ECHO is an efficient discrete diffusion Vision-Language Model (dVLM) designed for automated Chest X-ray (CXR) report generation. It utilizes a "One-step Block Diffusion" mechanism and a Direct Conditional Distillation (DCD) framework to achieve state-of-the-art clinical accuracy while delivering an 8× inference speedup compared to traditional autoregressive models.
TL;DR
ECHO is a breakthrough in medical Vision-Language Models (VLMs) that solves the long-standing trade-off between inference speed and clinical accuracy. By introducing a novel distillation framework (DCD) and an asymmetric training strategy (RAD), it achieves a staggering 8× speedup over autoregressive models like LLaVA-Med while actually improving diagnostic precision (RaTE +64.33%).
Background: The Latency Bottleneck in Radiology
Automated Chest X-ray (CXR) reporting is vital for reducing radiologist burnout. However, current SOTA models are mostly Autoregressive (AR)—decoding one word at a time. In a high-volume hospital, this sequential process is a massive bottleneck. Diffusion-based VLMs emerged to generate words in parallel, but they still required 10-50 "denoising steps" to make sense. If you try to do it in one step, the model suffers from mean-field bias, essentially "forgetting" how words relate to each other, resulting in gibberish.
Methodology: The Architecture of Efficiency
ECHO's success rests on three technical pillars designed to kill latency without losing the "medical mind" of the model.
1. Direct Conditional Distillation (DCD)
DCD is the "secret sauce" that enables one-step-per-block generation. Instead of the student model learning from a messy independent token distribution, DCD uses a teacher model's multi-step trajectory to create a "joint" supervision signal. This ensures that even when the model predicts 8 tokens at once, it understands their internal grammatical and clinical dependencies.
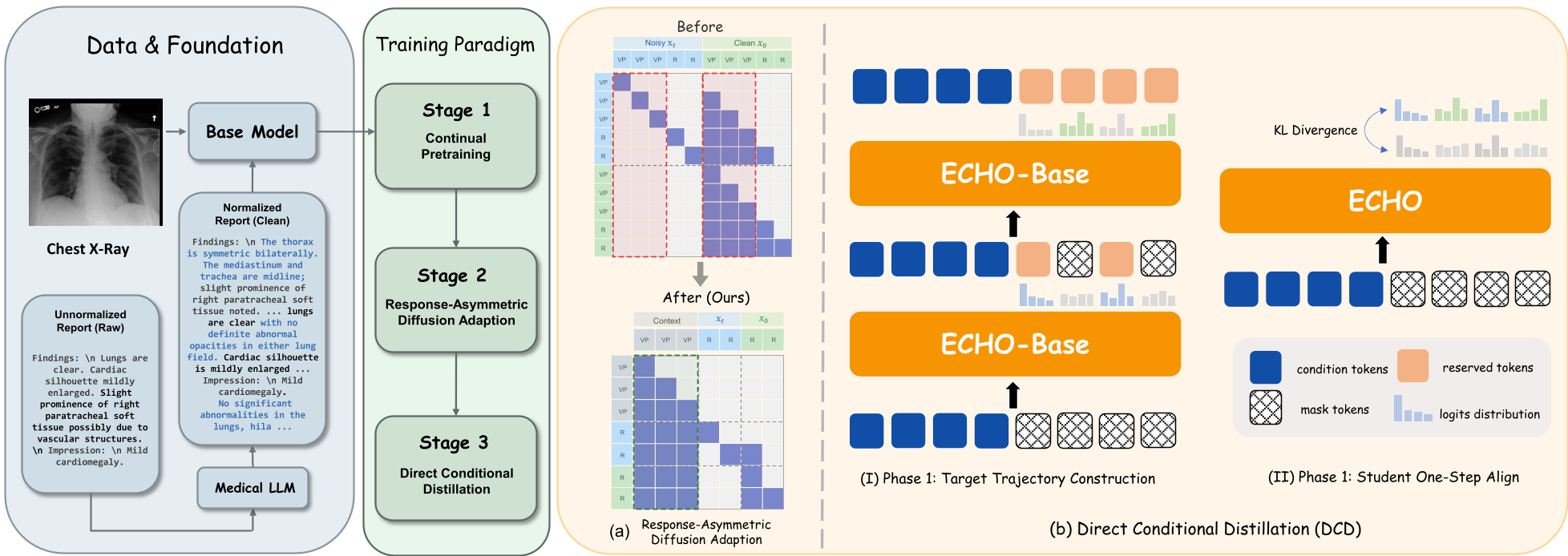
2. Response-Asymmetric Diffusion (RAD)
Standard AR-to-Diffusion conversion is expensive because it duplicates long visual sequences. RAD solves this by being "asymmetric"—it only duplicates the text response portion. This insight reduced training FLOPs by 72.3%, allowing the model to adapt from an AR base (like Lingshu-7B) to a Diffusion model with minimal data.
3. Fused Block KV Cache
In typical block-decoding, you need one pass to generate text and a second pass to update the memory (KV cache). ECHO's inference engine fuses these, halving the number of forward passes required and further accelerating practical throughput.
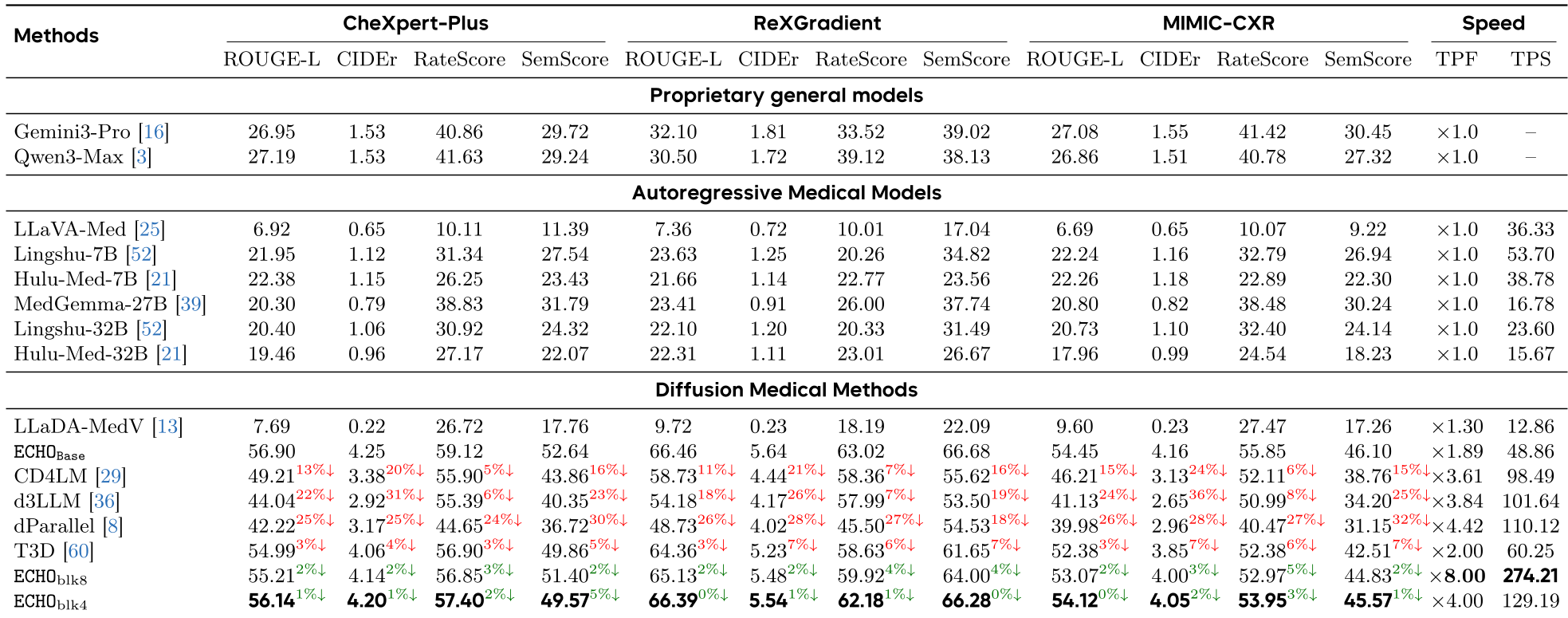
Experiments: Performance at Warp Speed
The results in the table below show that ECHO doesn't just "keep up"—it dominates.
| Method | Speedup | RaTE (Clinical) | SemScore | | :--- | :--- | :--- | :--- | | LLaVA-Med (AR) | 1.0x | 10.11 | 11.39 | | ECHO (Ours) | 8.0x | 56.85 | 51.40 | | T3D (Distilled) | 2.0x | 56.90 | 49.86 |
Qualitative Evidence
As seen in the visual results, when forced to "one-step" without DCD, models produce "token disorder" (e.g., ECHO-Base_onestep). However, the distilled ECHO variants maintain the structural integrity of the report while correctly identifying pathologies like "Pleural Effusion" and "Pneumothorax."
Deep Insight: Why Data Normalization Matters
The authors noted a critical "Reporting by Exception" bias in medical data: radiologists often omit normal findings. ECHO practitioners addressed this by normalizing reports—explicitly stating both positive and negative findings. This created a "dense" supervision signal that prevented the model from hallucinating or omitting critical abnormalities during the high-speed one-step sampling.
Conclusion & Outlook
ECHO represents the "Upper Bound" of decoding efficiency. By effectively distilling the complex logic of multi-step diffusion into a single forward pass, it opens the door for real-time AI diagnostic assistants that can keep pace with the fastest clinical workflows. Future work may see this "One-step Block Diffusion" applied to even more complex modalities like 3D CT scans or real-time surgical video analysis.