The paper introduces ESTF-SSM, an end-to-end Temporal Action Detection (TAD) framework that integrates an Efficient Spatial-Temporal Focal (ESTF) Adapter into a frozen video backbone. By leveraging a novel Temporal Boundary-aware State Space Model (TB-SSM), the method achieves SOTA performance on THUMOS14 (75.3% Avg. mAP) and ActivityNet-1.3 with linear computational complexity.
TL;DR
Temporal Action Detection (TAD) scales poorly with video length due to the quadratic complexity of Transformers and the limited reach of CNNs. ESTF-SSM tackles this by introducing a "Temporal Boundary-aware SSM" (TB-SSM) within a lightweight adapter. By modeling the forward and backward temporal flows with independent state transitions, it achieves superior boundary precision on THUMOS14 and ActivityNet while maintaining linear efficiency.
The Scaling Wall: Why Attention Isn't All You Need for Video
In the realm of long-form video understanding, the industry faces a dilemma:
- CNNs are efficient but "blind" to long-range dependencies, often missing the broader context of an action.
- Transformers provide global context but suffer from Quadratic Complexity , making them memory-hungry for high-resolution, untrimmed videos.
- Existing SSMs (like Mamba) offer efficiency but struggle with Oversmoothing. In TAD, the exact "flicker" of a movement starting or ending is vital; standard SSMs tend to blend these fine-grained details into the global feature representation.
Methodology: Decoupling and Specializing
The authors propose the Efficient Spatial-Temporal Focal (ESTF) Adapter. Instead of full-parameter fine-tuning, they insert these adapters into a frozen backbone (like VideoMAEv2).
1. Spatial-Temporal Decoupling
The adapter splits the feature flow into two branches:
- Spatial Branch: Uses Depthwise Convolutions to maintain local structural cues.
- Temporal Branch: Uses the new TB-SSM to reason across time steps.
This decoupling ensures that the model doesn't waste computational cycles trying to attend to every pixel-timestamp pair simultaneously.
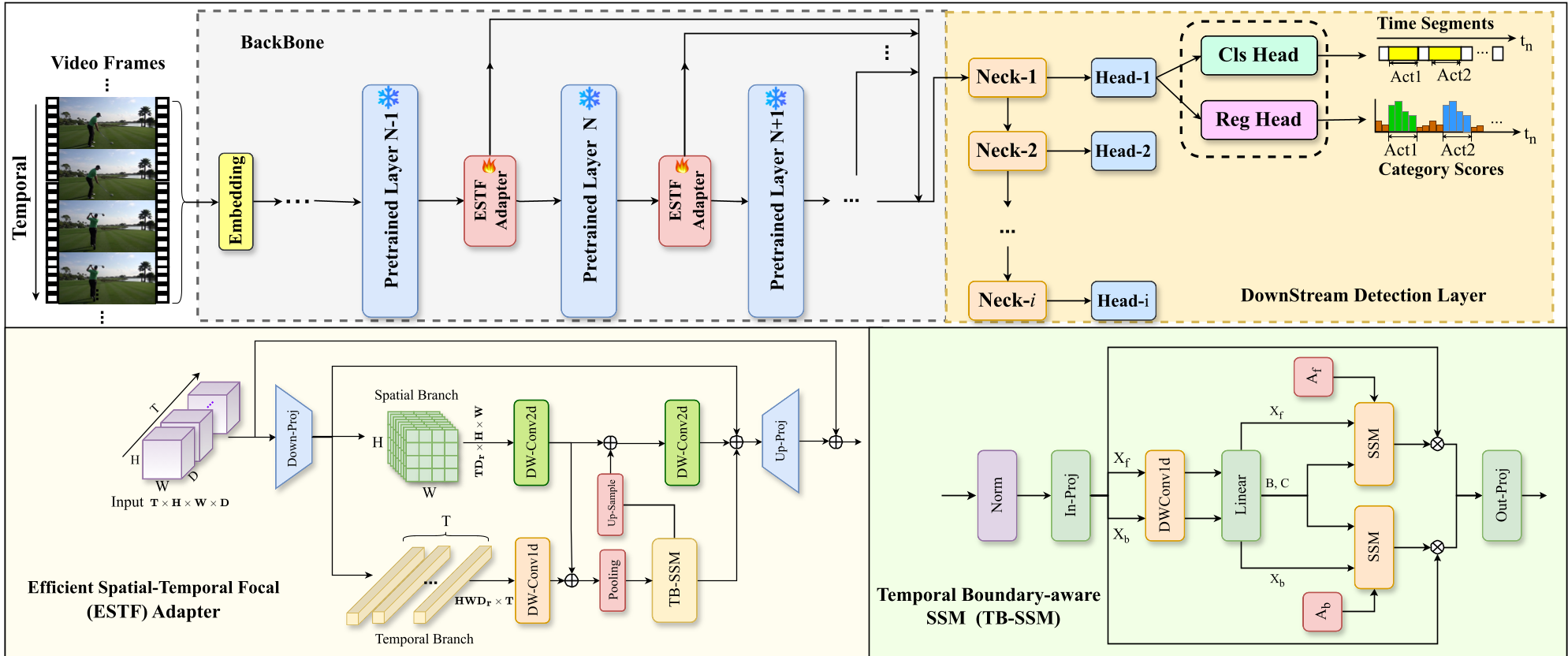
2. TB-SSM: The Power of Asymmetry
The "secret sauce" is the Temporal Boundary-aware SSM. Unlike standard bidirectional Mamba that might share parameters, TB-SSM uses independent transition matrices ( and ) for forward and backward scans.
- Why? The visual cues for an action starting (onset) are often physically and visually different from an action ending (offset). By parameterizing these directions separately, the model captures the unique "energy signatures" of action boundaries.
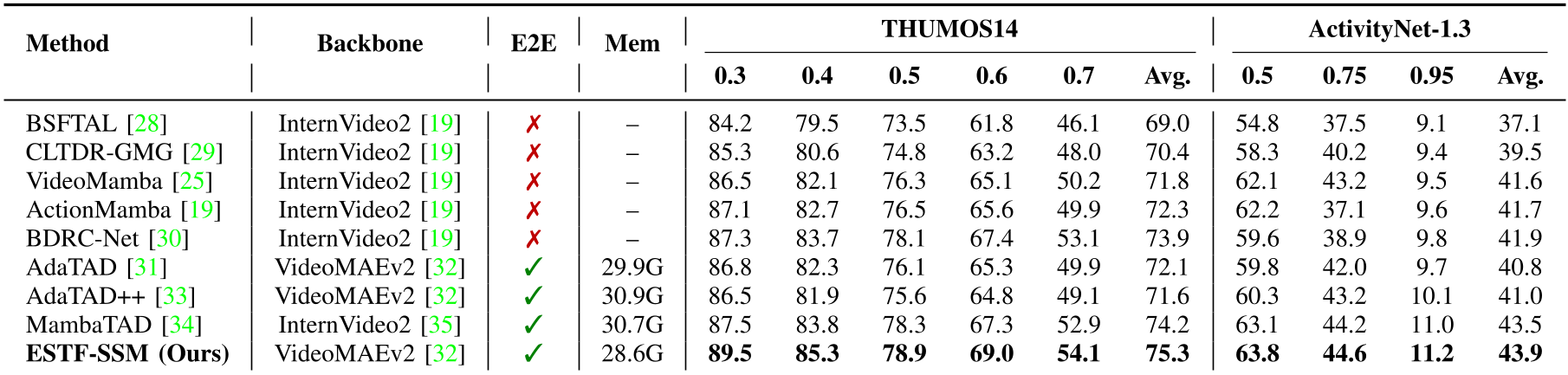
Experimental Results: Precision and Efficiency
The model was tested against heavyweights like ActionFormer and MambaTAD.
- THUMOS14 Performance: Reached 75.3% Average mAP, outperforming the previous best (MambaTAD) by 1.1%.
- Boundary Precision: The gain is most significant at high tIoU (0.7), proving that TB-SSM is significantly better at "snapping" to the correct start/end frames.
- Efficiency: Despite the performance boost, ESTF-SSM consumes less memory (28.6G) than its end-to-end competitors (typically >30G), thanks to its adapter-based design and linear SSM core.
Visualizing the Difference
Qualitative results show that while previous SOTA models might detect the general vicinity of an action, ESTF-SSM aligns its predictions almost perfectly with the Ground Truth, especially in complex indoor scenes (Charades dataset) where background clutter is high.

Conclusion & Insights
The ESTF-SSM framework proves that we don't need to choose between efficiency and precision. The key takeaway for the research community is that structural inductive biases (like asymmetric temporal scanning) still matter, even in the age of massive foundation models.
Limitations: While the model is highly efficient for offline detection, real-time "online" action detection (where future frames aren't available for backward scans) remains a direction for future work.