EgoForge is a goal-directed egocentric world simulator that generates coherent first-person video rollouts from a single static image and a high-level instruction. It utilizes a Diffusion Transformer backbone enhanced by geometry-level grounding and a novel trajectory-level refinement mechanism called VideoDiffusionNFT to achieve SOTA performance in egocentric video synthesis.
TL;DR
EgoForge is a groundbreaking egocentric world simulator that can generate a full, physically plausible first-person video rollout from just a single image and a textual instruction (e.g., "open the fridge and pour milk"). By combining geometry-aware diffusion with a novel trajectory-level alignment policy (VideoDiffusionNFT), it solves the persistent problem of "goal drift" in video generation, outperforming the latest foundation models like Cosmos and WAN2.2 in temporal stability and intent alignment.
The Challenge: Why First-Person Simulation is Hard
Simulating a "world" through a human's eyes is significantly more complex than standard video generation (like Sora or Runway). In egocentric vision, we face:
- Rapid Viewpoint Changes: The camera moves with the head, creating complex motion blur and perspective shifts.
- Hand-Object Interactions: Frequent occlusions and fine-grained manipulations require high spatial precision.
- Latent Intent: The evolution of the scene depends entirely on what the human intends to do next—a factor static models often ignore.
Prior works usually relied on "crutches" like dense camera trajectories, long video prefixes, or synchronized multi-camera setups. EgoForge breaks this dependency.
Methodology: The Core Innovations
1. Geometry-Aware Denoising
To prevent the scene from "melting" or warping during motion, EgoForge uses Geometry Weak Supervision. It aligns the internal representations of the Diffusion Transformer (DiT) with a pretrained Visual Geometry Grounded Transformer (VGGT). This forces the model to maintain a consistent "mental map" of the 3D space even as the viewpoint shifts.
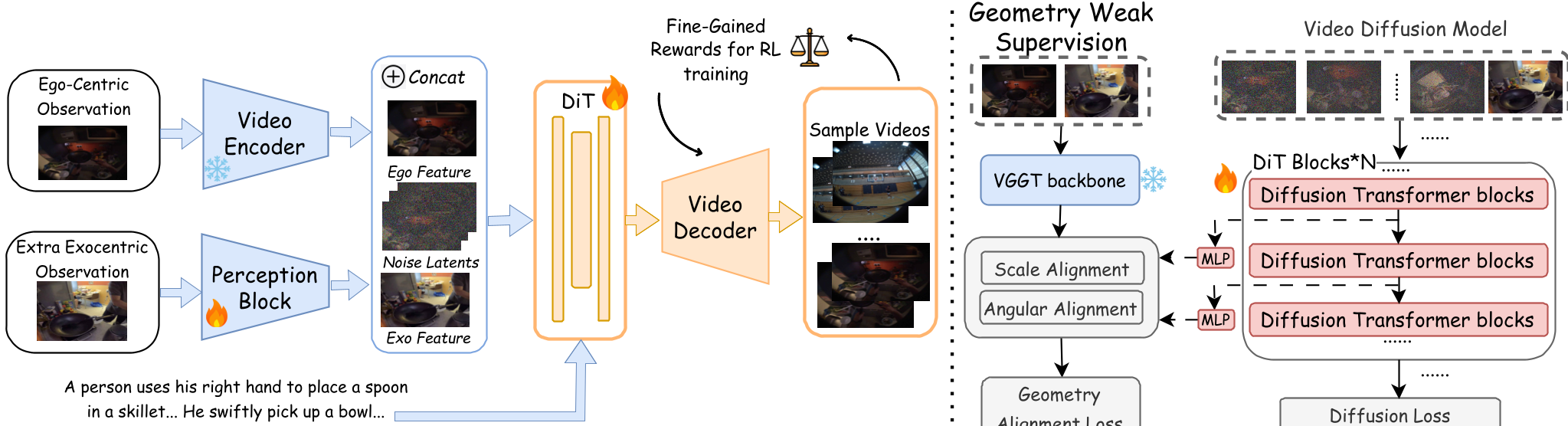
2. VideoDiffusionNFT: Trajectory-Level Alignment
This is the "secret sauce." Standard diffusion models optimize for frame-by-frame visual realism, but they often "forget" the goal halfway through the video. The authors propose VideoDiffusionNFT, which treats the entire video rollout as a trajectory in a Reinforcement Learning (RL) framework. It uses four specific reward functions:
- Goal Completion: Did you actually pour the milk?
- Scene Consistency: Did the kitchen turn into a forest by frame 100?
- Temporal Causality: Do the movements follow the laws of physics?
- Perceptual Fidelity: Is the video sharp and artifact-free?
By steering the sampling process toward high-reward trajectories, EgoForge ensures that the generated video remains faithful to the user's instruction from start to finish.
Experimental Results: Setting a New SOTA
The authors curated X-Ego, a massive benchmark for goal-directed egocentric tasks. The results show that EgoForge isn't just slightly better—it redefines the baseline:
| Metric | Gain vs. Best Baseline | Significance | | :--- | :--- | :--- | | DINO-Score | +13.5% | Better semantic alignment | | FVD | -43% | Much higher realism | | Flow MSE | -51% | Smoother, more stable motion |
Qualitative Superiority
In complex tasks like soccer (tripping the ball with the left leg, shooting with the right), baselines like Cosmos or HunyuanVideo often hallucinate "ghost hands" or fail to follow the multi-step instruction. EgoForge maintains object permanence and executes the command with high fidelity.

Real-World Impact: Smart-Glasses Deployment
Beyond benchmarks, the team tested EgoForge using DigiLens ARGO smart-glasses. A user can look at an object, give a voice command, and the simulator accurately predicts the visual outcome. This has massive implications for Extended Reality (XR), where AI can "rehearse" or "preview" actions for users in real-time.

Critical Analysis & Conclusion
Takeaway: EgoForge effectively proves that for world models to be useful, they must move beyond "visual mimicry" and toward "intentional simulation." The introduction of trajectory-level rewards (VideoDiffusionNFT) is a major step toward building AI that understands why things move, not just how they look.
Limitations: While impressive, the model still requires significant compute (8x H100 GPUs) for training, and "minimal-input" generation still struggles with highly cluttered or novel environments where 3D priors might fail.
Future Work: We expect this "Simulation-via-Alignment" approach to be applied to robotics and autonomous agents, where the ability to "dream" a physically consistent future is the key to safe decision-making.