本文推出了 EgoTL,一个包含 400 个视频序列、覆盖 100 多种家务任务的长程第一视角(Egocentric)多模态数据集。核心贡献是提出了“言行同步”(Say-Before-Act)协议,通过人类实时的“大声思考”(Think-Aloud)形成逻辑链,并结合 3D 尺度校准,显著提升了具身智能模型在长程任务中的规划与空间感知能力。
TL;DR
在具身智能领域,让 AI 像人一样在复杂家庭环境中完成长程任务(如“从厨房拿牛奶放进卧室并避开障碍”)一直是个难题。本文提出的 EgoTL 放弃了传统的“看图说话式”标注,采用了 Say-Before-Act(言行同步) 协议,强制捕捉人类在行动前的推理直觉。通过这种方式,AI 不仅学会了“做什么”,更学会了“为什么要这么做”。
1. 痛点深挖:为什么 AI 总是“想当然”?
目前的 VLM(视觉语言模型)在处理短视频剪辑时表现优异,但在面对长达数分钟的家庭任务时却频频翻车。作者指出,核心矛盾在于数据标注的滞后性:
- 自动标注的噪声:现有的自动流水线生成的时间戳往往偏差巨大。
- 事后标注的“幸存者偏差”:人类在事后再去描述视频时,往往会忽略掉行动前的思考过程(例如:因为椅子挡路了,所以我先搬开椅子)。这导致 AI 无法理解因果逻辑,从而在实际执行中产生跳步或对物体的幻觉。
2. 核心机制:EgoTL 的“言行同步”协议
EgoTL 的核心创新在于它不只是一个视频库,而是一个意图捕获引擎。
A. Say-Before-Act 协议
研究人员要求受试者一边戴着 Aria 眼镜工作,一边“大声思考”。在每一个动作执行前,必须先口述意图:
“我本想直接过去,但椅子挡住了路,所以我先挪开椅子。”
这种数据提供了极佳的 Chain-of-Thought (CoT) 原型,让模型能学习到复杂的规划逻辑。
B. 3D 空间校准与记忆库
为了解决 VLM 对物理距离“没概念”的问题,EgoTL 使用了 MapAnything 等工具进行度量尺度的 3D 重构,为每个动作贴上了精确到米的航位推算和转向标签。此外,还专门拍摄了 Memory-bank 视频,让 AI 在规划前先“扫描”一遍全屋的布局。
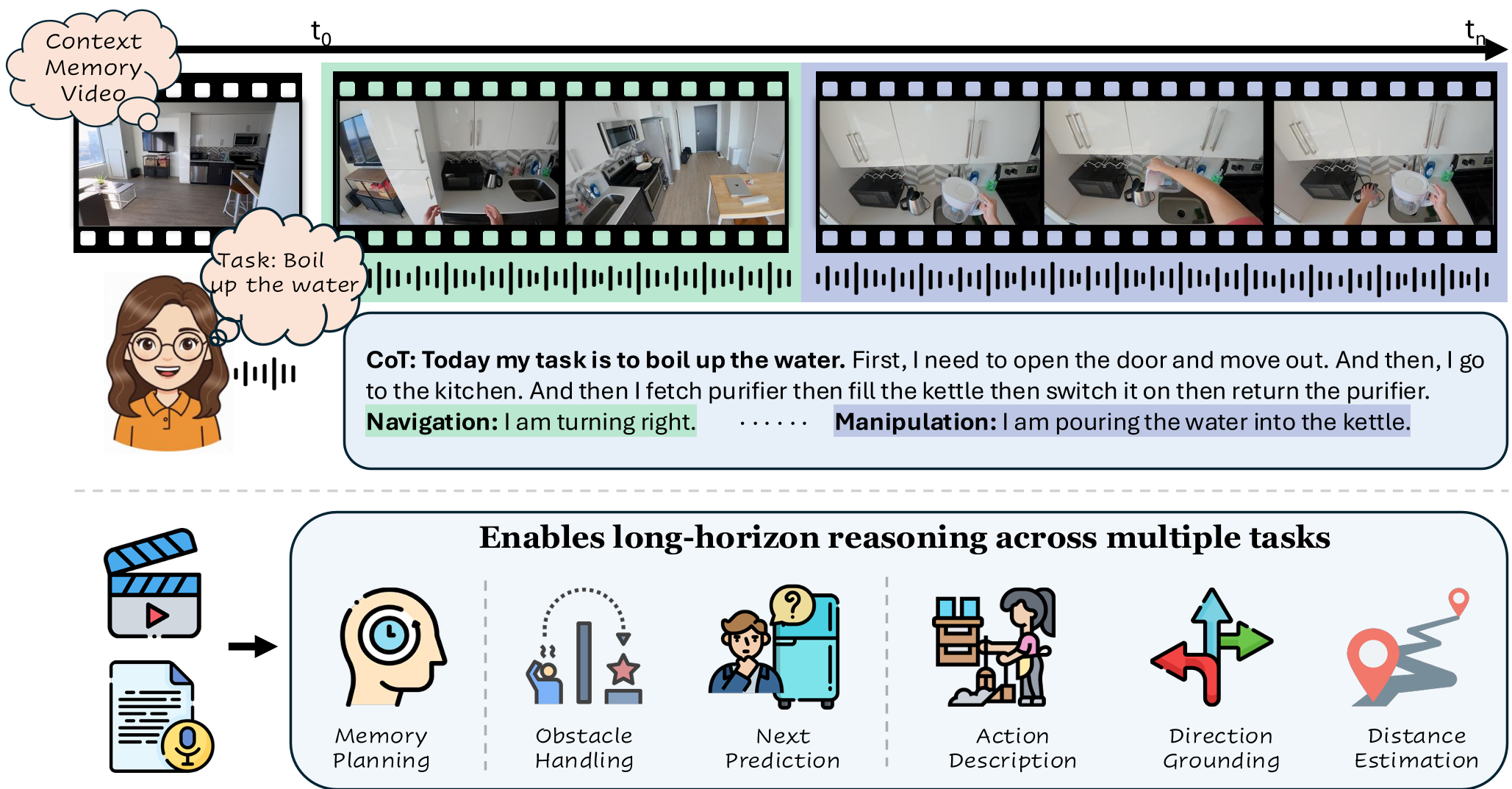 图 1:EgoTL 数据捕获流程,涵盖抽象目标、思维链以及显式的导航/操控步骤。
图 1:EgoTL 数据捕获流程,涵盖抽象目标、思维链以及显式的导航/操控步骤。
3. 实验对比:强如 GPT-5 也有短板
论文构建了 EgoTL-Bench,从 3 个层级(规划层、推理层、感知层)对六大维度进行评测。
核心发现:
- 闭源模型依然领先:在长程任务规划上,GPT-5 和 Gemini 2.5 仍然优于开源模型,说明大参数量对逻辑理解有帮助。
- 空间感知是通病:几乎所有预训练模型在距离估计(Distance Estimation)上都表现极差,模型往往分不清走 1 米和走 5 米的区别。
- 微调的惊人效果:通过在 EgoTL 上对 Qwen2.5-VL 进行 LoRA 微调,距离估计的准确率实现了翻倍提升(如表 3 所示)。
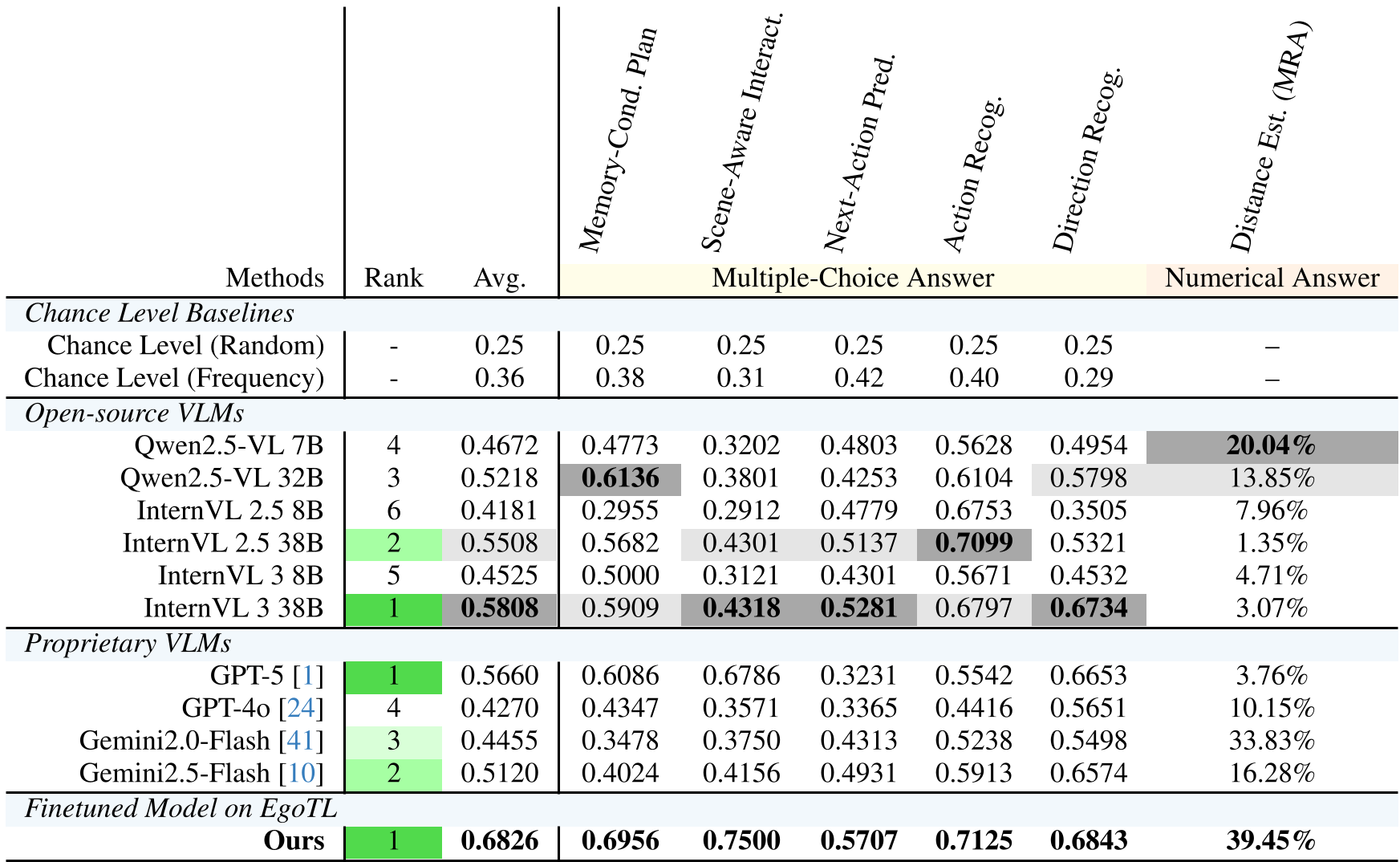 表 3:不同模型在 EgoTL-Bench 上的战绩,微调后的模型在多项指标上刷高了 SOTA。
表 3:不同模型在 EgoTL-Bench 上的战绩,微调后的模型在多项指标上刷高了 SOTA。
4. 深度洞察:具身智能的未来在“意图”
EgoTL 的成功给了我们一个启示:视频本身是不够的,音频中的推理逻辑才是灵魂。
- 物理一致性:通过将人类语言中的方向指令(如“向右转”)与 3D 传感器的真实数据对齐,模型第一次在第一视角下建立起了真实的距离感。
- 世界模型(World Models)的提升:作者还微调了 COSMOS 等世界模型,发现有了 EgoTL 的指导,生成的视频序列在物体一致性(Object Persistence)上表现更好。
5. 局限性与展望
尽管 EgoTL 取得了显著提升,但距离人类水平仍有较大差距(Gap)。目前的模型在处理极其复杂的动态遮挡(如猫突然跳出来)或非常细微的手部操控时仍显吃力。未来的研究方向可能在于如何将这种“大声思考”的模式大规模自动化,而不仅仅依赖于人工采集。
总结:EgoTL 为具身智能提供了一套高质量、带物理刻度的逻辑教案。它告诉我们,要让 AI 像人一样干活,先得让它像人一样“边做边想”。