本文提出了 EUPE(Efficient Universal Perception Encoder),一种旨在边缘设备上实现高性能、通用视觉表征的轻量级编码器。通过“先扩容再精简”(Scaling up, then scaling down)的蒸馏策略,EUPE 在保持推理效率的同时,在图像理解、多模态语言模型(VLM)和稠密预测任务中均达到了 SOTA 或媲美领域专家的水平。
TL;DR
Meta Reality Labs 团队近期发布了 EUPE (Efficient Universal Perception Encoder)。这不仅是一个模型,更是一套成熟的预训练方案,旨在解决一个经典难题:如何让运行在端侧(如智能眼镜、手机)的微型模型,能够像云端大模型一样同时精通分类、分割、语义理解和多模态对话?EUPE 的核心直觉是:不要让小学生直接跟三个博士学习,先让一个硕士把博士的知识总结好,再教给小学生。
背景:专家很强,但“偏科”很严重
在视觉基础模型(VFM)领域,我们有擅长语义对齐的 CLIP / SigLIP,有擅长空间几何特征的 DINOv2 / v3,还有擅长分割的 SAM。
然而,当你试图在资源受限的人形机器人或智能硬件上运行这些模型时,痛点就出现了:
- 部署成本:你不可能为了处理不同任务同时挂载三个大模型。
- 性能权衡:如果只选一个(比如 CLIP),它的稠密预测(分割、深度估计)往往一塌糊涂;如果选 DINO,它又看不懂文字。
- 蒸馏瓶颈:以往的方法(如 RADIO)尝试直接将多个教师蒸馏给小模型,但小模型的容量(Capacity)太低,无法同时吸收复杂的、相互冲突的特征空间,导致“样样通,样样松”。
核心方法:先扩容,再精简 (Scaling Up, then Scaling Down)
EUPE 提出了一种极其克制但有效的“三阶段”蒸馏管线,其关键在于引入一个代理教师 (Proxy Teacher)。
1. 代理教师:知识的熔炉
作者首先将 PEcore(分类专家)、PElang(多模态专家)和 DINOv3(稠密感知专家)的知识全部蒸馏到一个 1.9B 的大模型中。这个大模型有足够的容量去对齐这三种完全不同的表征,形成一套“通用语言”。
2. 从代理到学生的平稳过渡
有了统一的代理教师后,再将其蒸馏给最终的轻量级学生(如 ViT-B, ConvNext-T)。因为此时学生只需要对齐一个老师,学习难度大幅降低。
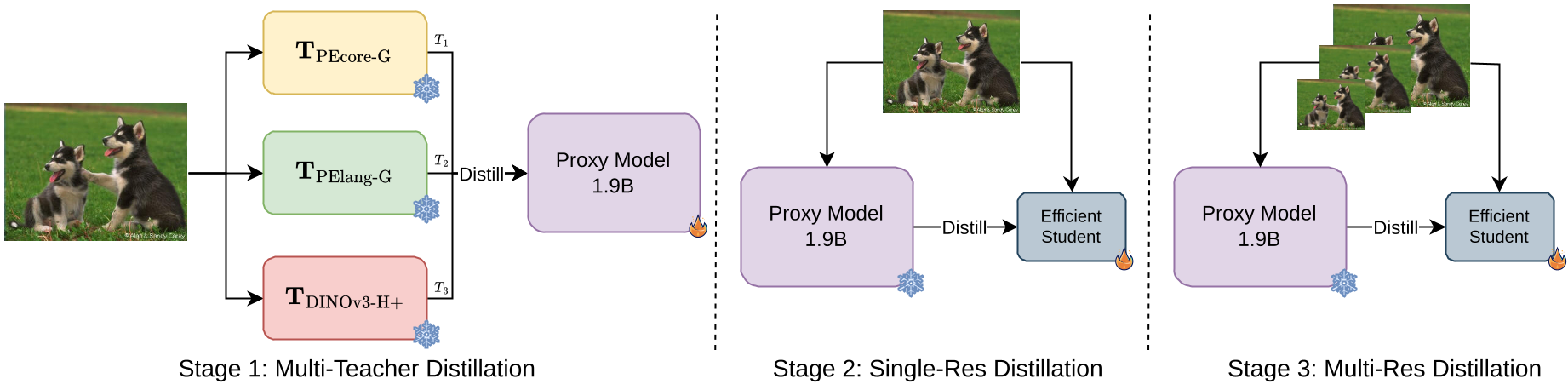
3. 多分辨率的“最后冲刺”
为了让模型在不同输入尺寸下都能保持鲁棒性(尤其是这对分割和 OCR 任务至关重要),最后阶段通过多尺度(256到512)的随机图像金字塔进行微调。
实验结果:真正的“六边形战士”
在实验中,EUPE-ViT-B 展现出了令人惊叹的均衡性:
- 语义对齐:ImageNet 零样本分类达到 79.7%,超过了原始专家模型。
- 稠密预测:在 ADE20k 分割任务上达到 52.4 mIoU,不仅远超 CLIP,甚至微弱领先于专门为此优化的 DINOv3-ViT-B。
- 多模态理解:在 RealworldQA 和 GQA 等测试中,由于 PElang 知识的注入,其表现显著优于其他集成模型。
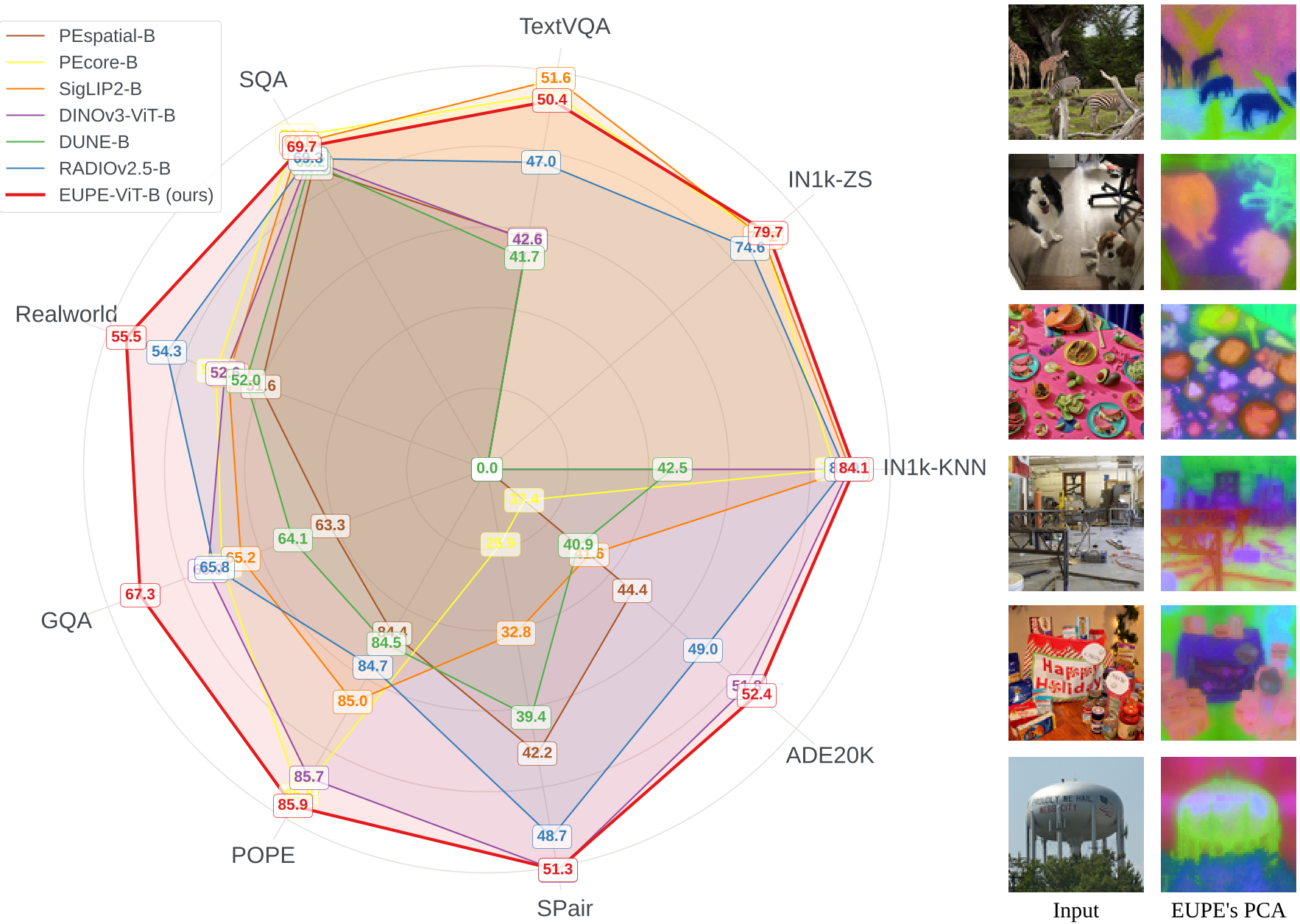
视觉直觉:特征空间到底发生了什么?
通过 PCA 投影(如下图),我们可以清晰看到:
- CLIP 式模型:特征图噪音多,缺乏空间一致性。
- DINO 式模型:特征图很平滑,但对细分语义(比如盘子里的食物)不敏感。
- EUPE:实现了“鱼与熊掌兼得”——既有清晰的边缘纹理,又有极强的语义区分度。

深度洞察与总结
为什么这篇论文值得关注?
- 它务实地解决了“端侧”痛点:很多学术工作追求的是 10B 以上模型的上限,而 EUPE 关注的是 100M 以下模型的实用性。
- 提出了“统一表征”的可行路径:它证明了多任务通用的特征空间确实存在,只是需要一个足够强的中间人(Proxy Teacher)来协助寻找。
- ConvNext 的回归:实验显示在不同分辨率下,ConvNext 系列在端侧延迟上依然非常有竞争力,这为喜欢 CNN 架构的开发者提供了信心。
局限性: 从 7B 代理教师蒸馏到 86M 学生时,性能出现了衰减(Gap 增大)。这说明当师生差距过大时,即使有统一的表征,简单的蒸馏损失函数也难以支撑知识的完美传递。
未来展望: 随着智能眼镜等可穿戴设备的爆发,这种“万能骨干网”将成为标配。EUPE 的代码和模型权重的开源,无疑将加速这一进程。