The paper introduces an online Reinforcement Learning from Human Feedback (RLHF) framework that combines incremental model updates with uncertainty-guided exploration. By utilizing Epistemic Neural Networks (ENN) and Information-Directed Sampling (IDS), the method achieves parity with offline RLHF using 10x less data (20K vs 200K labels) and is projected to reach a 1,000x efficiency gain at scale.
TL;DR
Data efficiency is the final frontier for aligning Superintelligence. Google DeepMind researchers have unveiled a breakthrough online RLHF algorithm that achieves a 10x gain in data efficiency today (matching 200K labels with just 20K) and is projected to hits a 1,000x gain at scale. By treating alignment as an active exploration problem rather than a static supervised task, this work demonstrates how we can do much more with significantly less human feedback.
Problem & Motivation: The "Static" Alignment Trap
Most current RLHF pipelines are offline. We collect a massive batch of human preferences, train a Reward Model (RM), and then optimize the Language Model (LM). This is fundamentally inefficient:
- Limited Coverage: The human data is collected for a model that "no longer exists" once training starts.
- Information Waste: Randomly sampling response pairs often results in "easy" choices (e.g., one response is clearly gibberish), which teaches the reward model almost nothing.
- The "Tanking" Phenomenon: In online settings where the model updates continuously, performance often collapses (tanks) due to optimization instabilities or distribution shifts.
The authors' insight is profound: To build better models, we shouldn't just collect more data; we must collect the right data by explicitly modeling what the reward model is uncertain about.
Methodology: The Three Pillars of Efficiency
The researchers introduced a system that incrementally updates both the RM and LM as human choices arrive. Three specific technical levers make this possible:
1. The Epistemic Neural Network (ENN)
Instead of a single scalar head, the Reward Model uses an ENN architecture. It consists of a point-estimate MLP supplemented by an ensemble of 100 "prior" and "differential" networks. This allows the model to output a distribution of rewards rather than a single mean value.
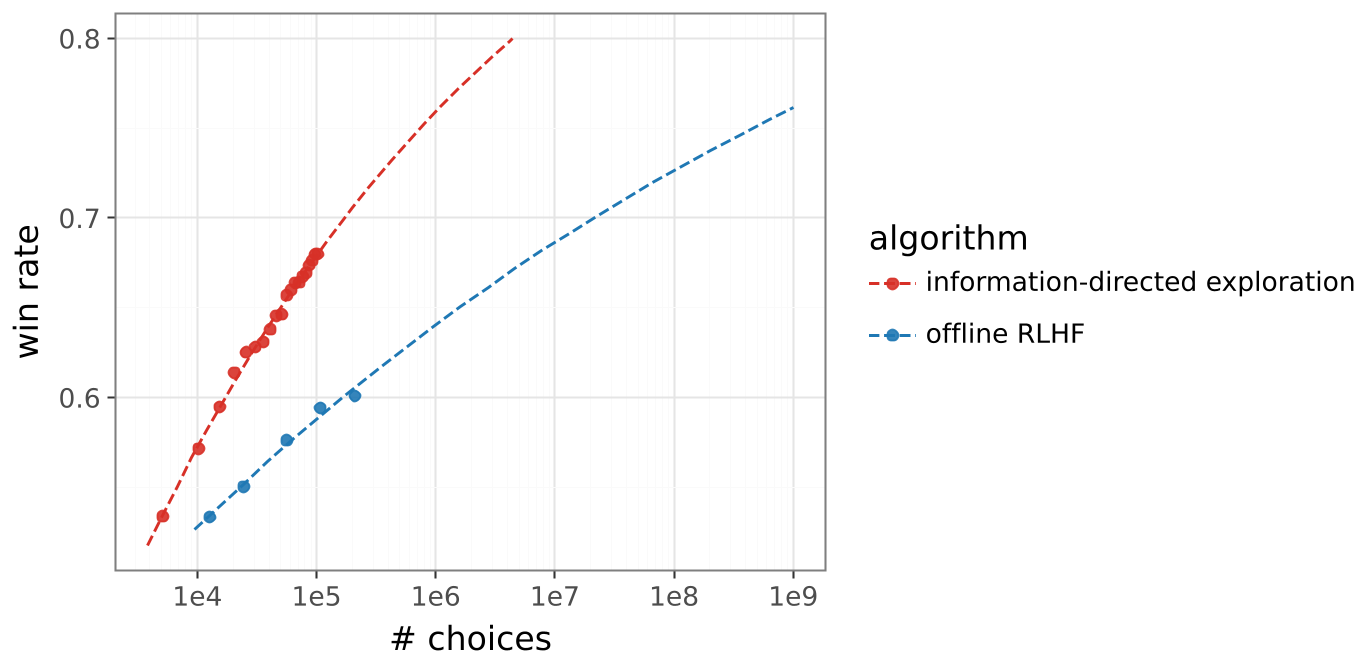 Figure 1: Efficient exploration shifts the scaling law of win rates relative to human feedback volume.
Figure 1: Efficient exploration shifts the scaling law of win rates relative to human feedback volume.
2. Information-Directed Sampling (IDS)
Using the ENN, the system calculates the variance of the choice probability across its ensemble.
- Infomin pairs: Responses that are identical in meaning (low variance, low information).
- Infomax pairs: Responses where the reward model is highly uncertain about which one is better (high variance, high information). By sending only the "Infomax" pairs to human raters, the model resolves its own ambiguities at a blistering pace.
3. The Affirmative Nudge ()
To prevent the "tanking" behavior where online RLHF performance drops after a certain number of steps, the authors modified the Policy Gradient update:
abla \ln \pi(Y|X) ...$$ This small scalar $\epsilon$ ensures the model receives a consistent "nudge" toward positive reinforcement, stabilizing the learning trajectory over hundreds of batches. 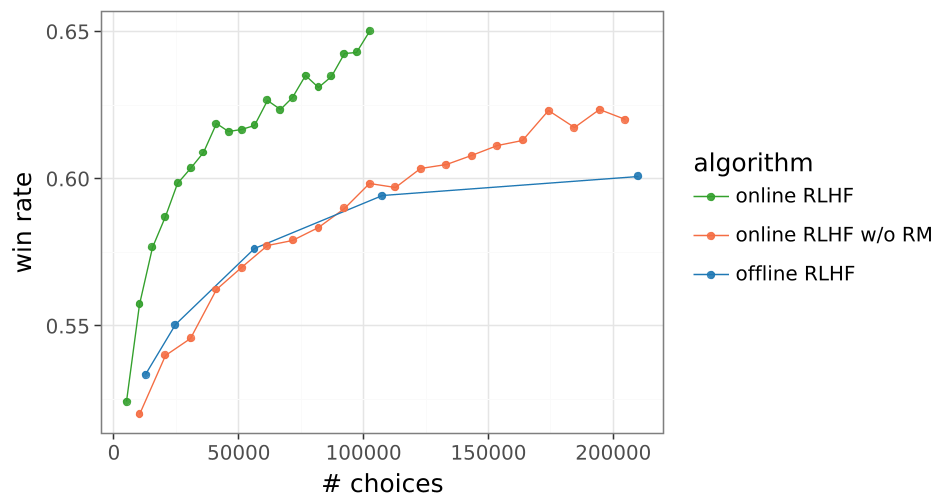 *Figure 2: The "Affirmative Nudge" (right) prevents the performance collapse typically seen in online RLHF.* ## Experiments & SOTA Results The team tested their approach on the **Gemma 9B** model across 200,000 diverse prompts (coding, math, creative writing). - **10x Leap**: The Information-Directed algorithm surpassed the 200K-label offline baseline while using only **18.4K labels**. - **Higher Reasoning Quality**: In math word problems, the efficiently explored model produced concise, correct logic, whereas the offline model often drifted into convoluted, incorrect derivations. - **Scaling Projection**: By plotting the results on a log-scale, the researchers identified a new scaling law. They project that with 1M labels, this method will match an offline model trained on **1 Billion labels**. 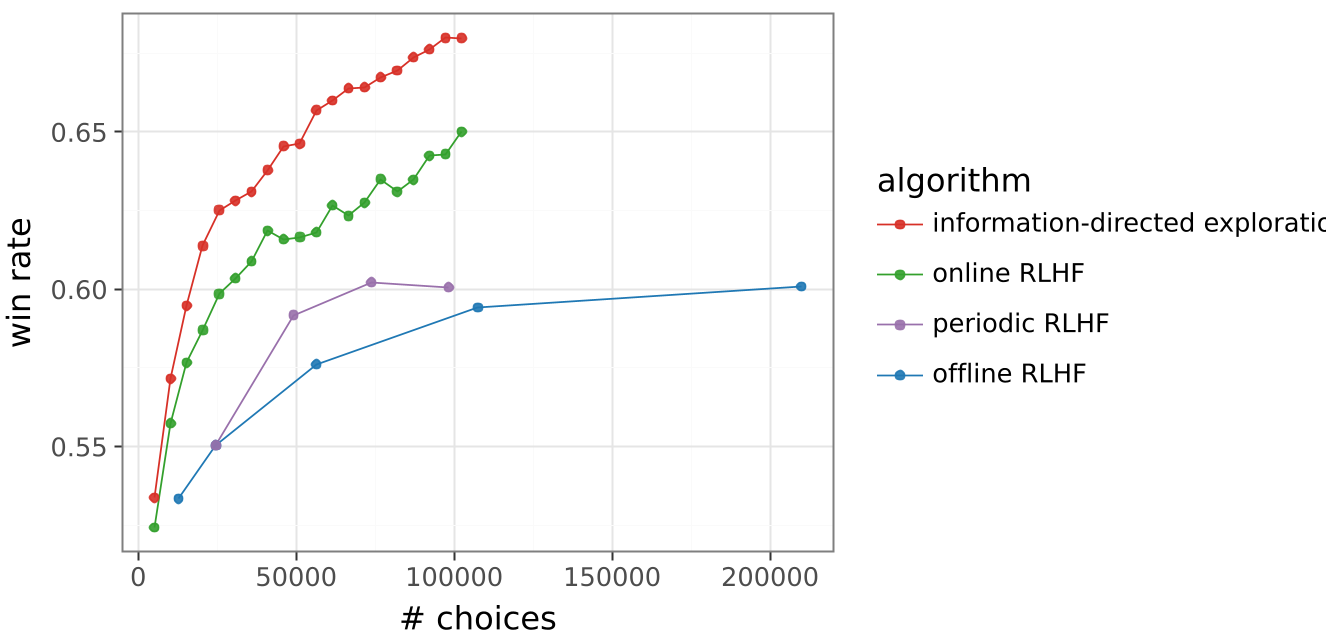 *Figure 3: Win rate performance as a function of human feedback. Note the widening gap between Information-Directed Exploration and other methods.* ## Critical Analysis & Conclusion The takeaway is clear: **Exploration is not optional; it is a multiplier.** By modeling epistemic uncertainty, we can bypass the "brute force" data collection that Currently dominates the industry. **Limitations**: - **Computational Overhead**: Training an ensemble of 100 MLP heads and running inference on multiple responses per prompt increases compute cost per training step, though this is likely offset by the massive reduction in human labeling costs. - **Simulation Bias**: The study uses Gemini 1.5 Pro as a "Human Simulator." While standard in the field, real-world human noise might impact the variance-based sampling efficiency. **Future Outlook**: This framework sets the stage for **AI-Assisted Feedback**, where models don't just ask "which is better?" but actively frame debates or generate edge cases to "stress test" their own alignment. --- **Senior Editor's Note**: This paper marks a pivot from *scaling compute* to *scaling intelligence in data selection*. As human feedback becomes the scarcest resource in AI, Information-Directed Exploration will likely become a standard component of LLM post-training.