The paper introduces E-3DPSM, a real-time event-driven continuous pose state machine for egocentric 3D human pose estimation using a monocular head-mounted event camera. It leverages State Space Models (S5) and a learnable Kalman-style fusion module to achieve state-of-the-art accuracy, improving MPJPE by up to 19% while drastically increasing temporal stability by 2.7x over existing methods like EventEgo3D++.
TL;DR
Egocentric 3D human pose estimation from Head-Mounted Devices (HMDs) is notoriously difficult due to extreme self-occlusions and motion blur. E-3DPSM breaks away from traditional frame-based processing by modeling human motion as a continuous state evolution. By fusing event-driven "delta" updates with direct 3D predictions through a learnable Kalman filter, it achieves up to 19% better accuracy and 2.7x higher temporal stability than previous SOTA, running at a lightning-fast 80 Hz.
The Core Conflict: Why Events?
Standard RGB cameras fail in AR/VR contexts when the user moves quickly (motion blur) or enters low-light environments. Event cameras, which only record per-pixel brightness changes, offer microsecond resolution and high dynamic range. However, previous attempts (like EventEgo3D) treated events like "sparse images," missing the physics of the stream.
The authors identify three fatal flaws in prior work:
- Quantization Errors: Reliance on 2D heatmaps.
- Short-term Memory: Using only a single previous frame for context.
- Information Mismatch: Predicting absolute poses from a sensor that inherently captures change.
Methodology: The State Machine Philosophy
E-3DPSM introduces a three-stage pipeline that aligns the mathematical properties of the sensor with the physics of human motion.
1. Spatiotemporal Pose Encoder (SPEM)
Instead of simple CNNs, SPEM uses State Space Models (SSM)—specifically the S5 variant—to maintain a latent state . This allows the model to "remember" body parts even when they are occluded for long durations. Deformable Attention is also utilized to handle the extreme distortions caused by fisheye lenses used in egocentric setups.
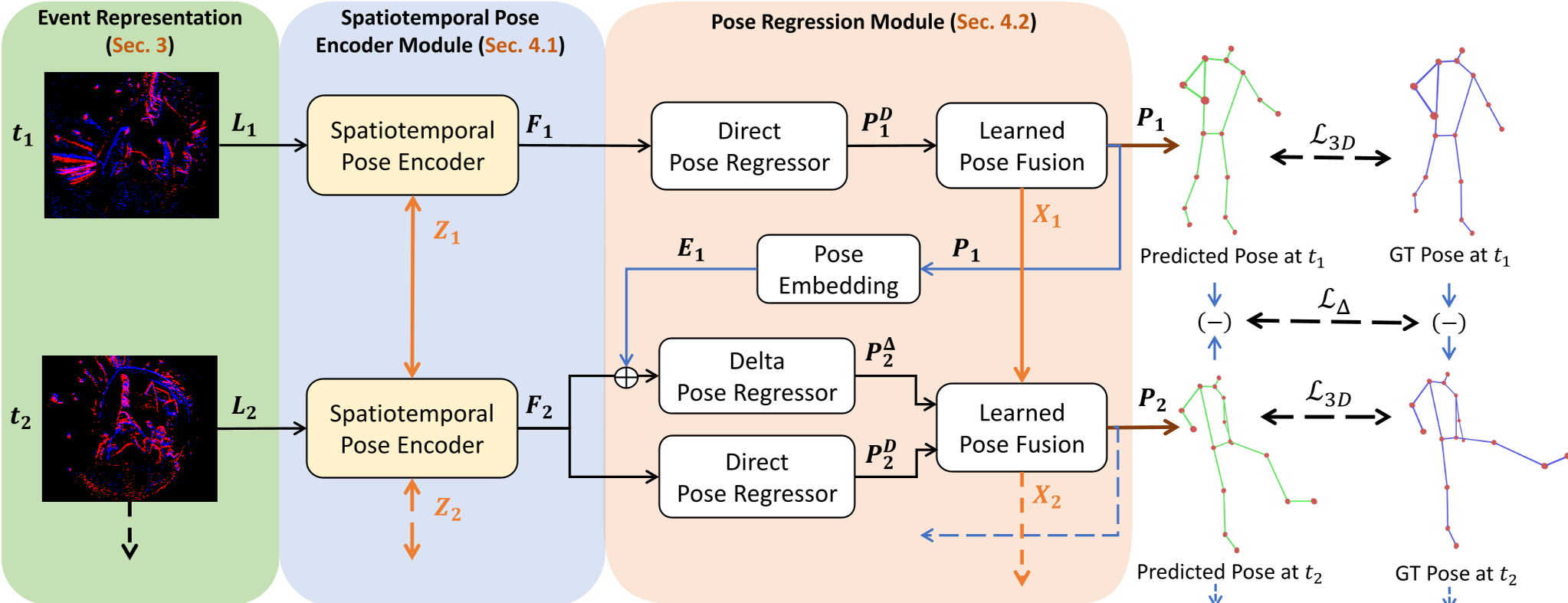 Figure 1: The E-3DPSM pipeline converts events into Locally Normalized Event Surfaces (LNES), encodes them via SSMs, and regresses poses.
Figure 1: The E-3DPSM pipeline converts events into Locally Normalized Event Surfaces (LNES), encodes them via SSMs, and regresses poses.
2. Learnable Neural Kalman Fusion
This is the "secret sauce." The model predicts two things:
- Direct Pose (): A global anchor of where the body is.
- Delta Pose (): How much each joint moved since the last event.
A differentiable Kalman-style filter then fuses these. The "Delta" provides smooth, jitter-free motion, while the "Direct" pose prevents the integration drift that plagues pure dead-reckoning systems.
Experiments: Crushing the Jitter
The results on the EE3D-R (Real) and EE3D-W (Wild) benchmarks are striking. Most notably, the "eSmooth" metric (which measures temporal jitter) plummeted.
| Method | MPJPE ↓ | eSmooth ↓ | | :--- | :--- | :--- | | EventEgo3D++ (Previous SOTA) | 103.28 | 22.93 | | E-3DPSM (Ours) | 84.45 | 8.40 |
The improvements are most visible in extreme poses. While previous models "lose" the legs during crawling or crouching, E-3DPSM maintains anatomical plausibility.
 Figure 2: Qualitative comparison showing E-3DPSM's stability (Red) vs Ground Truth (Green) in complex "In-the-Wild" scenarios.
Figure 2: Qualitative comparison showing E-3DPSM's stability (Red) vs Ground Truth (Green) in complex "In-the-Wild" scenarios.
Critical Insight: The "Delta" Advantage
The paper proves that a sensor that measures change is naturally suited for predicting velocity (delta pose). By supervising the model with a specific Delta Pose Loss (), the network learns to interpret the "flash" of events as a direct measurement of joint displacement. This reduces the problem complexity from "Where is the hand in 3D space?" to "How much did the hand move given these 5,000 events?"
Conclusion & Future Impact
E-3DPSM represents a shift toward event-native architectures. By avoiding the intermediate 2D heatmap proxy and embracing continuous-time state modeling, it provides a blueprint for future AR/VR interfaces. However, the authors note sensitivity to extremely dense environments where background noise might overwhelm the human signal—a remaining frontier for event-based vision.
Key Values:
- Real-time Efficiency: 80Hz (A6000) / 52Hz (Mobile 3050Ti).
- Zero Synthetic Pre-training: Unlike predecessors, it trains directly on real data.
- Robustness: Significant gains in distal joints (wrists/ankles) under occlusion.