This paper introduces Flow-Anchored Noise-conditioned Q-Learning (FAN), a highly efficient offline reinforcement learning algorithm. It combines expressive flow policies with distributional critics while achieving state-of-the-art results on D4RL and OGBench benchmarks with significantly reduced computational overhead.
TL;DR
Expressive models (like Flow Matching) and Distributional Critics are the "gold standard" for high-performance Offline RL, but they are notoriously slow. Flow-Anchored Noise-conditioned Q-Learning (FAN) changes the game by achieving SOTA performance while being 5-14x faster than existing distributional methods. It achieves this through two breakthroughs: Flow Anchoring (no more ODE solving for regularization) and Noise-conditioned Critics (captures the return distribution with a single noise sample).
Background: The Cost of Expressivity
In Offline RL, we don't have the luxury of environment interaction. We must learn from a fixed dataset, which often contains multi-modal behavior (multiple ways to solve a task). This has led to the rise of:
- Flow Matching/Diffusion Policies: To model complex action distributions.
- Distributional Critics: To understand the uncertainty and range of future returns.
However, these are "compute hogs." A Flow policy usually requires 10+ steps of an ODE solver to produce an action, and a distributional critic needs to calculate dozens of quantiles. This makes training slow and real-time inference nearly impossible on limited hardware.
The Problem: Why is Everyone So Slow?
The bottleneck is iterative sampling. Previous methods like Value Flows or CODAC require multiple samples to either regularize the policy or estimate the value. The central question of FAN is: Can we keep the mathematical expressivity of these models while using only a single sample?
Methodology: The FAN Architecture
FAN introduces a "lean but powerful" architecture that targets both the Actor and the Critic.
1. Flow Anchoring (The Actor Efficiency)
Instead of solving the full ODE to find where an action "lands" in the distribution, FAN regularizes the one-step policy by comparing its trajectory velocity directly against the behavior flow's velocity field .
This is called Flow Anchoring. It effectively "anchors" the learned policy to the dataset's flow without ever needing to run the flow to completion.
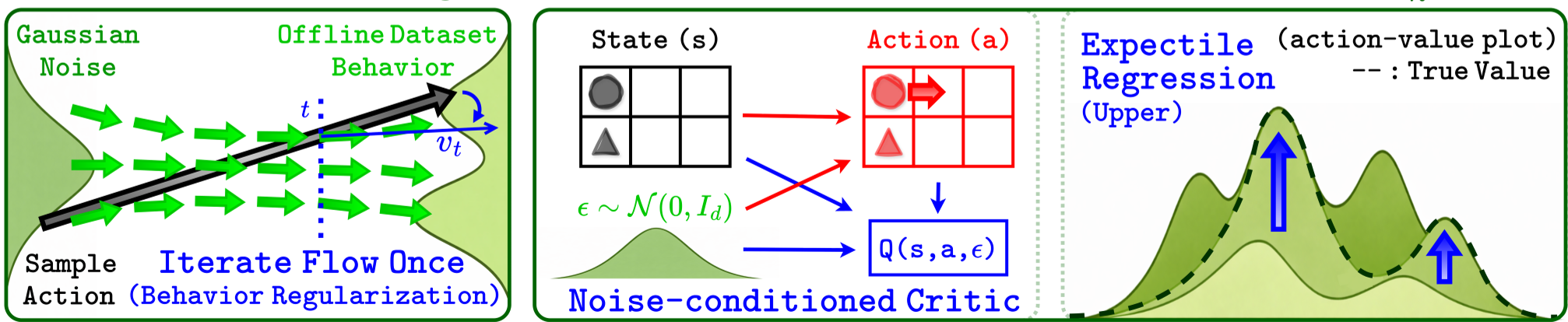
2. Noise-conditioned Critic & (The Critic Efficiency)
Standard distributional RL models quantiles (). FAN models the value as , where is simple Gaussian noise.
To train this efficiently, the authors propose a new operator, :
By using Upper Expectile Regression (with ), FAN can estimate the "best possible" return distribution (the essential supremum) without needing a large ensemble or dozens of quantile samples.
Experiments & Results: SOTA Performance at Warp Speed
The most striking result of FAN is the Runtime vs. Success plot. FAN sits at the top-left corner: the highest success rate with the lowest training time.
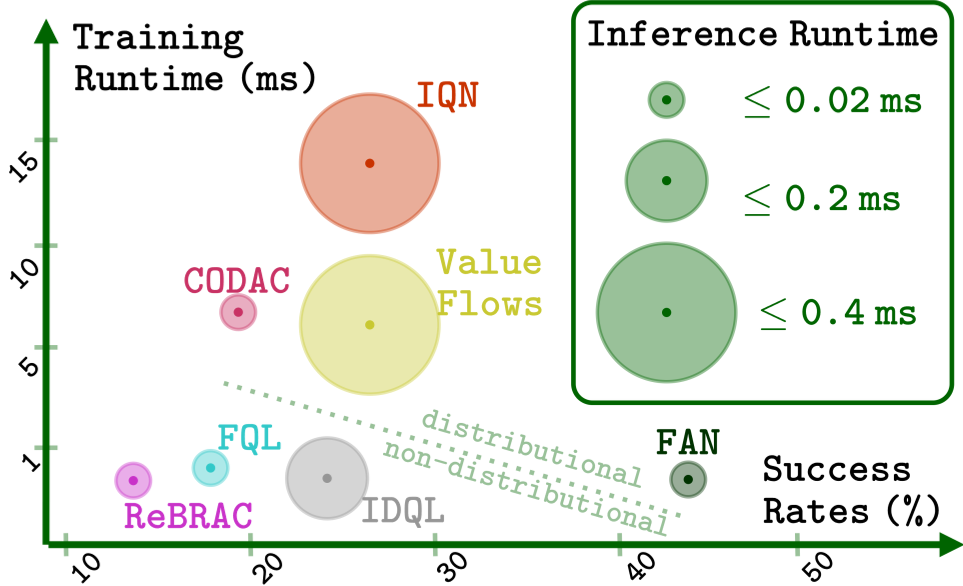
Key Findings:
- Robotic Mastery: On OGBench, FAN achieved 100% success on Puzzle-3x3, whereas most non-distributional methods hovered around 20-30%.
- Wall-clock Speed: Training is 5-14x faster than other distributional baselines. Inference (action sampling) is nearly instantaneous because it's a one-step calculation.
- Offline-to-Online: FAN excels at being "fine-tuned" in a real environment after its offline pre-training phase, showing its robustness.
Deep Insight: Why Does It Work?
The "physics intuition" here is that we don't need to know the entire path to know the direction of the flow. By aligning gradients and velocities (Flow Anchoring) and using noise as a latent variable for returns (Noise-conditioned Critic), FAN bypasses the "sampling tax" that has plagued generative RL for the last few years.
Conclusion & Limitations
The Takeaway: FAN proves that you don't need expensive iterative sampling to benefit from expressive generative models. It makes high-end Offline RL practical for real-world robotics.
Limitations: While FAN is fast, it still relies on a shared noise input between the actor and critic, which might limit its expressivity in extremely high-dimensional or discontinuous reward landscapes. Future work could explore more complex noise structures or apply Flow Anchoring to multi-agent settings.
For more details, check out the official implementation.