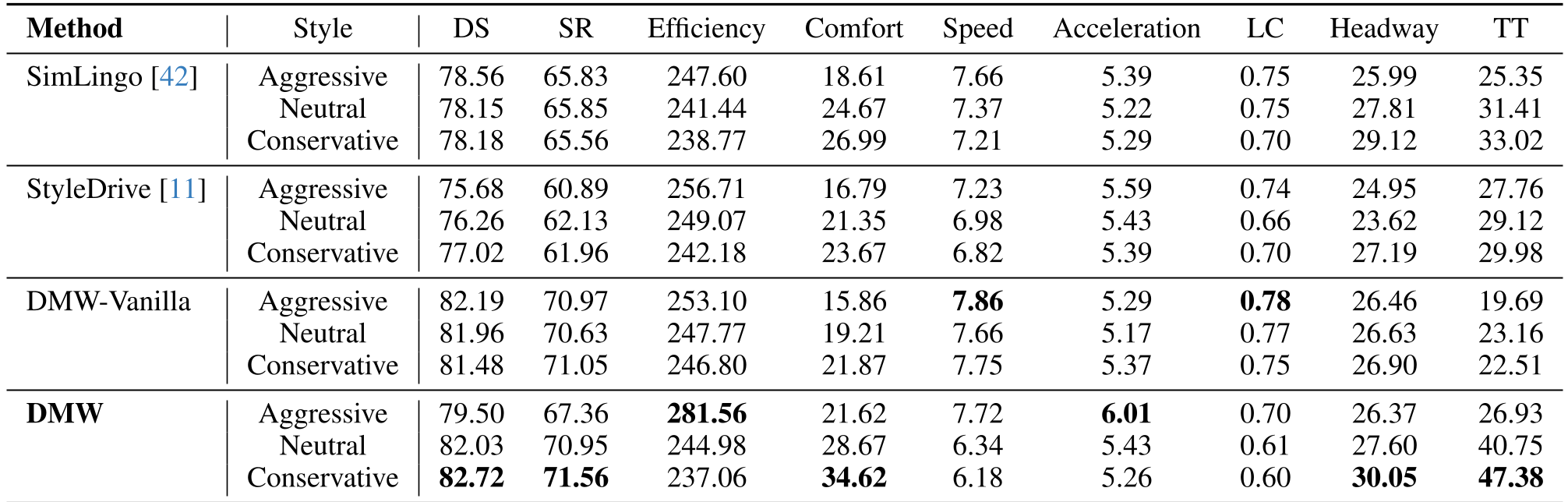
Experimental Results: Does it actually drive like "Me"?
The model was tested in the CARLA simulator on the Bench2Drive benchmark.
- Instruction Following: DMW showed a massive shift in behavior between styles. Under "Aggressive" instructions, average speed and acceleration increased significantly while "Conservative" instructions led to much larger headways and smoother braking.
- Safety vs. Style: Unlike previous models that lose safety when pushed to be aggressive, DMW maintained a high Success Rate (SR) because the personalization is a residual on top of a safe foundation.
- Human Recognition: In user studies, evaluators could identify which driver the AI was mimicking with high accuracy (Alignment Score of 0.92).
Deep Insights & Future Outlook
The "Residual" approach is the most brilliant part of this work. By decoupling the fundamental task of driving (safety/navigation) from the style of driving (preference), the authors avoid the catastrophic forgetting typical in multi-task learning.
Limitations: Currently, this is validated in CARLA (Simulation). The real challenge lies in Sim-to-Real transfer—how do we capture the "feel" of a real steering wheel's haptic feedback and translate that into a VLA embedding?
DMW proves that the future of autonomous driving isn't just about reaching the destination; it's about how you get there. By treating language as a first-class citizen in the control loop, we move closer to vehicles that truly understand their passengers.