This paper introduces dTRPO (Trajectory Reduction Policy Optimization), a novel offline alignment framework for Diffusion Large Language Models (dLLMs). It achieves state-of-the-art performance, including gains of 9.6% on STEM and 4.3% on coding, by drastically reducing the computational overhead of trajectory probability estimation.
TL;DR
Diffusion Large Language Models (dLLMs) offer exciting benefits like parallel decoding and bidirectional context, but aligning them with human preferences has historically been a computational nightmare. dTRPO changes the game by introducing Trajectory Reduction, a method that cuts down the cost of policy optimization to a single forward pass—making dLLM alignment as fast and scalable as standard DPO for autoregressive models.
The "Probability Bottleneck" in Diffusion
In the world of Autoregressive Models (ARMs), calculating the probability of a sequence is easy: you just multiply the probability of each token given the previous ones. In a single forward pass, you have everything.
dLLMs are different. They generate text by starting with a sequence of [MASK] tokens and iteratively "denoising" them over steps. To find the true probability of a generated trajectory, you'd technically need to run the model for every single intermediate step. For a long sequence, this means hundreds of forward passes for just one training example. This lack of factorization makes standard alignment techniques like Direct Preference Optimization (DPO) incredibly slow or mathematically "hacky."
The Innovation: Trajectory Reduction
The researchers at Meta and KAUST realized that we don't need the absolute probability; we only need the ratio between the current policy () and a reference policy (). They introduced two breakthrough theorems:
- State Reduction: They proved that the log-probability of the whole trajectory can be estimated unbiasedly by sampling just one random time step within each block of tokens.
- Ratio Reduction: The complex coefficients related to the diffusion "noise schedule" () are identical for both the learner and the reference model. When you take the ratio, these terms cancel out, leaving only the simple categorical probabilities of the newly unmasked tokens.
Architecture & Mechanism
To implement this efficiently, dTRPO uses Block Attention. During training, the model uses a custom mask that allows it to simulate multiple stages of the diffusion process simultaneously in a single forward pass.
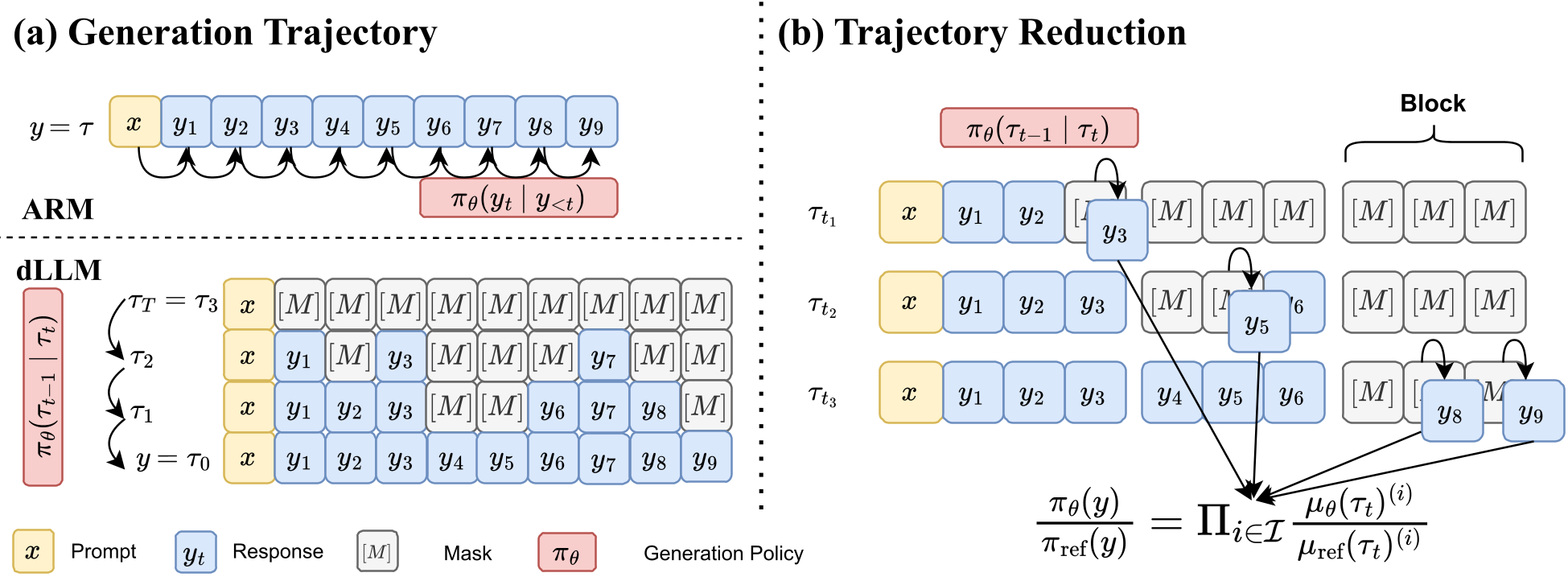 Figure: dTRPO samples specific steps and uses block attention to estimate ratios using only newly unmasked tokens.
Figure: dTRPO samples specific steps and uses block attention to estimate ratios using only newly unmasked tokens.
Experimental Performance
The results show that dTRPO doesn't just save time; it creates smarter models. By using an "inference-aligned" scheduler (training the model the same way it will be used to decode), the authors saw massive jumps in reasoning capability.
- STEM Reasoning: +9.6% gain on GPQA.
- Math: Significant improvements on GSM8K and MATH datasets, reaching near-ARM performance.
- Efficiency: Training cost was reduced by orders of magnitude compared to online RL methods (like PPO), requiring only 4 forward passes per pair of samples.
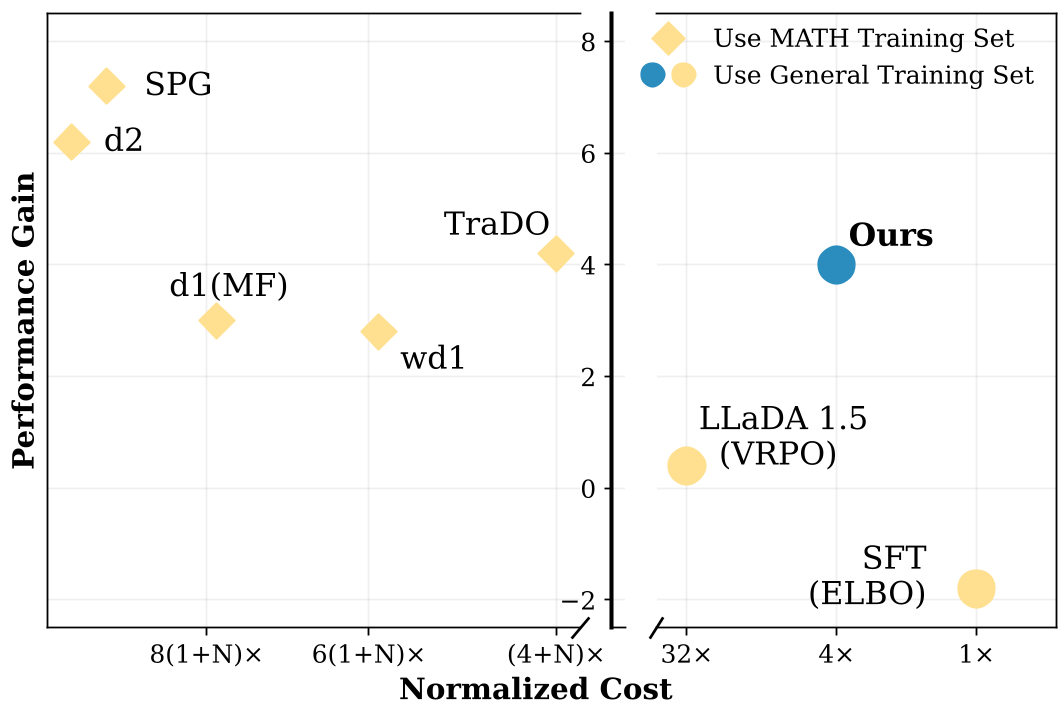 Figure: Comparison of performance vs. training cost. dTRPO achieves SOTA results with a fraction of the compute.
Figure: Comparison of performance vs. training cost. dTRPO achieves SOTA results with a fraction of the compute.
Deep Insight: Why it Works
The beauty of dTRPO lies in its Inference Alignment. Most heuristic dLLM trainers try to optimize all masked tokens at once. However, during actual inference, the model only unmasks a few tokens at a time. By focusing the loss only on the "newly unmasked" tokens at a given step, dTRPO forces the model to optimize exactly what matters for the generation process it will use in the real world.
Conclusion & Future Look
dTRPO provides the missing mathematical link to make dLLMs competitive with their autoregressive siblings in the post-training phase. By removing the "diffusion tax" on training compute, it opens the door for dLLMs to be scaled using massive teacher-generated preference datasets.
Limitations: The method currently relies on a block-wise structure or specific diffusion schedulers. Future work could explore how to apply these reductions to completely continuous time-steps or non-absorbing diffusion kernels.
Takeaway for Practitioners: If you are working on non-autoregressive generation, dTRPO is the new gold standard for alignment. It proves that theoretical rigor in the MDP formulation can lead to massive practical engineering wins.