本文提出了 E3-TIR(Enhanced Experience Exploitation),一种针对工具集成推理(TIR)任务的强化学习预热范式。该方法通过在专家轨迹上进行分支采样并引入混合策略优化(Mix Policy Optimization),在 3B/7B 规模模型上实现了超越 SOTA 的性能。
TL;DR
工具集成推理(Tool-Integrated Reasoning, TIR)正成为 LLM Agent 走向实用的核心。然而,现有的 RL 训练路径要么像无头苍蝇(Zero-RL 效率低),要么极易陷入“过度拟合”(SFT+RL 导致低熵崩溃)。哈工大与华为等提出的 E3-TIR 框架,通过在专家路径上设置“锚点”进行分支探索,并配以梯度阻断和动态过滤机制,用极小的数据代价换取了极大的性能增幅。
1. 痛点:为什么 Agent 的 RL 训练这么难?
在一项深度实验中,作者揭示了当前 TIR 训练的两个致命缺陷:
- Zero-RL 的“React 模式”退化:由于没有任何先验引导,模型倾向于通过频繁、冗余的工具调用来换取奖励,从而丧失了 Chain-of-Thought 的推理能力。
- SFT+RL 的“由于僵化而退化”:经过大量 SFT 的模型在进入 RL 阶段后,策略熵迅速下降(Low-entropy collapse),导致模型虽然开始很强,但很快就会因失去探索能力而陷入局部最优。
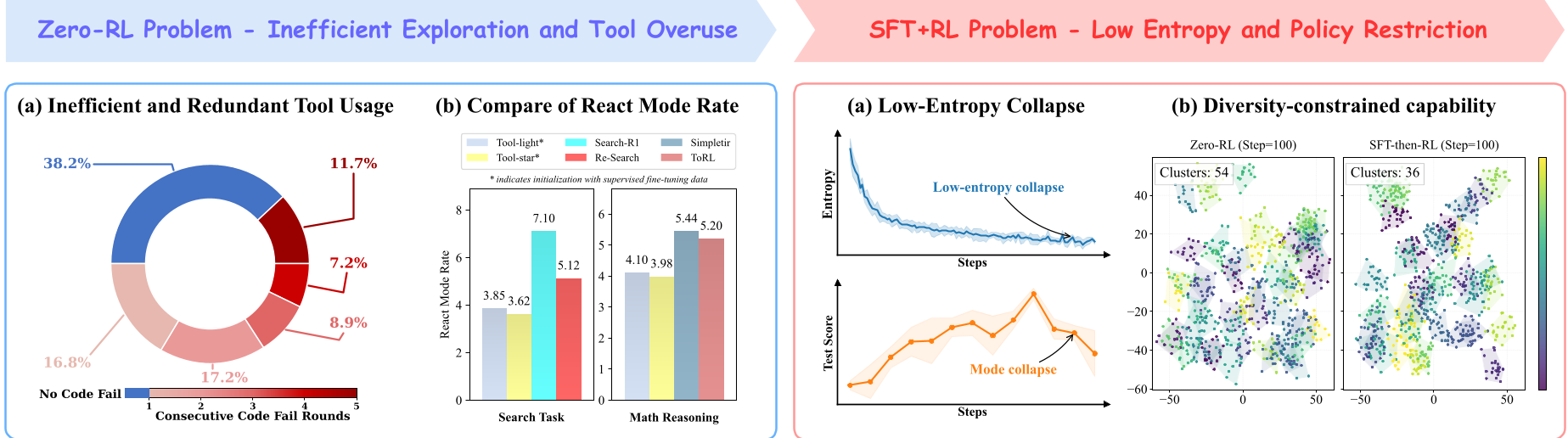 图注:左侧展示了 Zero-RL 的推理退化;右侧展示了 SFT+RL 的多样性崩溃。
图注:左侧展示了 Zero-RL 的推理退化;右侧展示了 SFT+RL 的多样性崩溃。
2. 核心机理:E3-TIR 的三阶进化论
E3-TIR 的直觉非常物理:“站在巨人的肩膀上跳跃,而不是模仿巨人的步伐。”
1) 基于专家锚点的分支采样 (Prefix-Guided Branching)
与其让模型从零开始乱跳,不如给它几条正确的半成品路径。
- 锚点选择:计算专家轨迹中每一步的策略熵 ,选择不确定性最高的步骤作为“锚化”前缀。
- 分支探索:从这些高价值前缀出发,强制模型进行多路径扩展并行采样(Diverse Branching)。这就像是给迷宫中的探险者提供了关键的中继站。
2) 优势感知梯度阻断 (Advantage-Aware Gradient Detaching, AAGD)
这是本文解决数学训练冲突的神来之笔。在分支采样中,多条不同结局的路径会共享同一个“专家前缀”。
- 问题:如果某个分支失败了(),负向梯度会惩罚本是正确的“专家前缀”。
- 方案:AAGD 机制规定:只有当分支成功()时,梯度才回传给共享前缀;失败分支仅优化其后缀部分。这保护了专家知识不被坏的试探所污染。
3) 动态经验过滤
当模型的自我探索结果(Self-Exploration)在最大奖励上超过专家轨迹时,系统会自动摒弃专家经验,完全转由模型自主进化。这种“阶段性引导”避免了模型在后期受到陈旧经验的束缚。
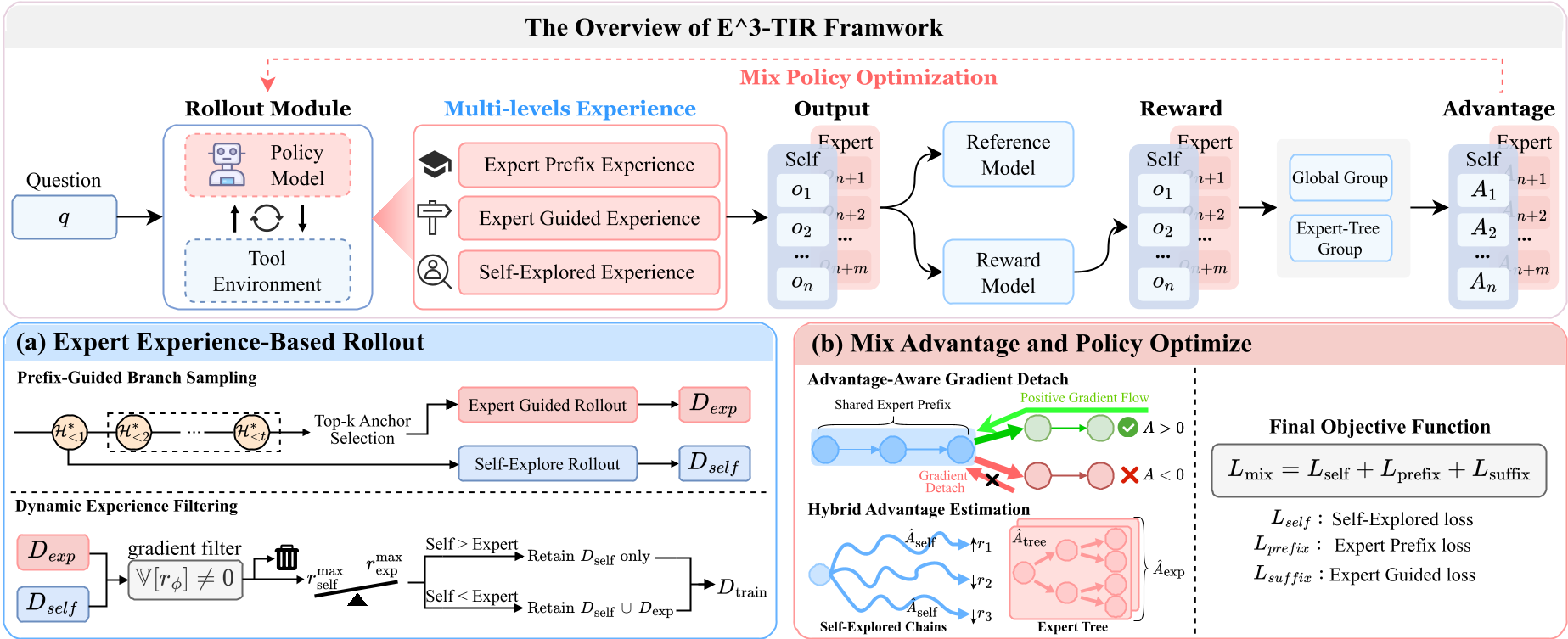 图注:分支探索与 AAGD 机制的协同运作流程。
图注:分支探索与 AAGD 机制的协同运作流程。
3. 实验战绩:用更少的火药,打得更准
E3-TIR 在 Qwen2.5 (3B/7B) 和 Llama3.1 (8B) 上进行了验证,数据非常惊人:
- 性能增益:相比传统 SFT-then-RL,在 AIME25 等极端数学任务上实现了 6% 以上 的提升。
- 数据效率:仅使用了不到 10% 的合成数据量。
- 工具调用质量:工具调用次数从 2.52 次下降到 1.97 次,失败率(Fail Rate)几乎减半,展示了极其干练的“思考型”调用风格。
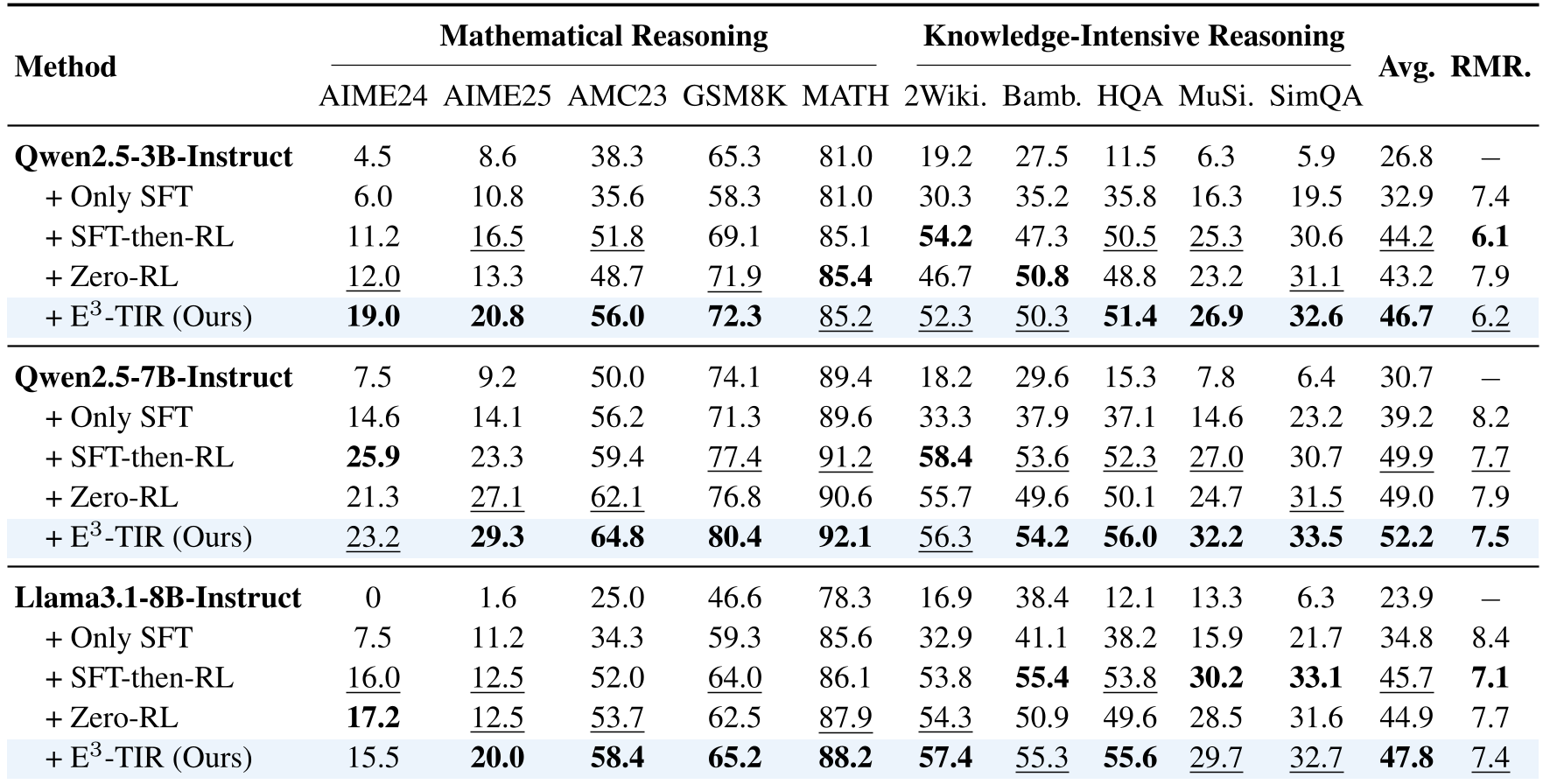 表注:在数学(AIME, GSM8K)和知识搜索(HotpotQA)等基准测试中的全面超越。
表注:在数学(AIME, GSM8K)和知识搜索(HotpotQA)等基准测试中的全面超越。
4. 深度洞察:为什么这种“混合”有效?
作者通过消融实验给出了几个硬核结论:
- 梯度阻断是个宝:如果没有 AAGD 机制,模型性能会崩溃(见表 4),说明在多步推理中,由于路径共享导致的优化方向冲突是真实存在的猛兽。
- 混合优势(Hybrid Advantage)的价值:同时考虑“全局池化优势”和“专家树内相对优势”,能帮助模型捕捉到专家的极细微解题思路波动。
- “U型” ROI 曲线:Warm-up 步数并非越多越好。适度的“预热”后迅速放手交由模型自主探索,才是 ROI 最高的路径。
5. 总结与展望
E3-TIR 不仅仅是一个算法提升,它代表了 LLM Agent 训练的一种新哲学:引导探索(Guided Exploration)应当是动态且非对称的。
尽管它目前对专家路径的初始质量仍有一定依赖,但在当前高质量合成数据昂贵的背景下,这种通过“分支采样+利己优化”的策略,为低成本构建行业最强 Agent 提供了一条极其明晰的特快通道。
未来的 TIR 可能不再需要海量的全量 SFT,只需要少量的“黄金前缀”,就能在 RL 的熔炉中锻造出顶尖的 Agent。
关键词:TIR, Reinforcement Learning, E3-TIR, Advantage-Aware Gradient Detaching, LLM Agent.